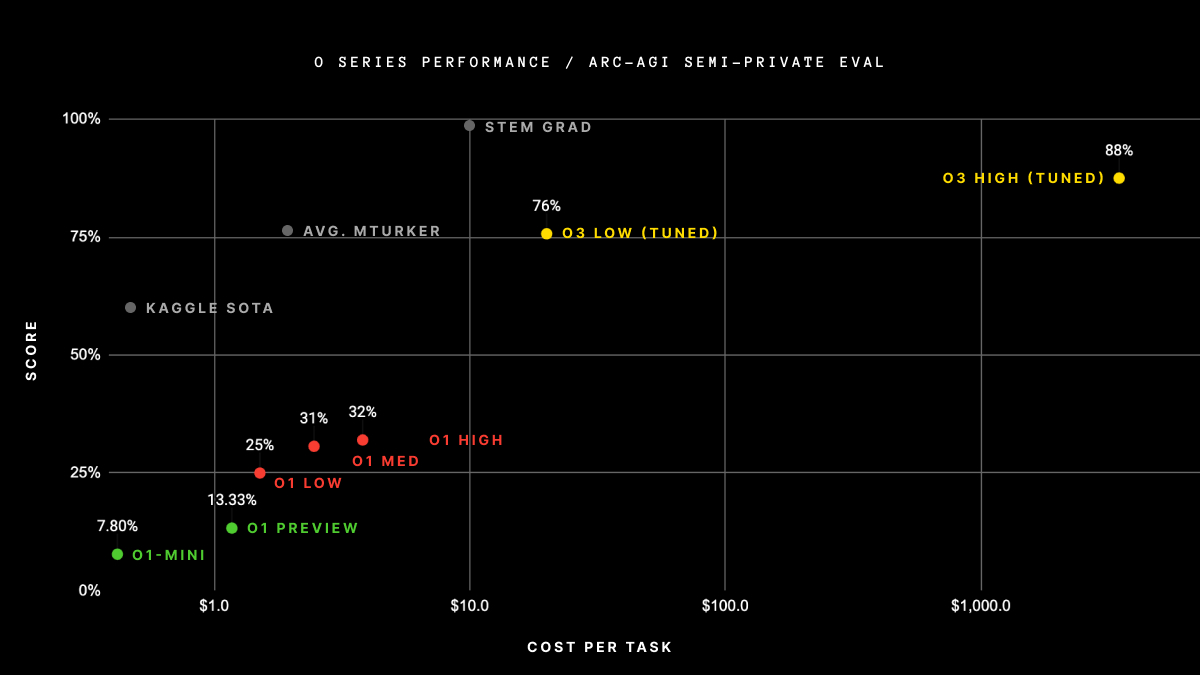
OpenAI最新的AI模型家族实现了许多人认为不可能的成就,在被称为自主研究协作人工通用智能基准(ARC-AGI)的挑战性测试中获得了前所未有的87.5%的分数——基本上接近理论上可以被视为“人类”的最低阈值。
ARC-AGI基准测试模型在多大程度上接近实现人工通用智能,这意味着它是否能够像人类一样在不同情况下思考、解决问题和适应……即使它没有接受过相关训练。这个基准对人类来说极其容易超越,但对机器来说理解和解决却极其困难。
总部位于旧金山的AI研究公司上周在其“OpenAI的12天”活动中发布了o3和o3-mini——就在谷歌宣布其自己的o1竞争对手几天之后。此次发布显示,OpenAI即将推出的模型比预期更接近实现人工通用智能。
OpenAI的新推理聚焦模型标志着AI系统在处理复杂推理方面的根本转变。与依赖模式匹配的传统大型语言模型不同,o3引入了一种新颖的“程序合成”方法,使其能够处理之前未遇到的全新问题。
“这不仅仅是渐进式的改进,而是真正的突破,”ARC团队在他们的评估报告中表示。在一篇博客文章中,ARC奖的联合创始人Francois Chollet更进一步,表示“o3是一个能够适应从未遇到过的任务的系统,可以说在ARC-AGI领域接近人类水平的表现。”
仅供参考,ARC奖表示其分数:“研究中的平均人类表现介于73.3%和77.2%之间(公共训练集平均:76.2%;公共评估集平均:64.2%)。”
OpenAI的o3在高性能计算设备上获得了88.5%的分数。这个分数远远领先于目前可用的任何其他AI模型。
o3是AGI吗?这要看你问谁
尽管其结果令人印象深刻,ARC奖委员会和其他专家表示,AGI尚未实现,因此100万美元的奖金仍未被领取。但AI行业的专家们对o3是否突破AGI基准的看法并不一致。
一些人——包括Chollet本人——对基准测试本身是否是评估模型接近真实人类水平问题解决能力的最佳标准表示质疑:“通过ARC-AGI并不等于实现AGI,实际上,我认为o3还不是AGI,”Chollet说。“o3在一些非常简单的任务上仍然失败,这表明与人类智能存在根本差异。”
他提到了一种更新版本的AGI基准,他表示这将提供更准确的衡量标准,以评估AI在多大程度上能够像人类一样进行推理。Chollet指出,“早期数据点表明,即将推出的ARC-AGI-2基准仍将对o3构成重大挑战,可能会将其分数降低到30%以下,即使在高性能计算下(而聪明的人类在没有训练的情况下仍能得分超过95%)。”
其他怀疑者甚至声称OpenAI实际上是在操控测试。“像o3这样的模型使用规划技巧。它们概述步骤(“草稿纸”)以提高准确性,但它们仍然是高级文本预测器。例如,当o3‘计数字母’时,它生成的是关于计数的文本,而不是在真正推理,”Zeroqode的联合创始人Levon Terteryan在X上写道。
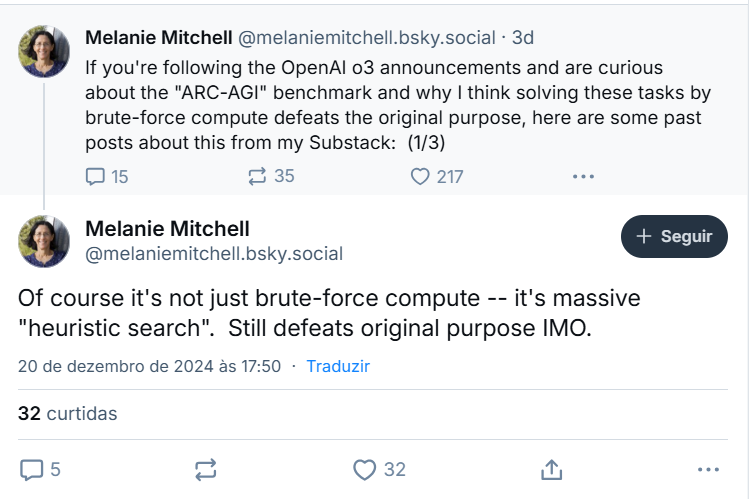
其他AI科学家也持有类似观点,例如获奖的AI研究员Melanie Mitchel,她认为o3并不是真正的推理,而是在进行“启发式搜索”。
Chollet和其他人指出,OpenAI并没有透明地说明其模型的运作方式。Mitchel表示,这些模型似乎是在不同的思维链过程中进行训练的,“这种方式或许与AlphaZero风格的蒙特卡洛树搜索并没有太大不同。”换句话说,它并不知道如何解决一个新问题,而是根据其庞大的知识库应用最可能的思维链,直到成功找到解决方案。
换句话说,o3并不是真正的创造性——它只是依赖于庞大的库通过试错的方式找到解决方案。
“暴力破解(不等于)智能。o3依赖于极端的计算能力来达到其非官方分数,”人类解放AI播客的主持人Jeff Joyce在Linkedin上辩称。“真正的AGI需要高效地解决问题。即使拥有无限资源,o3也无法破解人类认为简单的100多个难题。”
OpenAI研究员Vahidi Kazemi则属于“这是AGI”的阵营。“在我看来,我们已经实现了AGI,”他说,并指出早期的o1模型,他认为这是第一个旨在推理而不仅仅是预测下一个标记的模型。
他将其与科学方法进行了比较,认为既然科学本身依赖于系统的、可重复的步骤来验证假设,那么仅仅因为AI模型遵循一套预定的指令就将其视为非AGI是不一致的。尽管如此,OpenAI“并没有实现‘在任何任务上都比任何人类更好’,”他写道。
就他而言,OpenAI首席执行官Sam Altman并没有对AGI是否已实现发表看法。他只是说“o3是一个非常非常聪明的模型”,而“o3 mini是一个极其聪明的模型,但在性能和成本上都表现得非常好。”
聪明可能还不足以声称AGI已经实现——至少目前还不是。但请继续关注:“我们将其视为AI下一个阶段的开始,”他补充道。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






