Did Grok3 really consume 263 times the computing power of DeepSeek V3, just for this?
On February 18, Beijing time, Musk and the xAI team officially released the latest version of Grok, Grok3, during a live broadcast.
Even before this release, the anticipation for Grok3 had reached unprecedented levels due to various related information being leaked and Musk's continuous hype 24/7. A week prior, during a live stream commenting on DeepSeek R1, Musk confidently stated, "xAI is about to launch a better AI model."
From the data presented at the event, Grok3 has surpassed all current mainstream models in benchmarks for mathematics, science, and programming. Musk even claimed that Grok3 would be used for calculations in SpaceX's Mars missions and predicted "Nobel Prize-level breakthroughs within three years."
However, these claims are currently just Musk's words. After the release, I tested the latest beta version of Grok3 and posed the classic question used to challenge large models: "Which is larger, 9.11 or 9.9?"
Unfortunately, without any qualifiers or annotations, the so-called smartest Grok3 still could not correctly answer this question.
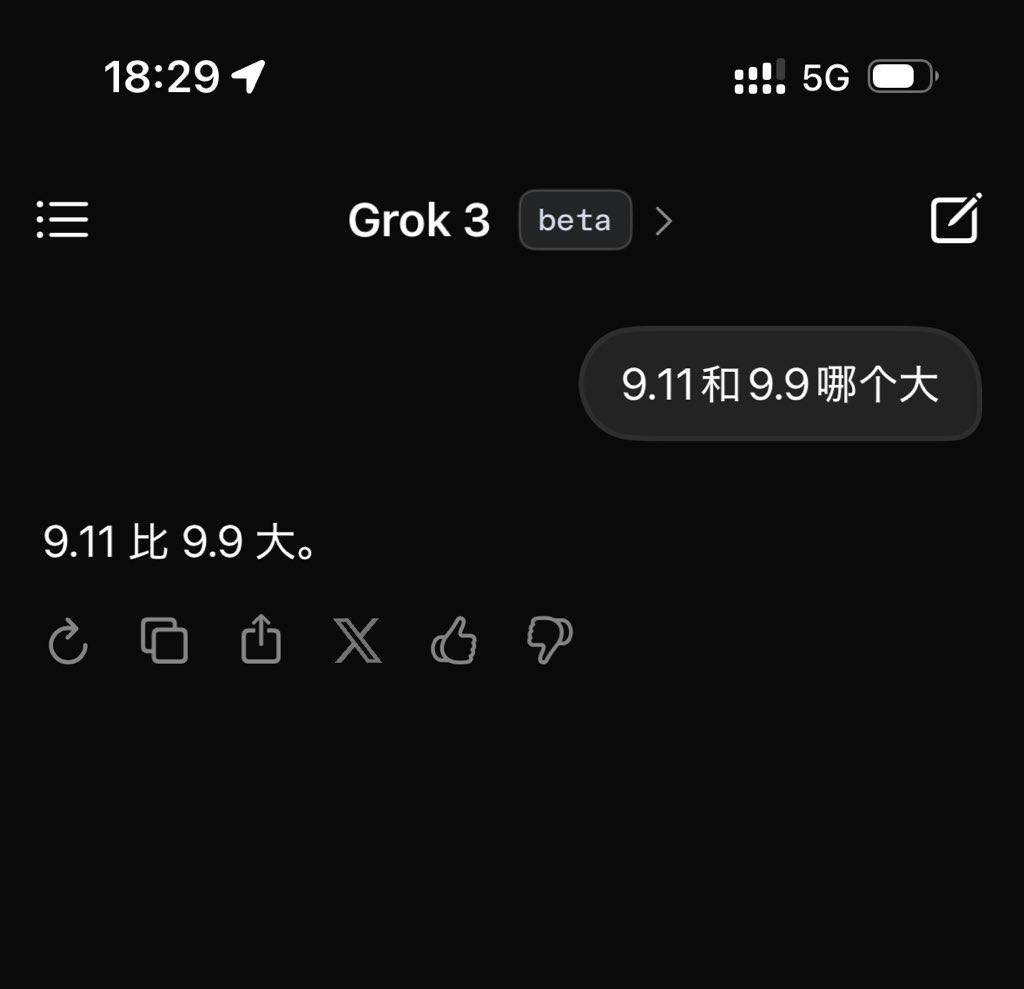
Grok3 failed to accurately identify the meaning of this question | Image source: Geek Park
After this test was posted, it quickly attracted the attention of many friends. Coincidentally, there were many similar tests overseas, such as "Which ball falls first from the Leaning Tower of Pisa?" These basic physics/mathematics questions also revealed that Grok3 was unable to handle them, leading to it being humorously dubbed "a genius unwilling to answer simple questions."
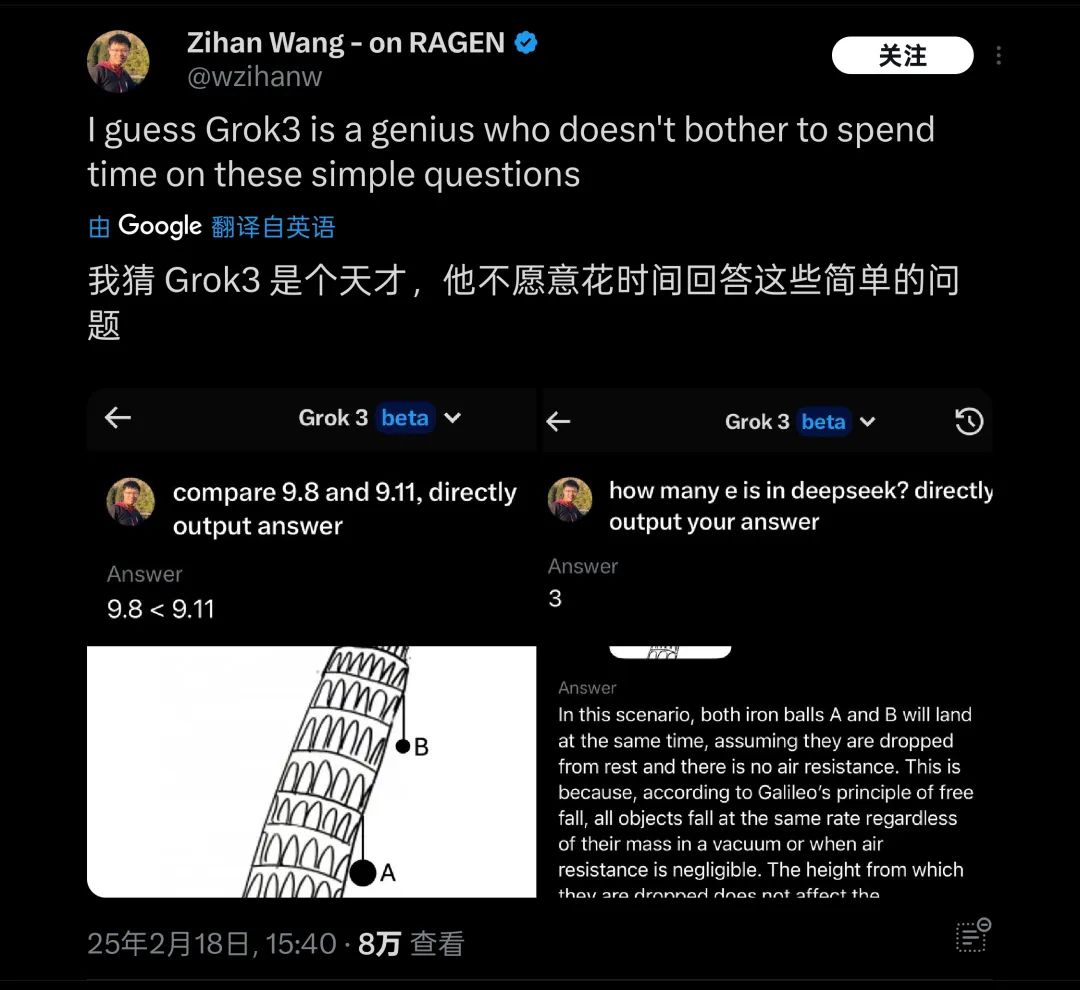
Grok3 encountered "failures" on many common sense questions during actual testing | Image source: X
In addition to the basic knowledge tests conducted by netizens where Grok3 stumbled, during the xAI release live stream, Musk demonstrated using Grok3 to analyze the classes and ascendancy effects in the game Path of Exile 2, which he claimed to play often. However, the majority of the corresponding answers provided by Grok3 were incorrect. Musk did not notice this obvious issue during the live broadcast.
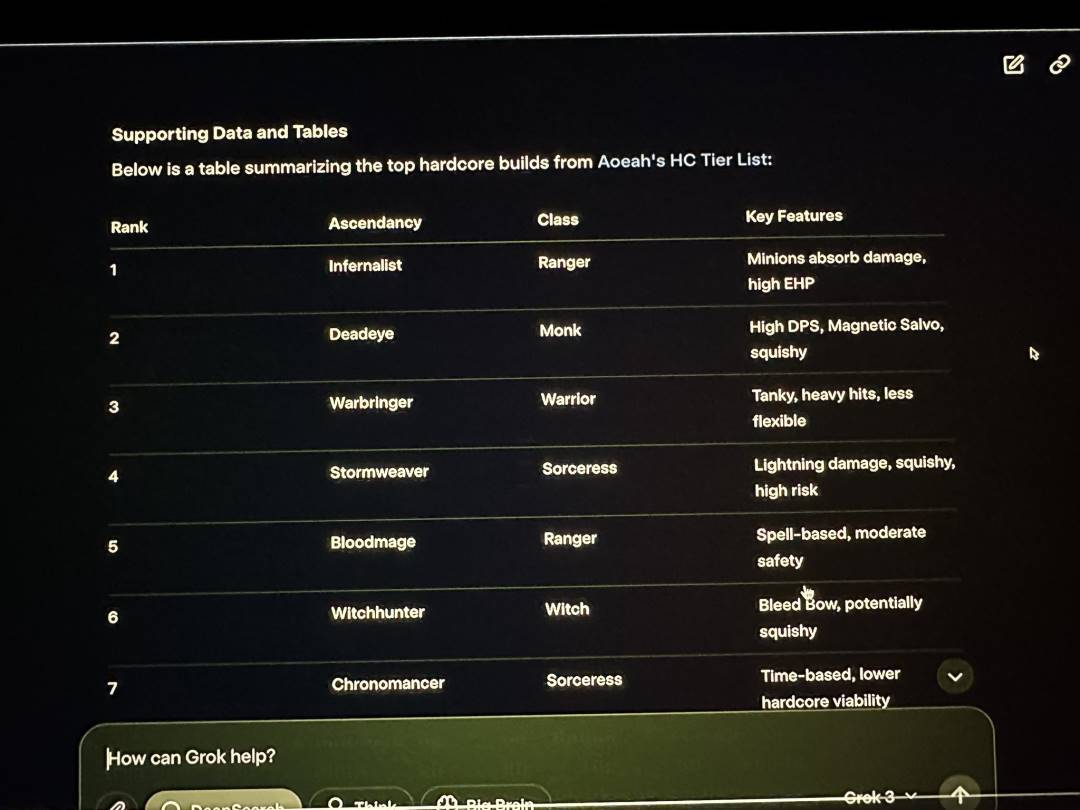
Grok3 also provided a large number of incorrect data during the live stream | Image source: X
This mistake not only became solid evidence for overseas netizens to mock Musk for "hiring a booster" in gaming but also raised significant doubts about Grok3's reliability in practical applications.
For such a "genius," regardless of actual capabilities, its reliability for extremely complex applications like Mars exploration missions must be questioned.
Currently, many testers who obtained Grok3 testing qualifications a few weeks ago, as well as those who just used the model for a few hours yesterday, all point to the same conclusion regarding Grok3's current performance:
"Grok3 is good, but it is not better than R1 or o1-Pro."

"Grok3 is good, but it is not better than R1 or o1-Pro." | Image source: X
In the official PPT released during the Grok3 launch, it claimed to be "far ahead" in the large model arena Chatbot Arena, but this actually employed some minor graphical tricks: the vertical axis of the ranking only listed scores in the 1400-1300 range, making the originally 1% difference in test results appear exceptionally pronounced in this PPT presentation.
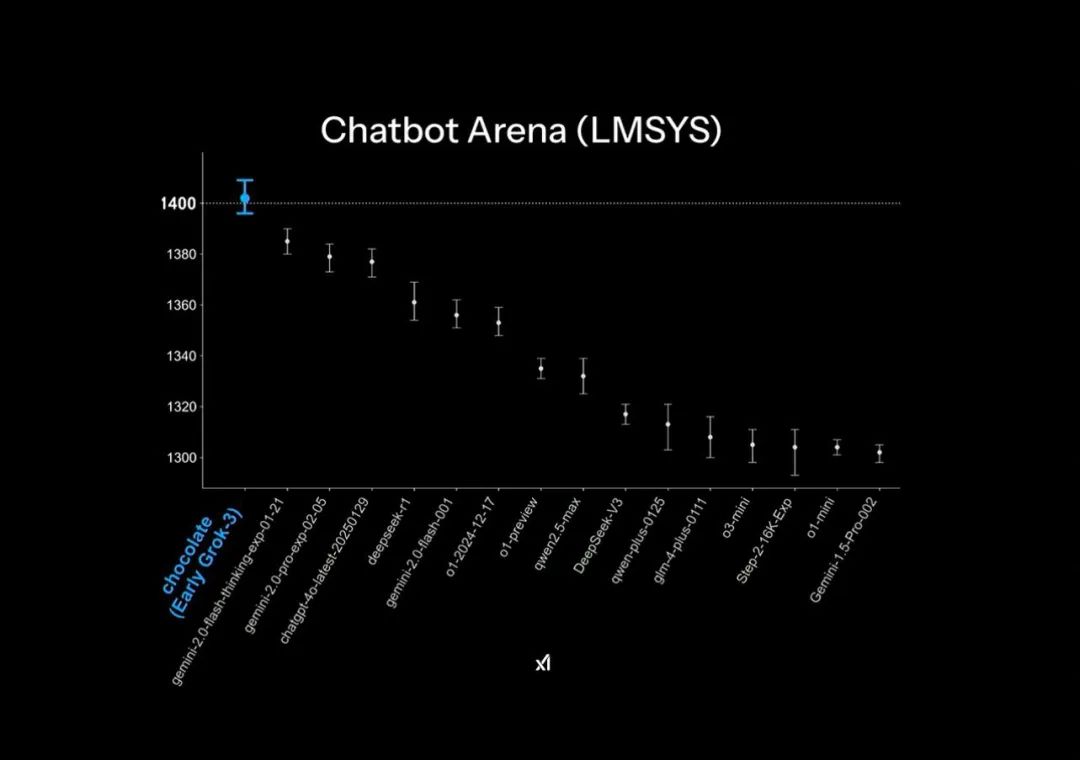
The "far ahead" effect in the official release PPT | Image source: X
In reality, Grok3 only achieved a score that was less than 1-2% higher than DeepSeek R1 and GPT4.0, which corresponds to many users' experiences in actual testing of "no significant difference."
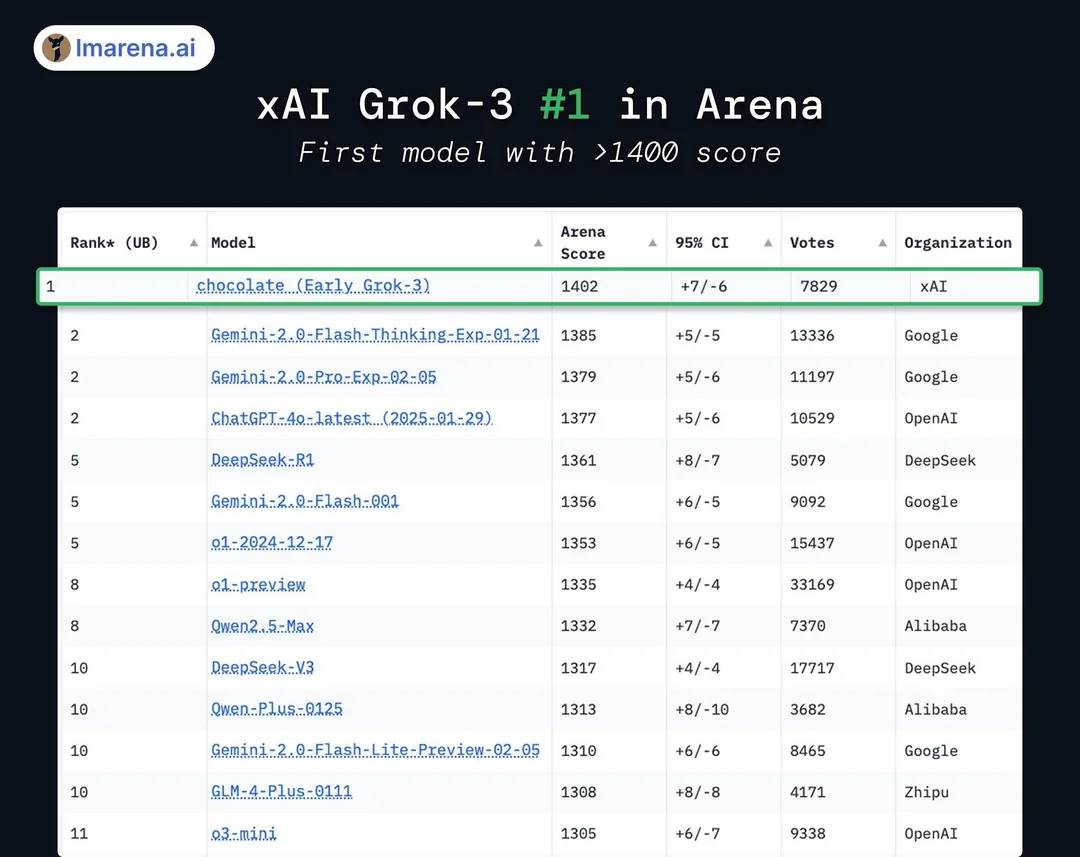
In reality, Grok3 is only 1%-2% higher than its successors | Image source: X
Moreover, although Grok3 scored higher than all currently publicly tested models, many people are skeptical about this: after all, xAI had previously "brushed scores" during the Grok2 era, and as the ranking system adjusted for response length and style, scores were significantly reduced, leading to frequent criticism from industry insiders of "high scores but low capability."
Whether it is "brushing scores" or "graphic design tricks," these demonstrate Musk's and xAI's obsession with the notion of the model's capabilities being "far ahead."
To achieve these differences, Musk has paid a hefty price: during the release, he boasted that Grok3 was trained using nearly 200,000 H100 GPUs (Musk stated "over 100,000" during the live stream), with a total training time reaching 200 million hours. This led some to believe that this was another significant boon for the GPU industry and that DeepSeek's impact on the industry was "foolish."
Many believe that stacking computing power will be the future of model training | Image source: X
However, some netizens compared the training of DeepSeek V3 using 2000 H800 GPUs over two months and calculated that Grok3's actual training power consumption is 263 times that of V3. The score difference between DeepSeek V3 and Grok3, which scored 1402 points, is even less than 100 points.
After this data was released, many quickly realized that behind Grok3's claim to be the "world's strongest," the logic of larger models equating to stronger performance has already shown significant diminishing returns.
Even the "high scores but low capability" Grok2 had the support of a vast amount of high-quality first-party data from the X (Twitter) platform. In Grok3's training, xAI naturally encountered the same "ceiling" that OpenAI currently faces—insufficient quality training data, which rapidly exposed the diminishing returns of model capabilities.
The earliest and most profound understanding of these facts likely belongs to Grok3's development team and Musk himself. Therefore, Musk has repeatedly stated on social media that the version users are currently experiencing is "just a test version" and that "the full version will be released in the coming months." Musk has even taken on the role of Grok3 product manager, suggesting users directly provide feedback on various issues encountered in the comments.
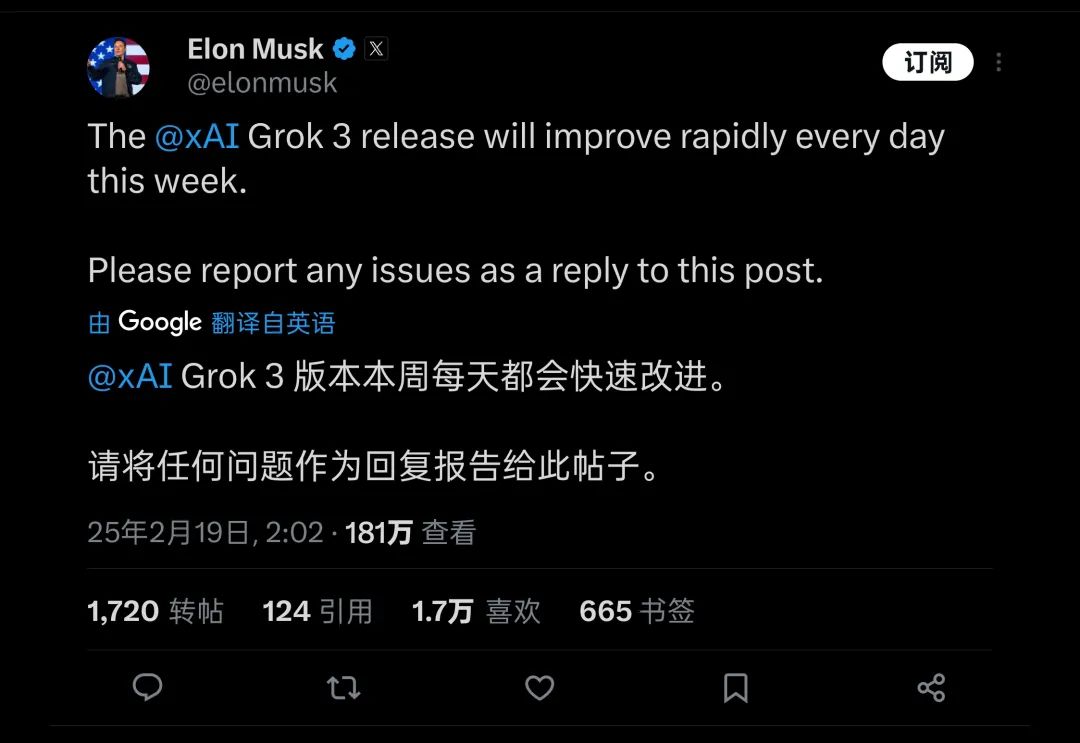
He might be the most followed product manager on Earth | Image source: X
However, within less than a day, Grok3's performance undoubtedly sounded the alarm for those hoping to rely on "brute force" to train more powerful large models: based on publicly available information from Microsoft, it is speculated that OpenAI's GPT4 has a parameter size of 1.8 trillion parameters, which is over 10 times the increase from GPT3, and the rumored GPT4.5 may even have a larger parameter size.
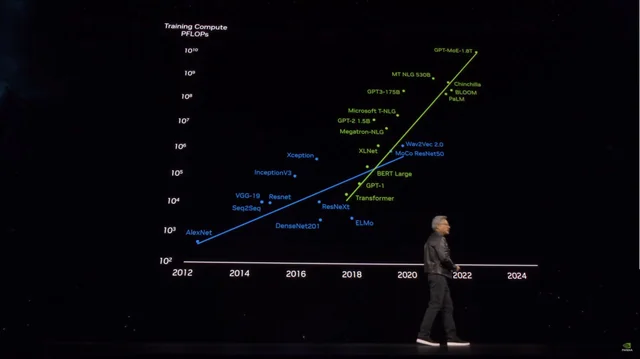
As model parameter sizes soar, training costs are also skyrocketing | Image source: X
With Grok3 leading the way, competitors like GPT4.5 and others looking to continue "burning money" to achieve better model performance through larger parameter sizes must consider how to break through the ceiling that is now within reach.
At this moment, OpenAI's former chief scientist Ilya Sutskever's statement from last December, "The pre-training we are familiar with will come to an end," has been recalled, as people attempt to find the true path for large model training.

Ilya's perspective has sounded the alarm for the industry | Image source: X
At that time, Ilya accurately predicted the nearing exhaustion of available new data and the difficulty of models to continue improving performance through data acquisition, describing this situation as akin to the consumption of fossil fuels, stating, "Just as oil is a limited resource, the content generated by humans on the internet is also finite."
In Sutskever's prediction, the next generation of models after pre-trained models will possess "true autonomy" and will have reasoning capabilities "similar to the human brain."
Unlike today's pre-trained models, which primarily rely on content matching (based on previously learned content), future AI systems will be able to learn and establish problem-solving methodologies in a manner akin to human "thinking."
Humans can achieve basic proficiency in a subject with just basic professional books, but AI large models require learning millions of data points to achieve even the most basic entry-level effects. Even when you change the way you ask a question, these basic issues may not be correctly understood, indicating that the model has not truly improved in intelligence: the basic questions mentioned at the beginning that Grok3 still cannot answer correctly are a direct manifestation of this phenomenon.
However, beyond "brute force," if Grok3 can indeed reveal to the industry that "pre-trained models are nearing their end," it would still hold significant enlightening meaning for the industry.
Perhaps, as the frenzy surrounding Grok3 gradually subsides, we will see more cases similar to Fei-Fei Li's "fine-tuning high-performance models for $50 based on specific datasets." In these explorations, we may ultimately find the true path to AGI.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





