特别感谢Dennis Pourteaux和Jay Baxter的反馈和审查。
过去两年,Twitter X的情况可以说是动荡不安。去年,埃隆·马斯克以440亿美元的价格收购了该平台,之后对公司的人员安排、内容审查和商业模式进行了全面改革,甚至可能改变了网站上的文化,这些改变可能更多地是埃隆的软实力所致,而非具体的政策决定。但在这些极具争议的行动中,Twitter上的一个新功能迅速变得非常重要,并且似乎受到了各种政治立场的人们的喜爱:社区笔记。
社区笔记是一个事实核查工具,有时会附加上下文说明,就像上面埃隆的推文中的那样,作为一个事实核查和反虚假信息的工具。它最初被称为Birdwatch,并于2021年1月首次作为试点项目推出。自那时起,它已经分阶段扩展,其最快速的扩张阶段与Twitter去年被埃隆接管的时间重合。如今,社区笔记经常出现在Twitter上受到很大关注的推文上,包括那些涉及有争议的政治话题。在我看来,以及在我与跨越政治立场的许多人的看法中,这些笔记在出现时都是具有信息量和价值的。
但最让我感兴趣的是社区笔记,尽管它并不是一个“加密项目”,但它可能是我们在主流世界中看到的最接近“加密价值观”的东西。社区笔记并不是由一些中央选定的专家编写或策划的;相反,任何人都可以编写和投票,哪些笔记显示或不显示完全由一个开源算法决定。Twitter网站有一份详尽的指南描述了算法的工作原理,你可以下载包含已发布的笔记和投票的数据,本地运行算法,并验证输出是否与Twitter网站上可见的内容相匹配。它并不完美,但在极具争议的情况下,它令人印象深刻地接近了满足可信中立的理想,同时仍然非常有用。
社区笔记算法是如何工作的?
任何符合一些标准的Twitter账户(基本上是:已激活6个月以上,没有最近的违规记录,已验证电话号码)都可以注册参与社区笔记。目前,参与者正在逐渐随机地被接受,但最终计划是让符合条件的任何人都可以加入。一旦被接受,你可以首先参与对现有笔记进行评分,一旦你做出了足够多的良好评分(通过查看哪些评分与该笔记的最终结果匹配来衡量),你也可以自己撰写笔记。
当你撰写一条笔记时,该笔记会根据其他社区笔记成员的评价得分。这些评价可以被视为沿着“有帮助”、“有些有帮助”和“不帮助”的3点评分标准进行投票,但评价也可以包含一些在算法中起作用的其他标签。根据这些评价,笔记会得到一个分数。如果笔记的分数高于0.40,那么该笔记会显示;否则,该笔记不会显示。
计算分数的方式使得该算法独特。与简单的算法不同,简单的算法旨在简单地计算用户评分的某种总和或平均值,并将其用作最终结果,社区笔记评分算法明确尝试优先考虑那些得到来自不同观点的人们积极评价的笔记。也就是说,如果通常在评价笔记时意见不一的人最终在某个特定笔记上达成一致,那么该笔记的得分会特别高。
让我们深入了解这是如何运作的。我们有一组用户和一组笔记;我们可以创建一个矩阵 \(M\),其中单元格 \(M_{i,j}\) 表示第i个用户对第j个笔记的评分。
对于任何给定的笔记,大多数用户都没有对该笔记进行评分,因此矩阵中的大多数条目将为零,但这没关系。该算法的目标是创建一个用户和笔记的四列模型,为每个用户分配两个我们可以称之为“友好度”和“极性”的统计数据,为每个笔记分配两个我们可以称之为“有帮助度”和“极性”的统计数据。该模型试图预测矩阵作为这些值的函数,使用以下公式:
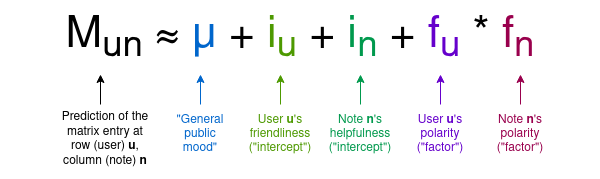
请注意,这里我介绍了在Birdwatch论文中使用的术语,以及我自己的术语,以提供对变量含义的非数学直觉:
- μ 是一个“一般公众情绪”参数,反映用户通常给出的评分有多高
- \(i_u\) 是用户的“友好度”:该特定用户倾向于给出高评分的可能性有多大
- \(i_n\) 是笔记的“有帮助度”:该特定笔记得到高评分的可能性有多大。最终,这是我们关心的变量。
- \(f_u\) 或 \(f_n\) 是用户或笔记的“极性”:它在政治极化的主轴上的位置。在实践中,负极性大致意味着“左倾”,正极性意味着“右倾”,但请注意极化轴是通过分析用户和笔记紧急发现的;左派和右派的概念绝不是硬编码的。
该算法使用了一个相当基本的机器学习模型(标准梯度下降),以找到这些变量的值,以尽可能最好地预测矩阵的值。分配给特定笔记的有帮助度就是该笔记的最终得分。如果一条笔记的有帮助度至少为+0.4,那么该笔记会显示。
这里的核心巧妙思想是,“极性”术语吸收了一条笔记的特性,导致它受到一些用户喜欢而受到其他用户不喜欢,而“有帮助度”术语只衡量了一条笔记具有的导致所有用户喜欢的特性。因此,选择有帮助度可以识别得到跨部落认可的笔记,并排除得到一部落欢呼而引起另一部落反感的笔记。
我制作了基本算法的简化实现;你可以在这里找到它,并欢迎进行尝试。
现在,上面只是算法核心的描述。实际上,还有很多额外的机制叠加在上面。幸运的是,它们在公共文档中有描述。这些机制包括:
- 算法运行多次,每次都会向投票中添加一些随机生成的极端“伪投票”。这意味着算法对于每个笔记的真实输出是一个值范围,最终结果取决于从这个范围中取出的“下限置信度”,并与0.32的阈值进行比较。
- 如果许多用户(特别是与笔记极性相似的用户)给一条笔记评为“不帮助”,并且他们进一步指定了相同的“标签”(例如“有争议或偏见的语言”,“来源不支持笔记”)作为评分原因,那么笔记被发布所需的有帮助度阈值将从0.4增加到0.5(在实践中看起来很小,但实际上非常重要)
- 如果一条笔记被接受,那么它的有帮助度必须降低到比笔记最初被接受所需的阈值低0.01分
- 算法运行更多次,使用多个模型,有时会提升原始有帮助度得分在0.3到0.4之间的笔记
总的来说,你会得到一些相当复杂的Python代码,总共有6282行,分布在22个文件中。但这一切都是开放的,你可以下载笔记和评分数据,并自行运行它,看看输出是否与Twitter上实际情况相符。
那么这在实践中是什么样子呢?
这个算法中最重要的一个想法,区别于简单地从人们的投票中取平均分数的想法,就是我称之为“极性”值。算法文档将其称为 \(f_u\) 和 \(f_n\),使用 \(f\) 代表因子,因为这两个术语会相互相乘;更一般的语言部分是因为最终希望使 \(f_u\) 和 \(f_n\) 成为多维的。
极性被分配给用户和笔记。用户ID与底层Twitter账户之间的联系被故意隐藏,但笔记是公开的。实际上,算法生成的极性,至少对于英语数据集来说,与左派和右派政治光谱非常密切地对应。
以下是一些得到极性约为-0.8的笔记的例子:
笔记
极性
一些保守派科罗拉多州议员放大了反跨性别言论,包括在不包括科罗拉多斯普林斯的科罗拉多州共和党倾向的第三国会选区险胜连任的美国众议员劳伦·博伊伯特。https://coloradosun.com/2022/11/20/colorado-springs-club-q-lgbtq-trans/
-0.800
总统特朗普在2020年选举前几个月明确破坏了美国对选举结果的信任。https://www.npr.org/2021/02/08/965342252/timeline-what-trump-told-supporters-for-months-before-they-attacked 执行Twitter的服务条款并不是选举干预。
-0.825
2020年选举是以自由和公平的方式进行的。https://www.npr.org/2021/12/23/1065277246/trump-big-lie-jan-6-election
-0.818
请注意,我在这里并没有挑拣;这些实际上是我在本地运行算法生成的scored_notes.tsv电子表格中的前三行,它们的极性得分(在电子表格中称为coreNoteFactor1)小于-0.8。
现在,以下是一些得到极性约为+0.8的笔记。事实证明,其中许多要么是人们用葡萄牙语谈论巴西政治,要么是特斯拉粉丝愤怒地反驳特斯拉的批评,所以让我稍微挑选一下,找到一些不是这样的:
笔记
极性
截至2021年的数据显示,“黑人或非洲裔美国人”儿童中有64%生活在单亲家庭中。https://datacenter.aecf.org/data/tables/107-children-in-single-parent-families-by-race-and-ethnicity
+0.809
与滚石乐队试图声称儿童贩卖是“与Qanon相关的阴谋”相反,儿童贩卖是一个真实而严重的问题,这部电影准确地描绘了这一问题。地下铁路行动与跨国机构合作打击这一问题。https://ourrescue.org/
+0.840
这些LGBTQ+儿童书被禁止的例子页面可以在这里看到:https://i.imgur.com/8SY6cEx.png 这些书是淫秽的,这不受美国宪法保护作为言论自由。https://www.justice.gov/criminal-ceos/obscenity “联邦法严格禁止向未成年人分发淫秽物品。
+0.806
值得再次提醒我们的是,“左派 vs 右派分歧”并没有以任何方式硬编码到算法中;它是通过计算发现的。这表明,如果你在其他文化背景中应用这个算法,它可能会自动检测到它们的主要政治分歧,并跨越这些分歧。
与此同时,得到最高有帮助度的笔记看起来是这样的。这一次,因为这些笔记实际上显示在Twitter上,我可以直接截图:
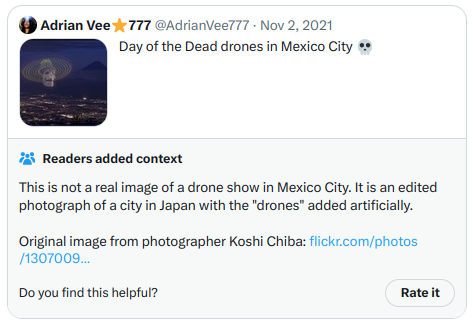
还有另一张:
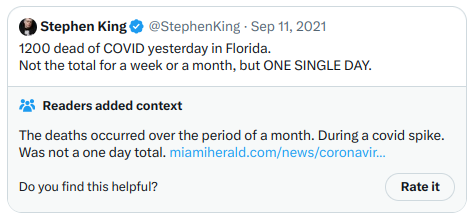
第二张更直接地涉及高度党派化的政治主题,但它是一个清晰、高质量和信息丰富的笔记,因此得到了高评分。总的来说,这个算法似乎是有效的,通过运行代码来验证算法的输出的能力似乎也是有效的。
我对这个算法有什么看法?
当分析这个算法时,最让我印象深刻的是它的复杂性。有“学术论文版本”,一个梯度下降,找到一个最佳拟合五项向量和矩阵方程,然后是真实版本,一个由许多不同执行算法的复杂系列,沿途有许多任意系数。
即使是学术论文版本也隐藏了复杂性。它正在优化的方程是一个次数-4方程(因为在预测公式中有一个次数为2的 \(f_u * f_n\) 项,并且由于成本函数测量误差的平方)。虽然在任意数量的变量上优化次数为2的方程几乎总是有唯一解,你可以用相当基本的线性代数计算出来,但是在许多变量上优化次数为4的方程通常有许多解,因此多轮梯度下降算法可能会得出不同的答案。对输入的微小改变可能会导致下降从一个局部最小值翻转到另一个局部最小值,从而显著改变输出。
这种区别与我参与工作的算法(如二次资助)之间的区别,对我来说感觉就像是经济学家的算法和工程师的算法之间的区别。经济学家的算法在最佳情况下重视简单、相对容易分析,并具有清晰的数学特性,说明为什么它对于它试图解决的任务是最优的(或者至少是最不差的),并且理想情况下证明了某人试图利用它时可能造成多大损害。另一方面,工程师的算法是迭代试错的结果,看看在工程师的操作环境中什么有效,什么不行。工程师的算法务实并完成任务;经济学家的算法在面对意外情况时不会完全疯狂。
或者,正如尊敬的互联网哲学家roon(又名tszzl)在相关主题上著名地说过:

当然,我会说,加密的“理论美学”方面恰恰是必要的,以区分那些实际上是无信任的协议和看起来不错、似乎运行良好但在幕后需要信任一些中心化参与者的不稳定构造,或者更糟的是,实际上是彻头彻尾的骗局。
深度学习在有效时是有效的,但它对各种对抗机器学习攻击有不可避免的漏洞。如果做得好,书呆子陷阱和高度抽象的阶梯可以对它们相当有韧性。因此,我有一个问题:我们能把Community Notes本身变成更像经济学家算法的东西吗?
为了实际上说明这意味着什么,让我们探讨我几年前为类似目的想出的一个算法:有界配对二次资助。
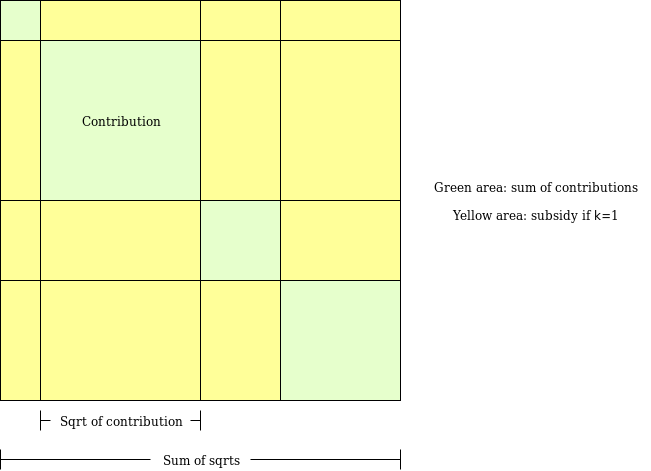
有界配对二次资助的目标是填补“常规”二次资助中的一个漏洞,即即使两个参与者相互勾结,他们也可以向一个虚假项目贡献很高的金额,然后将资金返还给他们,从而获得大额补贴,耗尽整个资金池。在配对二次资助中,我们为每对参与者分配一个有限的预算 \(M\)。算法遍历所有可能的参与者对,如果算法决定向某个项目 \(P\) 添加补贴,因为参与者 \(A\) 和参与者 \(B\) 都支持它,那么该补贴就来自分配给对 \((A, B)\) 的预算。因此,即使 \(k\) 个参与者勾结,他们从机制中偷取的金额最多也只能是 \(k * (k-1) * M\)。
一个完全符合这种形式的算法对Community Notes的情境并不适用,因为每个用户的投票非常少:平均而言,任何两个用户之间都没有共同的投票,因此算法无法通过单独查看每对用户来了解用户的极性。机器学习模型的目标恰恰是尝试从无法直接分析的非常稀疏的源数据中“填充”矩阵。但这种方法的挑战在于,需要额外的努力来以一种不会在面对少数不良投票时使结果高度不稳定的方式进行。
Community Notes是否真的在对抗极化?
我们可以做的一件事是分析Community Notes算法是否真的在任何程度上对抗极化 - 也就是说,它是否真的比一个天真的投票算法做得更好。天真的投票算法已经在一定程度上对抗极化:一个帖子得到200个赞和100个踩的情况比只得到200个赞的帖子要差。但Community Notes是否比那做得更好呢?
从抽象的算法来看,很难说。为什么一个平均评分很高但极化的帖子会得到强烈的极性和高的帮助度?理念是,极性应该“吸收”导致帖子得到很多投票的特性,如果这些投票是相互冲突的,但它真的做到了吗?
为了检查这一点,我运行了我自己简化的实现进行了100轮。平均结果如下:
质量平均值:Group 1(好):0.30032841807271166Group 2(好但额外极化):0.21698871680927437Group 3(中立):0.09443120045416832Group 4(差):-0.1521160965793673
在这个测试中,“好”帖子从同一政治部落的用户那里得到+2的评分,从相反政治部落的用户那里得到+0的评分,“好但额外极化”的帖子从同一部落的用户那里得到+4的评分,从相反部落的用户那里得到-2的评分。同样的平均值,但不同的极性。而且看起来“好”帖子的平均帮助度比“好但额外极化”的帖子要高。
更接近“经济学家算法”的另一个好处是对算法如何惩罚极化有一个更清晰的解释。
在高风险情况下,这一切有多有用?
我们可以通过看一个具体的情况来看一些这是如何发挥作用的。大约一个月前,伊恩·布雷默抱怨说,一条对中国政府官员的推文添加了一个高度批评的Community Note已被删除。
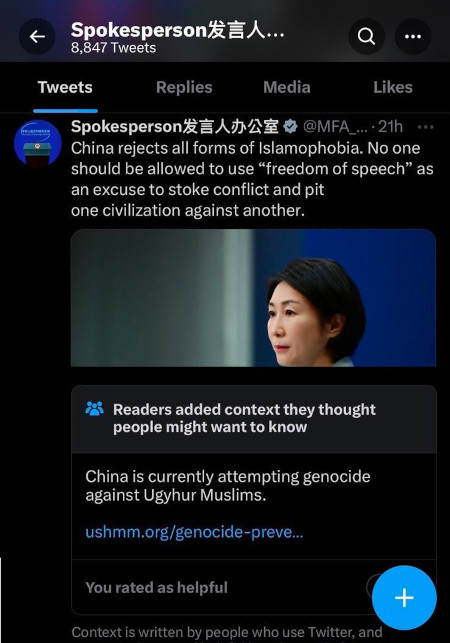
现在不再可见的注释。由Ian Bremmer截图。
这是一件严重的事情。在一个美好的以太坊社区环境中进行机制设计是一回事,那里最大的抱怨是$20,000给了一个极化的Twitter影响者。在涉及影响数百万人并且每个人通常都可以理解地假设最大的恶意的政治和地缘政治问题上进行机制设计是另一回事。但如果机制设计者想要对世界产生重大影响,与这些高风险环境进行互动最终是必要的。
在Twitter的情况下,有一个明显的原因可以让人怀疑中央操纵是导致注释被删除的原因:埃隆在中国有很多商业利益,因此有可能是埃隆强迫Community Notes团队干预算法的输出并删除这个特定的注释。
幸运的是,该算法是开源且可验证的,所以我们实际上可以深入了解!让我们来做这件事。原始推文的URL是https://twitter.com/MFA_China/status/1676157337109946369。结尾的数字1676157337109946369是推文ID。我们可以在可下载的数据中搜索该ID,并确定电子表格中具有上述注释的特定行:
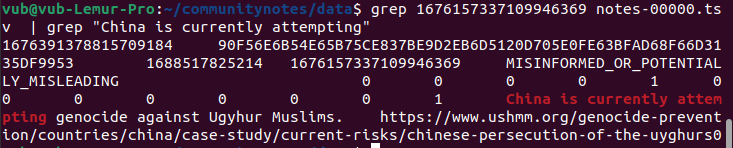
在这里,我们得到了注释本身的ID,1676391378815709184。然后我们在运行算法生成的scored_notes.tsv和note_status_history.tsv文件中搜索那个,我们得到:
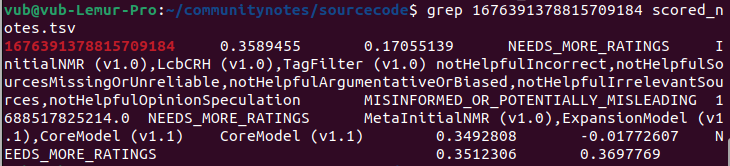

第一个输出中的第二列是注释的当前评分。第二个输出显示了注释的历史:它当前的状态在第七列(NEEDS_MORE_RATINGS),而它之前收到的第一个不是NEEDS_MORE_RATINGS的状态在第五列(CURRENTLY_RATED_HELPFUL)。因此,我们看到算法本身首先显示了该注释,然后在其评分略有下降后将其删除 - 似乎没有涉及中央干预。
通过查看投票本身,我们可以以另一种方式看到这一点。我们可以扫描ratings-00000.tsv文件,以分离出该注释的所有评分,并查看有多少评为HELPFUL和NOT_HELPFUL:

但如果按时间戳排序,并查看前50个投票,你会看到40个HELPFUL投票和9个NOT_HELPFUL投票。因此我们得出相同的结论:注释的最初受众更看好该注释,然后随着时间的推移,评分开始较高,然后下降。
不幸的是,注释如何改变状态的确切故事很难解释:这不是一个简单的“之前评分高于0.40,现在低于0.40,所以被删除”的问题。相反,大量的NOT_HELPFUL回复触发了异常值条件之一,增加了注释需要保持在阈值以上的帮助度分数。
这是另一个学习机会:使一个可信的中立算法真正可信需要保持简单。如果一个注释从被接受到不被接受,应该有一个简单易懂的故事解释原因。
当然,还有一种完全不同的方式可以操纵这个投票:串通。看到自己不赞成的注释的人可以号召一个高度参与的社区(或者更糟的是一大群假账号)来给它评为NOT_HELPFUL,而且可能并不需要太多的投票就能将该注释从被视为“有帮助”变为“两极化”。要适当地减少该算法对这种协调攻击的脆弱性,需要进行更多的分析和工作。一个可能的改进是不允许任何用户对任何注释进行投票,而是使用“为您推荐”的算法来随机分配注释给评分者,并只允许评分者对他们被分配到的注释进行评分。
Community Notes不够“勇敢”吗?
我看到的对Community Notes的主要批评基本上是它做得不够。两篇最近的文章都提到了这一点。引用其中一篇:
该计划严重受限于一个事实,即要使Community Note成为公开信息,它必须得到来自政治光谱各个方面人们的共识。
“它必须具有意识形态共识,”他说。“这意味着左派和右派的人们必须同意该注释必须附加到该推文上。”
本质上,这需要“跨意识形态对真相的一致认同,在日益党派化的环境中,实现这种共识几乎是不可能的,”他说。
这是一个棘手的问题,但最终我认为,与其让十条错误信息的推文自由传播,不如让一条被不公正地评判的推文被注释覆盖要好。我们已经看到了多年的事实核查是勇敢的,而且确实是来自“嗯,实际上我们知道真相,我们知道一方撒谎的频率要比另一方高得多”的角度。结果如何呢?


老实说,对事实核查的概念存在相当普遍的不信任。这里的一个策略是:忽略那些讨厌者,记住事实核查专家确实比任何投票系统更了解事实,坚定不移地继续前进。但全盘采用这种方法似乎有风险。建立至少在某种程度上受到所有人尊重的跨部落机构是有价值的。就像威廉·布莱克斯通的格言和法院一样,我觉得保持这种尊重需要一个系统,它犯的遗漏之罪远远多于犯的过错之罪。因此,对我来说,至少有一个主要组织采取了这种另类路径,并将其罕见的跨部落尊重视为一种珍贵的资源并加以发展,这似乎是有价值的。
另一个我认为Community Notes保守是可以接受的原因是,我认为并不是每一条错误信息的推文,甚至大多数错误信息的推文都需要得到纠正性注释的目标。即使不到百分之一的错误信息推文得到提供背景或纠正的注释,Community Notes 仍然作为教育工具提供了极其宝贵的服务。目标不是纠正一切;相反,目标是提醒人们存在多种观点,某些看起来在孤立状态下令人信服和引人入胜的帖子实际上是相当不正确的,而你,是的,你,通常可以进行基本的互联网搜索来验证它是不正确的。
Community Notes 不能也不应该成为解决公共认识论所有问题的奇迹良药。无论它解决不了什么问题,都有足够的空间让其他机制,无论是新潮的小工具,比如预测 市场,还是雇佣具有领域专业知识的全职员工的传统组织,来填补这些空白。
结论
Community Notes 不仅是一个引人入胜的社交媒体实验,也是一种引人入胜的新兴机制设计类型的实例:有意试图识别极化,并支持那些跨越分歧而不是延续分歧的事物。
我知道的这一类中的另外两个东西是 (i) 两两二次资助,正在Gitcoin Grants中使用,以及 (ii) Polis,一种使用聚类算法来帮助社区识别通常在不同观点的人中普遍受欢迎的陈述的讨论工具。这种机制设计领域是有价值的,我希望我们能在这个领域看到更多的学术研究。
Community Notes 提供的算法透明度并不完全是完全去中心化的社交媒体——如果你不同意Community Notes 的工作方式,就没有办法以不同的算法查看相同内容的视图。但在未来几年内,这是非常大规模应用程序能够达到的最接近的状态,我们可以看到它已经提供了很多价值,既可以防止中心化操纵,也可以确保不参与这种操纵的平台得到应有的赞誉。
我期待着在未来十年里看到Community Notes,以及希望看到许多类似精神的算法,得到发展和成长。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







