斯坦福大学的研究人员开发了能够以惊人准确性预测人类行为的人工智能代理。由Joon Sung Park博士及其团队领导的一项最新研究表明,两个小时的访谈提供了足够的数据,使人工智能能够以85%的标准化准确率复制人类决策模式。
一个物理人的数字克隆超越了深度伪造或被称为LoRAs的“低秩适应”。这些准确的人格表现可以用于对用户进行画像,并测试他们对各种刺激的反应,从政治活动到政策提案、情绪评估,甚至是更逼真的当前人工智能头像版本。
研究团队招募了1,052名美国人,经过精心挑选,以代表不同的年龄、性别、种族、地区、教育和政治意识形态的多样化人口统计特征。每位参与者与人工智能采访者进行了两个小时的对话,生成的文字记录平均为6,491个单词。这些访谈遵循修改后的美国声音项目协议,探讨参与者的生活故事、价值观以及对当前社会问题的看法。
这就是你被画像和拥有克隆所需的一切。
但与其他研究不同,研究人员在处理访谈数据时采取了不同的方法。研究人员没有简单地将原始文字记录输入系统,而是开发了一个“专家反思”模块。这个分析工具通过多个专业视角审视每次访谈——心理学家对个性特征的看法、行为经济学家对决策模式的看法、政治科学家对意识形态立场的分析,以及人口统计专家的背景解读。
一旦完成这种多维分析,人工智能就更能够正确理解受访者的个性运作,获得比仅仅基于统计数据预测最可能行为更深入的洞察。最终的结果是一组由GPT-4o驱动的人工智能代理,能够在不同的受控场景中复制人类行为。
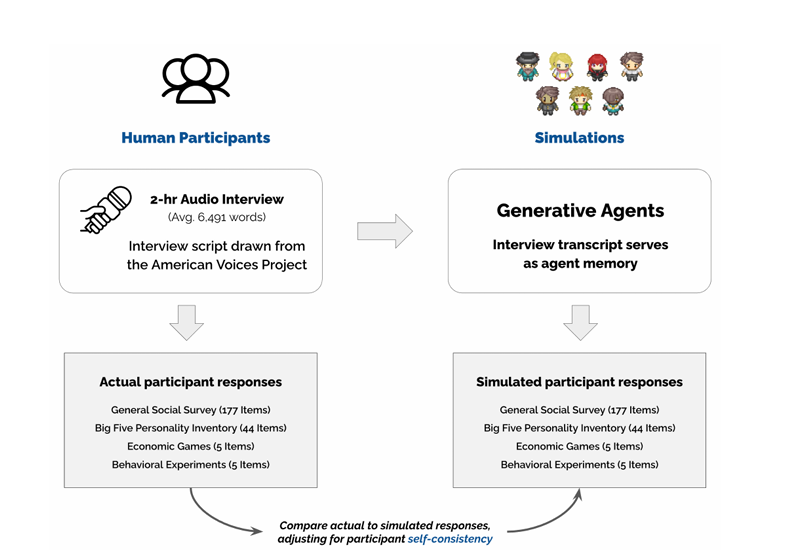
测试证明非常成功。“生成代理在一般社会调查中的参与者反应复制准确率为85%,与参与者两周后复制自己答案的准确率相当,并且在预测个性特征和实验复制结果方面表现相似,”研究指出。该系统在复制五大人格特征方面显示出类似的能力,达到了0.78的相关性,并在经济决策游戏中表现出显著的准确性,标准化相关性为0.66。(相关系数为1将表示完美的正相关。)
特别值得注意的是,与传统基于人口统计的方法相比,该系统在种族和意识形态群体中的偏见减少——这似乎是许多人工智能系统面临的问题,它们在刻板印象(假设受访者会表现出其所属群体的特征)和过于包容(避免统计/历史事实假设以保持政治正确)之间难以找到平衡。
“我们的架构在种族和意识形态群体之间减少了准确性偏见,相较于基于人口统计描述的代理,”研究人员强调,表明他们基于访谈的方法在人口统计画像中可能非常有帮助。
但这并不是第一次使用人工智能对人进行画像。
在日本,alt Inc.的CLONEdev平台一直在通过生活日志数据整合进行个性生成的实验。他们的系统结合了先进的语言处理和图像生成,创建反映用户价值观和偏好的数字克隆。“通过我们的P.A.I技术,我们致力于实现整个人人类的数字化,”alt In在一篇官方博客文章中表示。
有时你甚至不需要量身定制的访谈。以MileiGPT为例。一位来自阿根廷的人工智能研究人员能够通过数千小时的公开内容微调一个开源大型语言模型,复制阿根廷总统哈维尔·米莱的沟通模式和决策过程。这些进展促使研究人员探索“数字双胞胎”的想法,技术分析师和专家如Rob Enderle认为,这种技术在未来10年内可能会完全实现。
当然,如果人工智能机器人不会抢走你的工作,你的人工智能双胞胎可能会。“这些的出现需要大量的思考和伦理考虑,因为我们思考的复制品对雇主来说可能是非常有用的,”Enderle告诉BBC。“如果你的公司为你创建了一个数字双胞胎,并说,‘嘿,你有这个数字双胞胎,我们不支付它工资,那我们为什么还要雇用你?’”
事情可能看起来有点可怕。深度伪造不仅会模仿你的外貌,人工智能克隆还能够根据你行为的简短画像模仿你的决策。虽然斯坦福的研究人员确保采取了安全措施,但显然人类与数字身份之间的界限正变得越来越模糊。我们已经在跨越这条界限。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








