Cloudflare,一家全球互联网安全公司,声称保护全球约20%的网络流量,推出了所谓的“易用按钮”,供网站所有者阻止人工智能服务访问其内容。此举是因为用于训练人工智能模型的内容需求急剧增加。
Cloudflare的核心服务作为互联网代理,在网站收到网页流量之前扫描和过滤。该公司称,其网络平均每秒处理超过5700万个请求。
“为了帮助保护内容创作者的安全互联网,我们刚刚推出了一个全新的‘易用按钮’,用于阻止所有人工智能机器人,”Cloudflare在宣布中表示,“我们清楚地听到客户不希望人工智能机器人访问他们的网站,尤其是那些不诚实的机器人。”
虽然一些人工智能公司能够正确识别其网络爬虫机器人并遵守网站的指示远离,但并非所有公司都对其活动透明。
这个新的简单设置将提供给所有Cloudflare客户,包括免费用户。
解析人工智能机器人活动
除了宣布之外,Cloudflare还分享了关于其系统观察到的人工智能爬虫活动的大量信息。
根据Cloudflare的数据,6月份,使用Cloudflare的前100万个“互联网属性”中,约39%被人工智能机器人访问。然而,只有2.98%的属性采取措施阻止或挑战这些请求。Cloudflare还提到“互联网属性的排名越高(越受欢迎),就越有可能成为人工智能机器人的目标。”
该公司表示,字节跳动所有者的网页爬虫、亚马逊、Anthropic和OpenAI运营的网络爬虫是最活跃的。字节跳动的Bytespider是最活跃的网络爬虫,其请求数量、活动范围和被阻止的频率均名列前茅。OpenAI管理的GPTBot用于收集产品如ChatGPT的训练数据,在爬取活动和被阻止方面排名第二。
Perplexity的网络爬虫最近因其内容爬取做法引起争议,被发现访问了Cloudflare保护的一小部分网站。
虽然网站所有者可以实施自己的规则来阻止已知的网络爬虫,但Cloudflare还表示,大多数这样做的客户只是阻止了像OpenAI、Google或Meta这样的主流人工智能开发者,而没有阻止字节跳动等公司的顶级爬虫。
人工智能对抗人工智能
Cloudflare的报告强调了一些人工智能机器人操作者诉诸欺骗手段,试图规避阻止它们的措施,试图将它们的爬虫活动伪装成合法的网页流量。
“遗憾的是,我们观察到机器人操作者试图通过伪造的用户代理来表现得像真正的浏览器,”Cloudflare写道。
事实证明,人工智能是该公司阻止自动活动的关键工具,无论是来自人工智能开发者、搜索引擎还是恶意攻击者。Cloudflare表示,它使用机器学习模型为受其服务保护的网站上的每个请求分配“机器人分数”,低分表示活动合法性的可能性较低。
凭借Cloudflare对全球互联网流量的庞大数据集,该模型考虑了许多信号,包括请求的IP地址、用户代理和行为模式,以确定机器人分数。
图片:Cloudflare
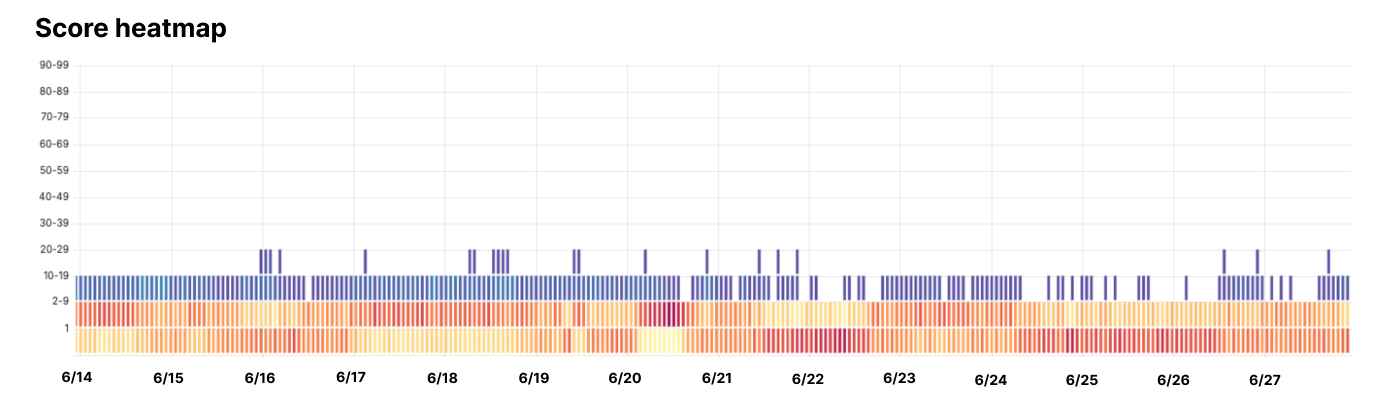
为了说明这一点,Cloudflare表示,它查看了一个以其闪烁行为而闻名的特定机器人的流量。结果很明显:所有检测都得分低于100中的30分,其中绝大多数都属于最低的两个分数段,表明得分为9或更低。换句话说,即使试图掩盖其来源,机器人的活动模式也暴露了它的身份,使Cloudflare能够阻止它。
保护网页内容
生成式人工智能模型依赖于大量来自全球各地的现有内容。为了使人工智能继续提供当前信息,其开发者需要继续大规模收集信息。
网站所有者和内容创作者正在反击,像新闻机构这样的大型出版商正在对人工智能公司采取法律行动。在Perplexity的案例中,像《福布斯》和《连线》这样的出版物声称它在未经许可的情况下获取并重新发布内容。音乐出版商索尼在5月份预先警告了700多家科技公司,而本周,华纳音乐集团也做了同样的事情。 ```
威胁对于出版商来说可能是一种生存威胁,如果人工智能越来越多地为用户提供信息而不将他们引荐到信息来源。SparkToro首席执行官兰德·菲什金最近发表的一项研究指出,60%的在谷歌上搜索信息的人停止访问提供信息的网站,因为谷歌的人工智能立即提供了总结回答。
由瑞安·奥扎瓦编辑。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







