Based on the technical report released by DeepSeek, this article interprets the training process of DeepSeek - R1.
Author: Jiang Xinling, Powered by AI

Image source: Generated by Boundless AI
How does DeepSeek train its R1 reasoning model?
This article mainly interprets the training process of DeepSeek - R1 based on the technical report released by DeepSeek; it focuses on four strategies for building and enhancing reasoning models.
The original text is from researcher Sebastian Raschka, published at:
https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
This article will summarize the core training part of the R1 reasoning model.
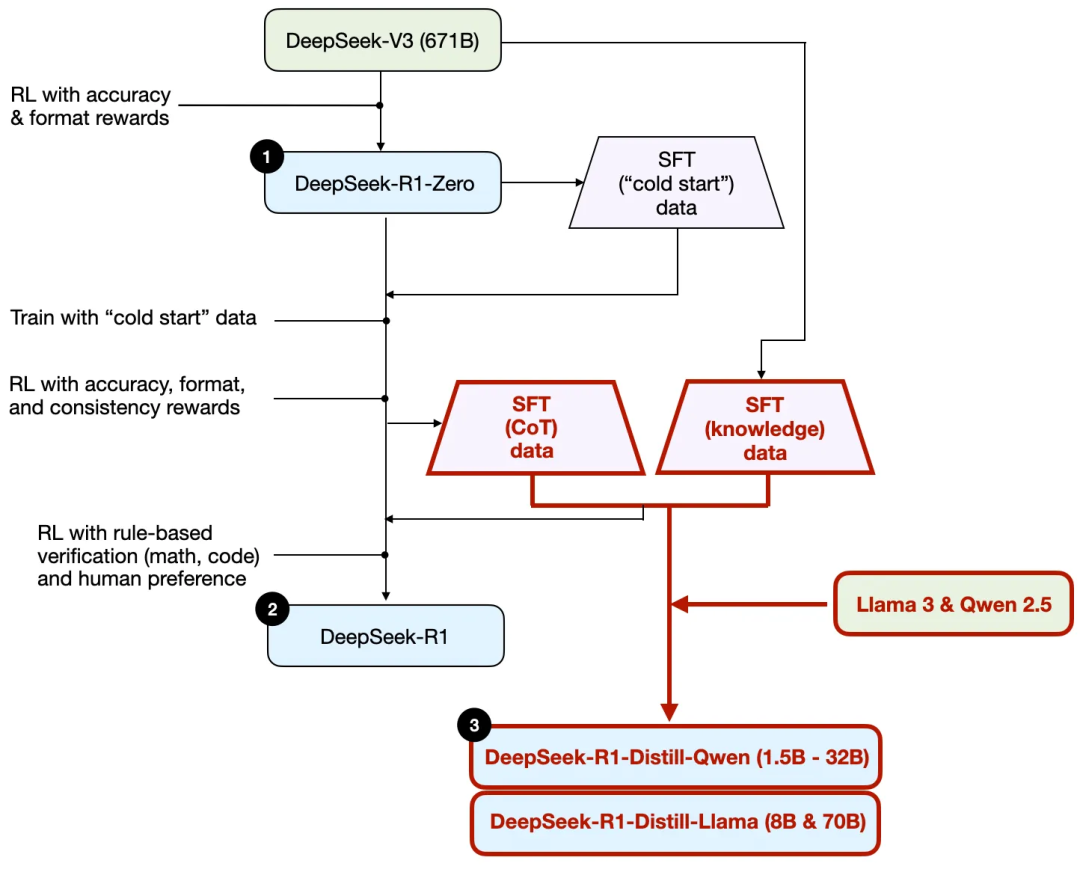
First, based on the technical report released by DeepSeek, here is a training diagram of R1.
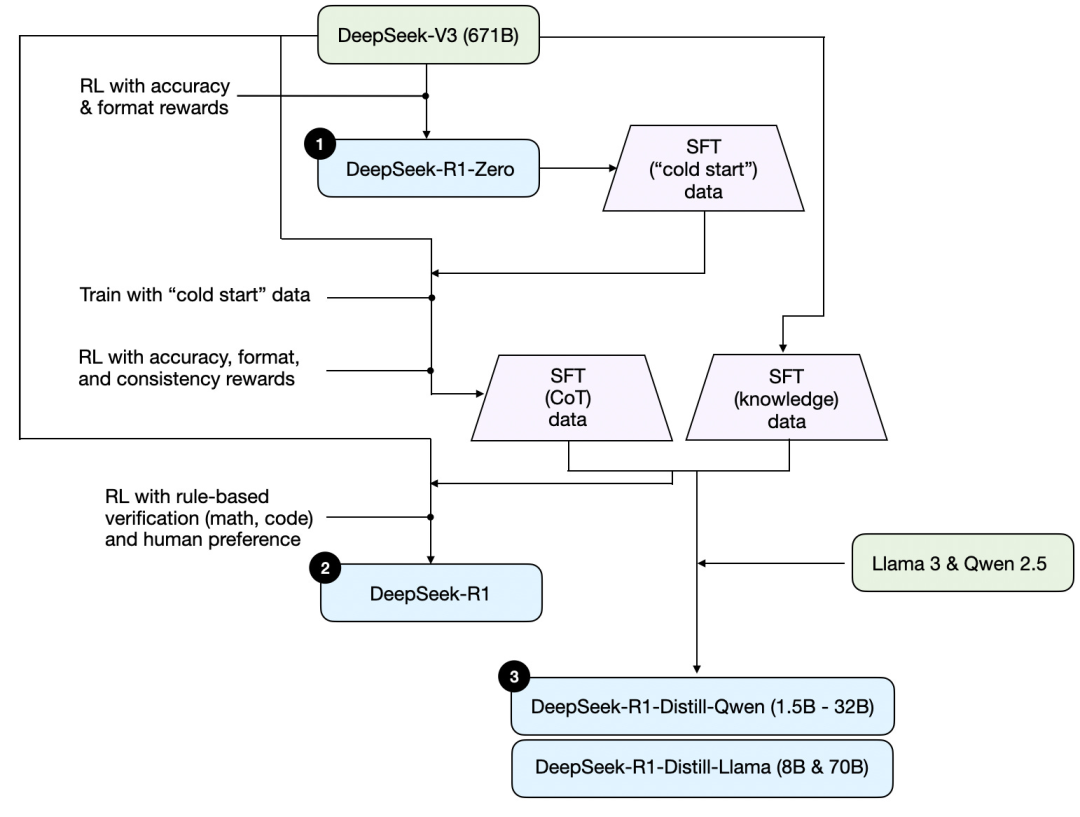
Let's outline the process shown in the diagram, where:
(1) DeepSeek - R1 - Zero: This model is based on the DeepSeek - V3 base model released last December. It is trained using reinforcement learning (RL) with two reward mechanisms. This method is referred to as "cold start" training because it does not include a supervised fine-tuning (SFT) step, which is typically part of human feedback reinforcement learning (RLHF).
(2) DeepSeek - R1: This is DeepSeek's flagship reasoning model, built on DeepSeek - R1 - Zero. The team optimized it through an additional supervised fine-tuning phase and further reinforcement learning training, improving the "cold start" R1 - Zero model.
(3) DeepSeek - R1 - Distill: The DeepSeek team fine-tuned the Qwen and Llama models using the supervised fine-tuning data generated in the previous steps to enhance their reasoning capabilities. Although this is not traditional distillation, the process involves training smaller models (Llama 8B and 70B, as well as Qwen 1.5B - 30B) using the outputs of the larger 671B DeepSeek - R1 model.
The following will introduce four main methods for building and enhancing reasoning models.
1. Inference-time scaling
One way to enhance the reasoning ability of LLMs (or any capability in general) is through inference-time scaling—adding computational resources during the inference process to improve output quality.
A rough analogy is that people often provide better answers when they have more time to think about complex problems. Similarly, we can employ certain techniques to encourage LLMs to "think" more deeply when generating answers.
A simple way to achieve inference-time scaling is through clever prompt engineering. A classic example is chain-of-thought prompting (CoT Prompting), which involves adding phrases like "think step by step" to the input prompt. This encourages the model to generate intermediate reasoning steps rather than jumping directly to the final answer, often leading to more accurate results on more complex questions. (Note that for simpler knowledge-based questions like "What is the capital of France?", using this strategy is not meaningful, which is a practical rule of thumb for determining whether a reasoning model is applicable to a given input query.)

The above chain-of-thought (CoT) method can be seen as inference-time scaling because it increases the reasoning cost by generating more output tokens.
Another method of inference-time scaling is to use voting and search strategies. A simple example is majority voting, where the LLM generates multiple answers and the correct one is selected through majority vote. Similarly, we can use beam search and other search algorithms to generate better answers.
Here, I recommend the paper "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters."
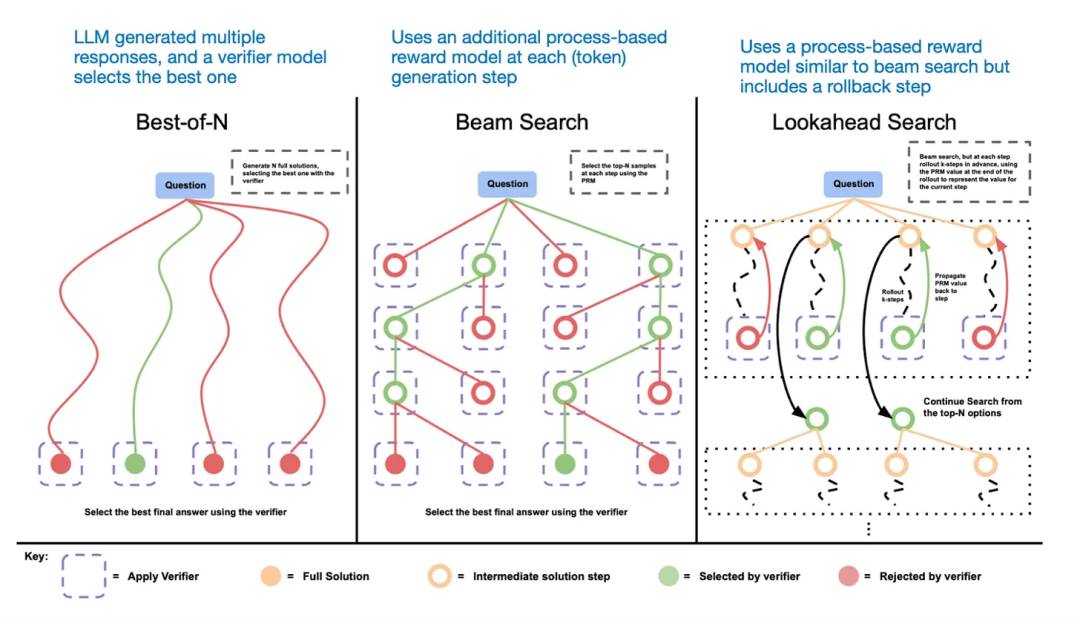
Different search-based methods rely on process-reward-based models to select the best answer.
The DeepSeek R1 technical report states that its model does not employ inference-time scaling techniques. However, this technique is typically implemented at the application layer above LLMs, so it is possible that DeepSeek has utilized this technique in its applications.
I speculate that OpenAI's o1 and o3 models employ inference-time scaling techniques, which could explain why their usage costs are relatively high compared to models like GPT-4o. Besides inference-time scaling, o1 and o3 are likely trained through reinforcement learning processes similar to DeepSeek R1.
2. Pure RL
A particularly noteworthy point in the DeepSeek R1 paper is their discovery that reasoning can emerge as a behavior from pure reinforcement learning. Let's explore what this means.
As mentioned earlier, DeepSeek developed three R1 models. The first is DeepSeek - R1 - Zero, which is built on the DeepSeek - V3 base model. Unlike typical reinforcement learning processes, which usually involve supervised fine-tuning (SFT) before reinforcement learning, DeepSeek - R1 - Zero is entirely trained through reinforcement learning without an initial supervised fine-tuning/SFT phase, as shown in the diagram below.
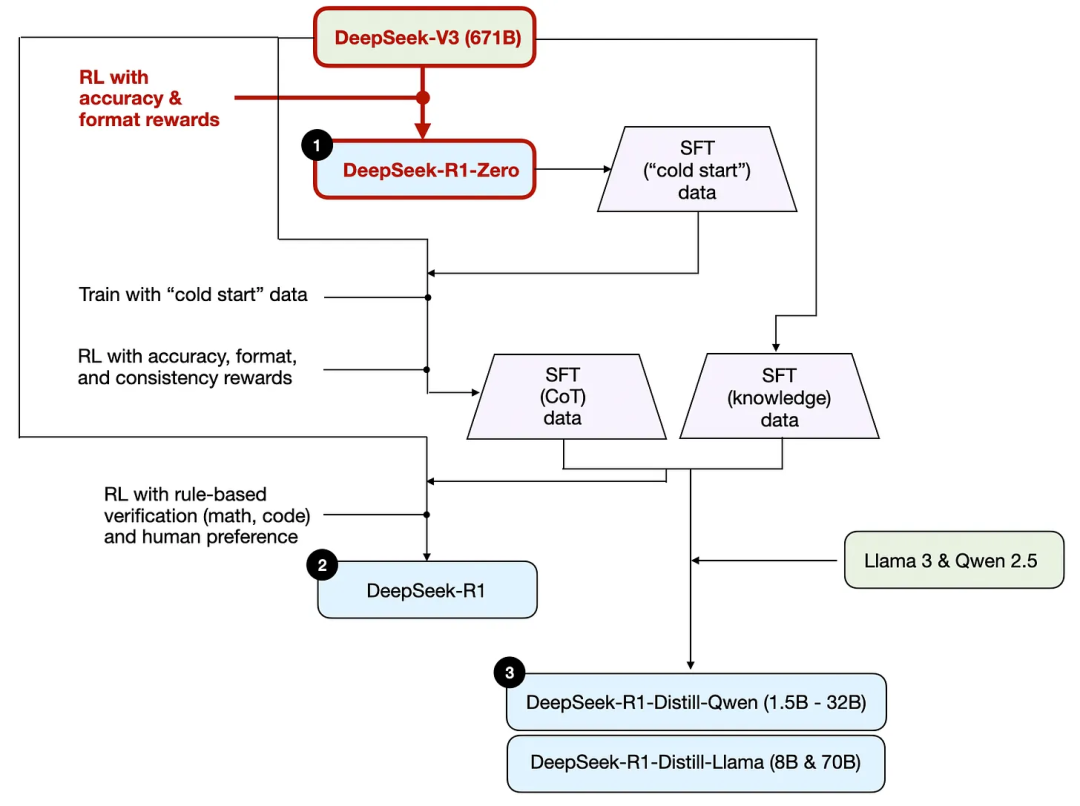
Nevertheless, this reinforcement learning process is similar to the human feedback reinforcement learning (RLHF) methods commonly used for preference fine-tuning of LLMs. However, as mentioned above, the key difference with DeepSeek - R1 - Zero is that they skipped the supervised fine-tuning (SFT) phase used for instruction tuning. This is why they refer to it as "pure" reinforcement learning / Pure RL.
In terms of rewards, they did not use a reward model trained on human preferences but instead employed two types of rewards: accuracy reward and format reward.
Accuracy reward uses a LeetCode compiler to verify programming answers and employs a deterministic system to evaluate mathematical answers.
Format reward relies on an LLM judge to ensure that answers follow the expected format, such as placing reasoning steps within tags.
Surprisingly, this method is sufficient for the LLM to evolve basic reasoning skills. Researchers observed an "aha moment" when the model began generating traces of reasoning in its answers, even though it had not been explicitly trained on it, as shown in the diagram from the R1 technical report.

Although R1 - Zero is not the top reasoning model, as shown in the diagram, it does exhibit reasoning ability by generating intermediate "thinking" steps. This confirms that developing reasoning models using pure reinforcement learning is feasible, and DeepSeek is the first team to demonstrate (or at least publish results on) this method.
3. Supervised Fine-tuning and Reinforcement Learning (SFT + RL)
Next, let's look at the development process of DeepSeek's flagship reasoning model, DeepSeek - R1, which can be considered a textbook case for building reasoning models. This model incorporates more supervised fine-tuning (SFT) and reinforcement learning (RL) on top of DeepSeek - R1 - Zero to enhance its reasoning performance.
It is important to note that adding a supervised fine-tuning phase before reinforcement learning is common in standard human feedback reinforcement learning (RLHF) processes. OpenAI's o1 was likely developed using a similar approach.
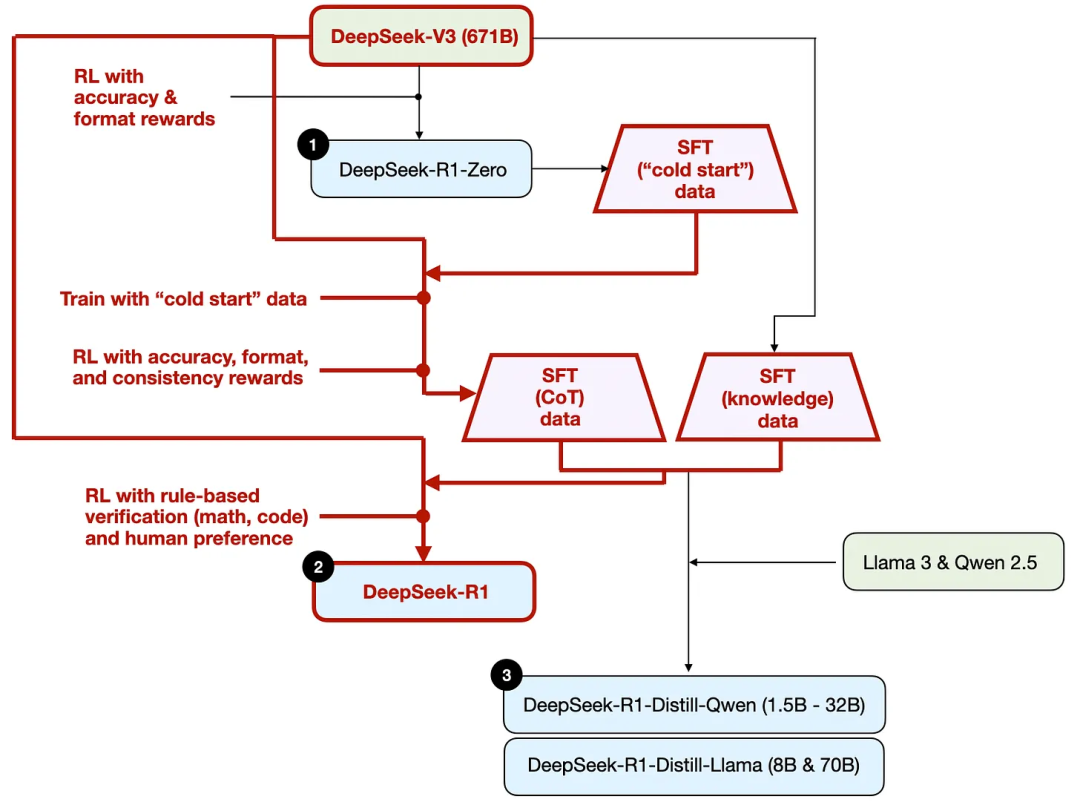
As shown in the diagram, the DeepSeek team generated what they call "cold start" supervised fine-tuning (SFT) data using DeepSeek - R1 - Zero. The term "cold start" means that this data was generated by DeepSeek - R1 - Zero, which itself was not trained on any supervised fine-tuning data.
Using this cold start SFT data, DeepSeek first trained the model through instruction fine-tuning, followed by another reinforcement learning (RL) phase. This RL phase continued to use the accuracy reward and format reward from the RL process of DeepSeek - R1 - Zero. However, they added a consistency reward to prevent the model from mixing languages in its answers, meaning the model would switch between multiple languages in a single response.
After the RL phase, another round of SFT data collection took place. In this phase, 600,000 chain-of-thought (CoT) SFT examples were generated using the latest model checkpoint, while an additional 200,000 knowledge-based SFT examples were created using the DeepSeek - V3 base model.
Then, these 600,000 + 200,000 SFT samples were used for instruction fine-tuning of the DeepSeek - V3 base model, followed by a final round of RL. In this phase, for mathematical and programming problems, they again used a rule-based approach to determine the accuracy reward, while for other types of questions, human preference labels were used. In summary, this is very similar to conventional human feedback reinforcement learning (RLHF), except that the SFT data includes (more) chain-of-thought examples. Additionally, the RL phase includes verifiable rewards in addition to human preference-based rewards.
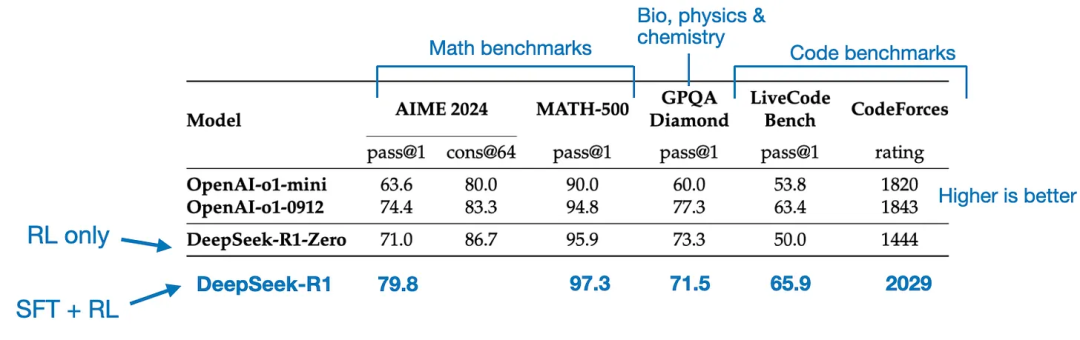
The final model, DeepSeek - R1, shows significant performance improvements over DeepSeek - R1 - Zero due to the additional SFT and RL phases, as shown in the table below.
4. Pure Supervised Fine-tuning (SFT) and Distillation
So far, we have introduced three key methods for building and improving reasoning models:
Inference-time scaling, a technique that enhances reasoning ability without requiring training or other modifications to the underlying model.
Pure RL, as employed in DeepSeek - R1 - Zero, which indicates that reasoning can emerge as a learned behavior without supervised fine-tuning.
Supervised fine-tuning (SFT) + Reinforcement Learning (RL), which resulted in DeepSeek's reasoning model, DeepSeek - R1.
What remains is model "distillation." DeepSeek has also released smaller models trained through their so-called distillation process. In the context of LLMs, distillation does not necessarily follow the classical knowledge distillation methods used in deep learning. Traditionally, in knowledge distillation, a smaller "student" model is trained on the logical outputs of a larger "teacher" model along with a target dataset.
However, here, distillation refers to instruction fine-tuning of smaller LLMs, such as Llama 8B and 70B models, as well as Qwen 2.5B (0.5B - 32B), on a supervised fine-tuning (SFT) dataset generated by larger LLMs. Specifically, these larger LLMs are intermediate checkpoints of DeepSeek - V3 and DeepSeek - R1. In fact, the supervised fine-tuning data used for this distillation process is the same as the dataset described in the previous section for training DeepSeek - R1.
To clarify this process, I have highlighted the distillation part in the diagram below.
Why did they develop these distilled models? There are two key reasons:
Smaller models are more efficient. This means they have lower operational costs and can run on lower-end hardware, which is particularly attractive to many researchers and enthusiasts.
As a case study of pure supervised fine-tuning (SFT). These distilled models serve as an interesting benchmark, demonstrating how far pure supervised fine-tuning can take a model without reinforcement learning.
The table below compares the performance of these distilled models with other popular models, as well as DeepSeek - R1 - Zero and DeepSeek - R1.
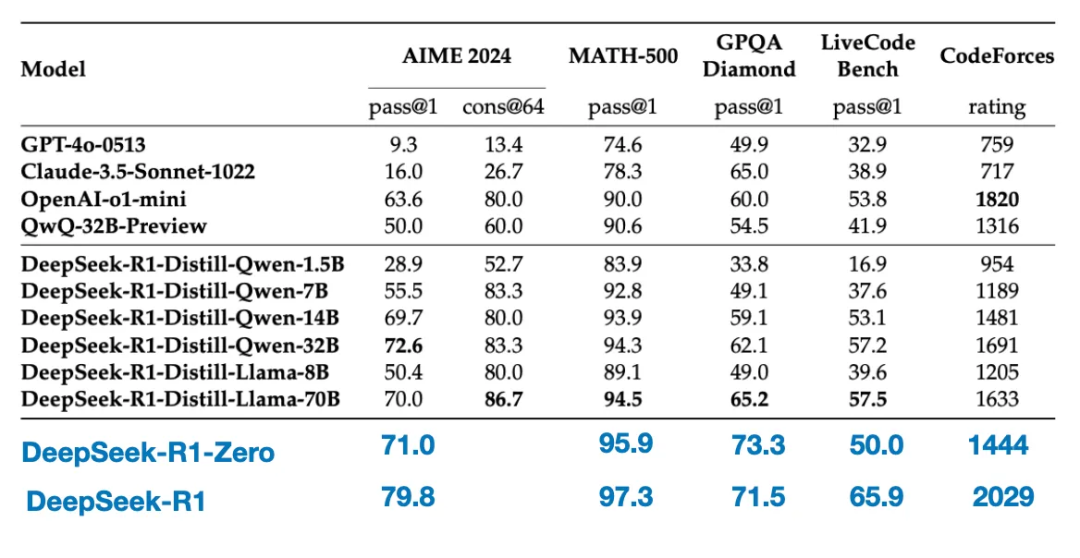
As we can see, although the distilled models are several orders of magnitude smaller than DeepSeek - R1, they are significantly more powerful than DeepSeek - R1 - Zero, though still weaker compared to DeepSeek - R1. Interestingly, these models also perform well compared to o1 - mini (suspecting that o1 - mini itself may be a similar distilled version of o1).
Another interesting comparison is worth mentioning. The DeepSeek team tested whether the emergent reasoning behavior observed in DeepSeek - R1 - Zero could also appear in smaller models. To investigate this, they directly applied the same pure reinforcement learning method from DeepSeek - R1 - Zero to Qwen - 32B.
The table below summarizes the results of this experiment, where QwQ - 32B - Preview is a reference reasoning model based on the Qwen team’s Qwen 2.5 32B. This comparison provides additional insights into whether pure reinforcement learning can induce reasoning capabilities in models that are much smaller than DeepSeek - R1 - Zero.
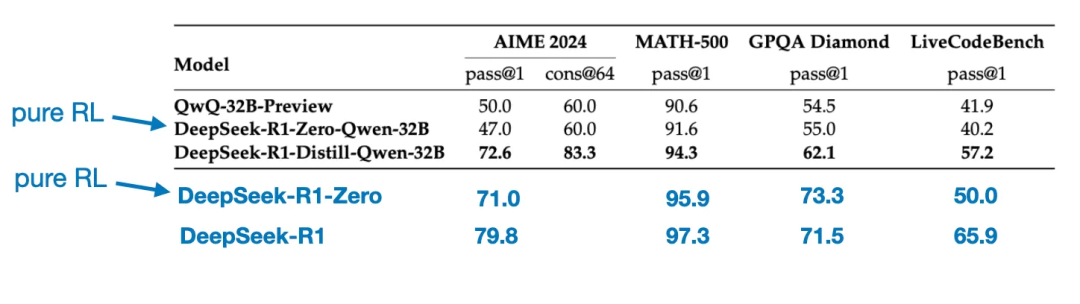
Interestingly, the results indicate that for smaller models, distillation is much more effective than pure reinforcement learning. This aligns with the view that relying solely on reinforcement learning may not be sufficient to induce strong reasoning capabilities in models of this scale, and that supervised fine-tuning based on high-quality reasoning data may be a more effective strategy when dealing with smaller models.
Conclusion
We explored four different strategies for building and enhancing reasoning models:
Inference-time scaling: This does not require additional training but increases reasoning costs. As the number of users or queries grows, the costs of large-scale deployment will be higher. However, it remains a simple and effective method for enhancing the performance of existing powerful models. I strongly suspect that o1 employs inference-time scaling, which also explains why the cost per token generated by o1 is higher compared to DeepSeek - R1.
Pure Reinforcement Learning (Pure RL): This is interesting from a research perspective because it allows us to delve into the process of reasoning as an emergent behavior. However, in practical model development, combining reinforcement learning with supervised fine-tuning (RL + SFT) is the superior choice, as this approach can build stronger reasoning models. I also strongly suspect that o1 was trained using RL + SFT. More specifically, I believe o1 started with a weaker, smaller base model than DeepSeek - R1 but closed the gap through RL + SFT and inference-time scaling.
As mentioned above, RL + SFT is a key method for building high-performance reasoning models. DeepSeek - R1 provides us with an excellent blueprint for achieving this goal.
Distillation: This is an attractive method, especially for creating smaller, more efficient models. However, its limitation is that distillation cannot drive innovation or produce the next generation of reasoning models. For example, distillation always relies on existing stronger models to generate supervised fine-tuning (SFT) data.
Next, I look forward to an interesting direction that combines RL + SFT (method 3) with inference-time scaling (method 1). This is likely what OpenAI's o1 is doing, except that o1 may be based on a weaker base model than DeepSeek - R1, which also explains why DeepSeek - R1 performs excellently in reasoning while maintaining relatively low costs.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







