作者:新智元

【新智元导读】阿里Qwen3凌晨开源,正式登顶全球开源大模型王座!它的性能全面超越DeepSeek-R1和OpenAI o1,采用MoE架构,总参数235B,横扫各大基准。这次开源的Qwen3家族,8款混合推理模型全部开源,免费商用。
就在今天凌晨,备受全球期待的阿里新一代通义千问模型Qwen3开源!
一经问世,它立刻登顶全球最强开源模型王座。
它的参数量仅为DeepSeek-R1的1/3,但成本大幅下降,性能全面超越R1、OpenAI-o1等全球顶尖模型。
Qwen3是国内首个「混合推理模型」,「快思考」与「慢思考」集成进同一个模型,对简单需求可低算力「秒回」答案,对复杂问题可多步骤「深度思考」,大大节省算力消耗。
它采用混合专家(MoE)架构,总参数量235B,激活仅需22B。
它的预训练数据量达36T ,并在后训练阶段多轮强化学习,将非思考模式无缝整合到思考模型中。
一经诞生,Qwen3立刻横扫各大基准。
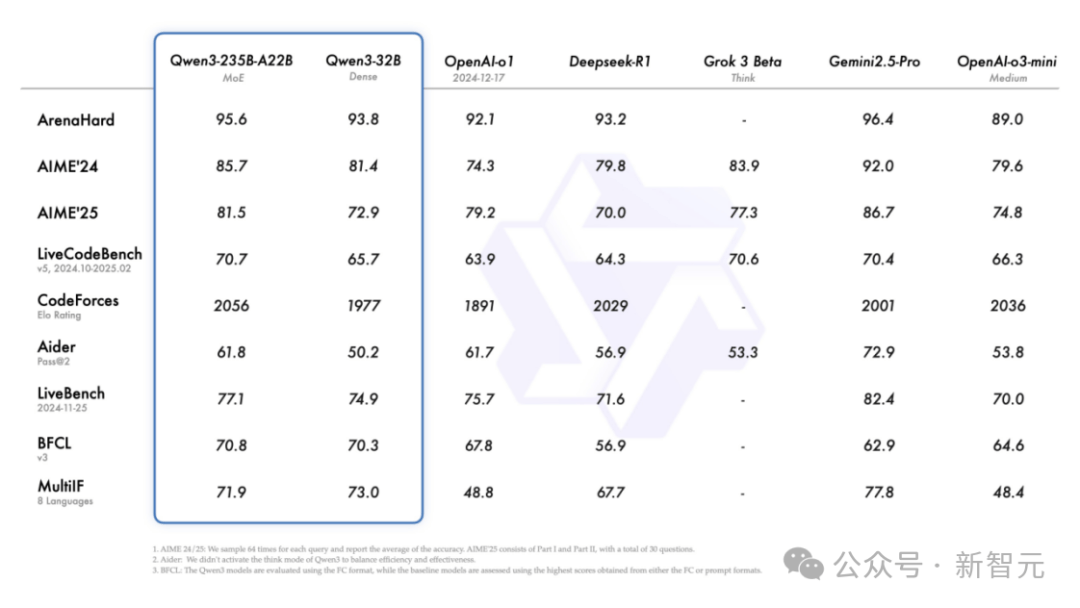
而且,性能大幅提升的同时,它的部署成本还大幅下降,仅需4张H20即可部署Qwen3满血版,显存占用仅为性能相近模型的1/3!
亮点总结:
· 各种尺寸的稠密模型和混合专家(MoE)模型,包括0.6B、1.7B、4B、8B、14B、32B以及30B-A3B和235B-A22B。
· 能够在思考模式(用于复杂的逻辑推理、数学和编码)和非思考模式(用于高效的通用聊天)之间无缝切换,从而确保在各种场景中实现最佳性能。
· 推理能力显著增强,在数学、代码生成和常识逻辑推理方面,超越了之前处于思考模式下的QwQ和处于非思考模式下的Qwen2.5 instruct模型。
· 更符合人类偏好,擅长创意写作、角色扮演、多轮对话和指令遵循,从而提供更自然、引人入胜和更真实的对话体验。
· 精通AI智能体能力,支持在思考和非思考模式下与外部工具的精确集成,并在复杂的基于智能体的任务中,在开源模型中实现了领先的性能。
· 首次支持119种语言和方言,具有强大的多语言指令跟随和翻译能力。
目前,Qwen 3已同步上线魔搭社区、Hugging Face、GitHub,并可在线体验。
全球开发者、研究机构和企业均可免费下载模型并商用,也可以通过阿里云百炼调用Qwen3的API服务。个人用户可立即通过通义APP直接体验Qwen3,夸克也即将全线接入Qwen3。
在线体验:
魔搭社区:
https://modelscope.cn/collections/Qwen3-9743180bdc6b48
Hugging Face:
https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
GitHub:
https://github.com/QwenLM/Qwen3
至此,阿里通义已开源200余个模型,全球下载量超3亿次,千问衍生模型数超10万个,彻底超越美国Llama,成为全球第一开源模型!
Qwen 3家族登场
8款「混合推理」模型全开源
这次,阿里一口气开源了8款混合推理模型,包括2款30B、235B的MoE模型,以及0.6B、1.7B、4B、8B、14B、32B等6款稠密模型,均采用 Apache 2.0许可。
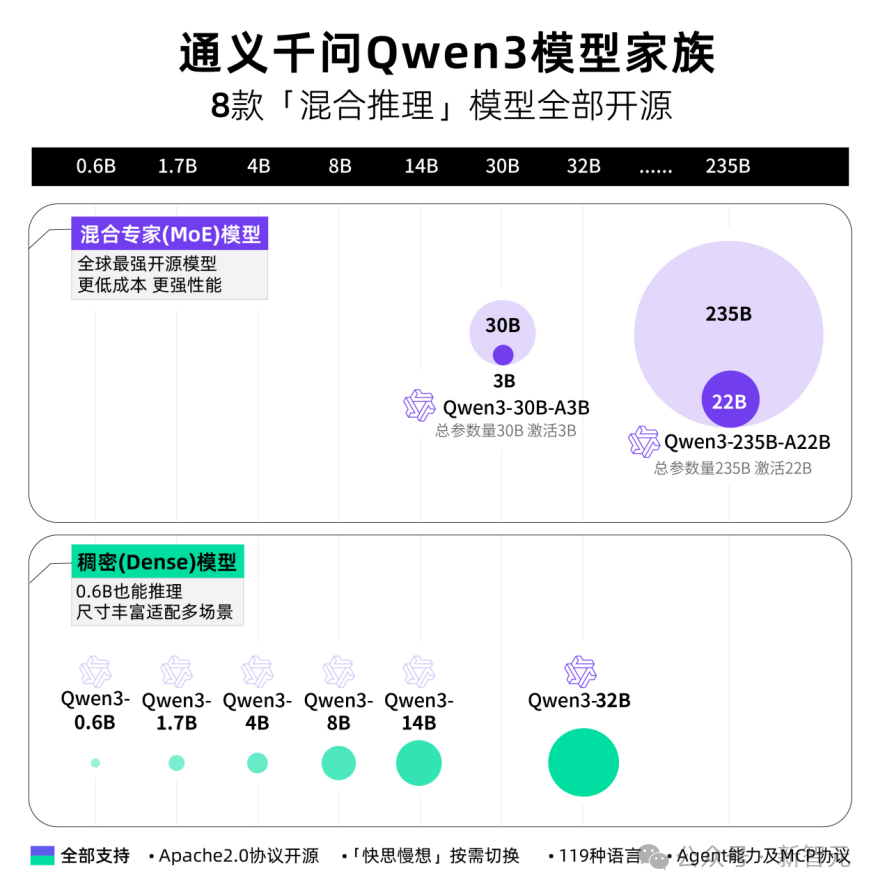
其中,每款模型均斩获同尺寸开源模型SOTA。
Qwen3的30B参数MoE模型实现了10倍以上的模型性能杠杆提升,仅激活3B就能媲美上代Qwen2.5-32B模型性能。
Qwen3的稠密模型性能继续突破,一半的参数量可实现同样的高性能,如32B版本的Qwen3模型可跨级超越Qwen2.5-72B性能。
同时,所有Qwen3模型都是混合推理模型,API可按需设置「思考预算」(即预期最大深度思考的tokens数量),进行不同程度的思考,灵活满足AI应用和不同场景对性能和成本的多样需求。
比如,4B模型是手机端的绝佳尺寸;8B可在电脑和汽车端侧丝滑部署应用;32B最受企业大规模部署欢迎,有条件的开发者也可轻松上手。
开源模型新王,刷新纪录
Qwen3在推理、指令遵循、工具调用、多语言能力等方面均大幅增强,即创下所有国产模型及全球开源模型的性能新高——
在奥数水平的AIME25测评中,Qwen3斩获81.5分,刷新开源纪录。
在考察代码能力的LiveCodeBench评测中,Qwen3突破70分大关,表现甚至超过Grok3。
在评估模型人类偏好对齐的ArenaHard测评中,Qwen3以95.6分超越了OpenAI-o1及DeepSeek-R1。

具体来说,旗舰模型 Qwen3-235B-A22B与其他顶级模型(如DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro)相比,在编码、数学、通用能力等各项基准测试中,成绩都相当亮眼。
此外,小型混合专家模型Qwen3-30B-A3B虽然激活参数只有QwQ-32B的十分之一,但性能却更胜一筹。
甚至是Qwen3-4B这样的小模型,也能媲美Qwen2.5-72B-Instruct的性能。
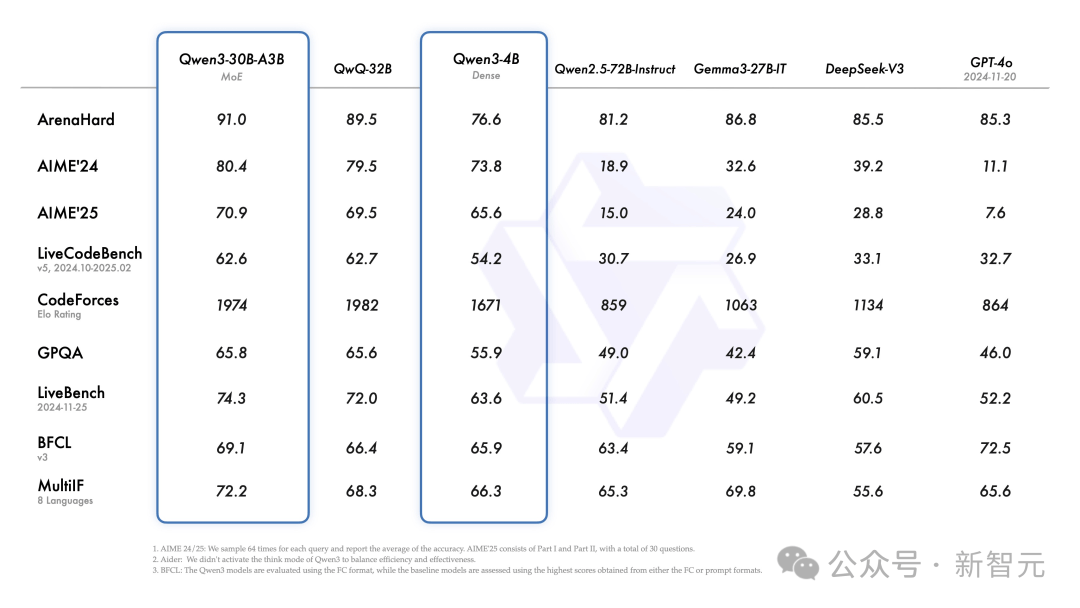
经过微调的模型,如Qwen3-30B-A3B,及其预训练版本(如 Qwen3-30B-A3B-Base),现在都可在Hugging Face、ModelScope 和Kaggle等平台上找到。
对于部署,阿里推荐使用SGLang和vLLM等框架。对于本地使用,强烈推荐Ollama、LMStudio、MLX、llama.cpp和KTransformers等工具。
无论研究、开发还是生产环境,Qwen3都可轻松集成到各种工作流程中。
利好智能体Agent和大模型应用爆发
可以说,Qwen3为即将到来的智能体Agent和大模型应用爆发提供了更好的支持。
在评估模型Agent能力的BFCL评测中,Qwen3创下70.8的新高,超越Gemini2.5-Pro、OpenAI-o1等顶尖模型,这将大幅降低Agent调用工具的门槛。
同时,Qwen3原生支持MCP协议,并具备强大的工具调用能力,结合封装了工具调用模板和工具调用解析器的Qwen-Agent框架。
这将大大降低编码复杂性,实现高效的手机及电脑Agent操作等任务。
主要特点
混合推理模式
Qwen3模型引入了一种混合问题解决方式。它们支持两种模式:
1. 思考模式:在该模式下,模型会逐步推理,然后给出答案。这适合需要深入思考的复杂问题。
2. 非思考模式:在该模式下,模型会快速给出答案,适用于对速度要求较高的简单问题。
这种灵活性,让用户可以根据任务的复杂程度,控制模型的推理过程。
例如,难题可以通过扩展推理来解决,而简单的问题可以直接回答,而不会延迟。
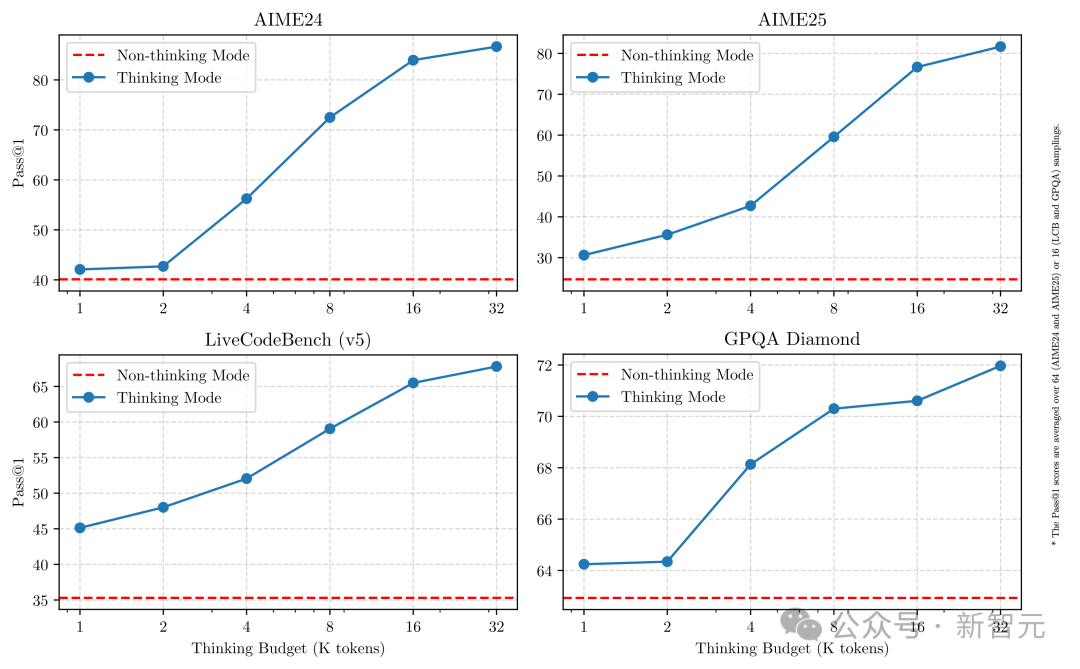
至关重要的是,这两种模式的结合,大大提高了模型稳定高效地控制推理资源的能力。
如上所示,Qwen3表现出可扩展且平滑的性能改进,这与分配的计算推理预算直接相关。
这种设计使用户能够更轻松地配置特定于任务的预算,从而在成本效率和推理质量之间实现更优化的平衡。
多语言支持
Qwen3模型支持119种语言和方言。
如此广泛的多语言能力,也意味着Qwen 3有极大潜力创建风靡全球的国际应用。
更强大的智能体能力
阿里对Qwen3模型进行了优化,以提高编码和智能体能力,并且还加强了对MCP的支持。
下面这个示例,很好地展示了Qwen3是如何思考并与环境交互的。
36万亿token,多阶段训练
作为千问系列最强模型,Qwen3究竟是如何实现如此惊艳的表现?
接下来,一起扒一扒Qwen3背后技术细节。
预训练
与Qwen2.5相比,Qwen3预训练数据集规模几乎是上一代两倍,从18万亿个token扩展到了36万亿个token。
它覆盖了119种语言和方言,不仅来源于网络,还包括从PDF等文档中提取文本内容。
为了确保数据质量,团队利用Qwen2.5-VL提取文档文本,并通过Qwen2.5优化提取内容的准确性。
此外,为了提升模型在数学和代码领域的表现,Qwen3还通过Qwen2.5-Math和Qwen2.5-Coder生成大量合成数据,包括教科书、问答对和代码片段。
Qwen3预训练过程,一共分为三个阶段,逐步提升模型的能力:
第一阶段(S1):基础语言能力构建
使用超30万亿个token,以4k上下文长度进行预训练。这一阶段为模型奠定了扎实的语言能力和通用知识基础。
第二阶段(S2):知识稠密型优化
通过增加STEM、编码和推理任务等知识稠密型数据的比例,模型在额外5万亿和token上继续训练,进一步提升专业能力的表现。
第三阶段(S3):上下文能力扩展
利用高质量上下文数据,将模型的上下文长度扩展至32k,确保其能够处理复杂、超长输入。
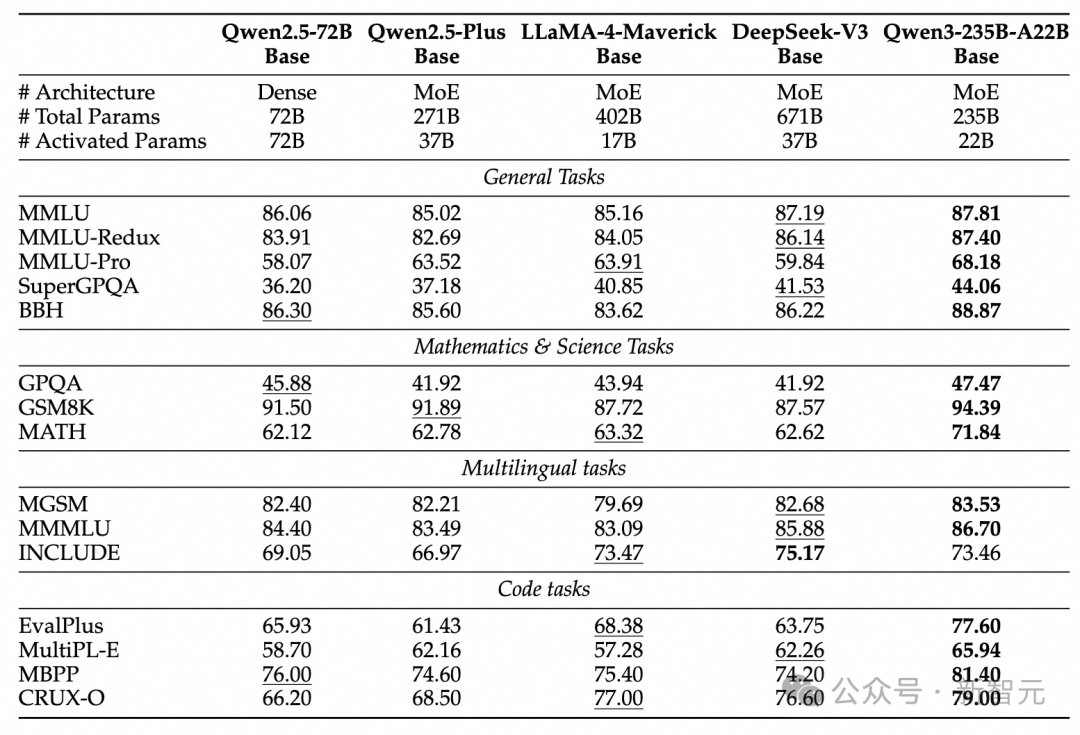
得益于模型架构优化、数据规模扩展和更高效的训练方法,Qwen3 Dense基础模型展现出亮眼的性能。
如下表所示,Qwen3-1.7B/4B/8B/14B/32B-Base可以媲美Qwen2.5-3B/7B/14B/32B/72B-Base,以更小的参数量达到更大模型的水平。
尤其是,在STEM、编码和推理等领域,Qwen3 Dense基础模型甚至优于更大的Qwen2.5模型。
更令人瞩目的是,Qwen3 MoE模型仅用10%激活参数,即可实现Qwen2.5 Dense基础模型相似的性能。
这不仅大幅降低了训练和推理成本,还为模型的实际部署提供了更高的灵活性。
后训练
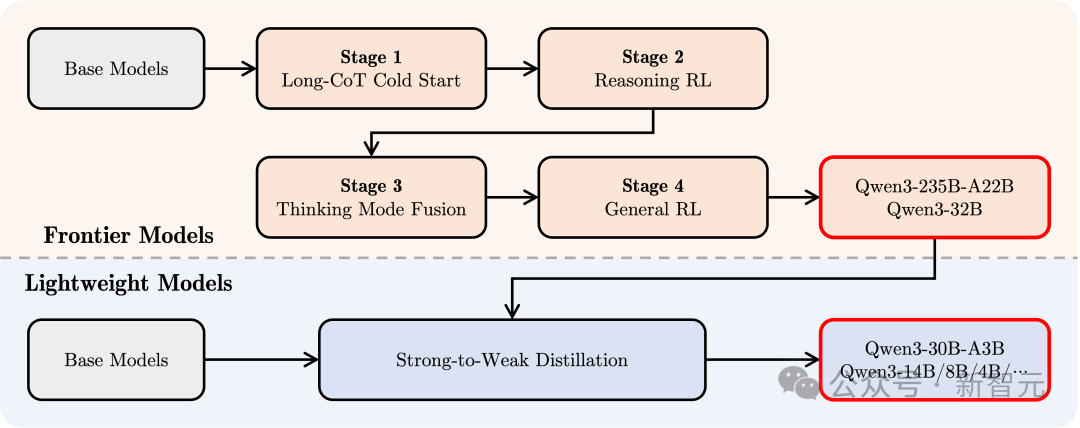
为了打造一个既能进行复杂推理,又能快速响应的混合模型,Qwen3设计了一个四阶段后训练流程。
1. 长思维链冷启动
使用多样化的长思维链数据,覆盖数学、编码、逻辑推理和STEM问题,训练模型掌握基本的推理能力。
2. 长思维链强化学习
通过扩展RL的计算资源,结合基于规则的奖励机制,提升模型在探索和利用推理路径方面的能力。
3. 思维模式融合
使用长思维链数据和指令微调数据进行微调,将快速反应能力融入推理模型,确保模型在复杂任务中既精准又高效。
此数据由第二阶段的增强思考模型生成,确保推理和快速响应能力的无缝融合。
4. 通用强化学习
在20多个通用领域任务,如指令遵循、格式遵循和智能体能力中应用RL,进一步提升模型的通用性和鲁棒性,同时纠正不良行为。
全网好评如潮
Qwen3开源不到3小时,GitHub狂揽17k星,彻底点燃了开源社区的热情。开发者们纷纷下载,开启了极速测试。
项目地址:
https://github.com/QwenLM/Qwen3
苹果工程师Awni Hannun宣布,Qwen3已经得到MLX框架支持。
而且,不论是iPhone(0.6B, 4B),还是MacBook(8B, 30B, 3B/30B MoE)、M2/M3 Ultra(22B/235B MoE)消费级设备,均可本地跑。
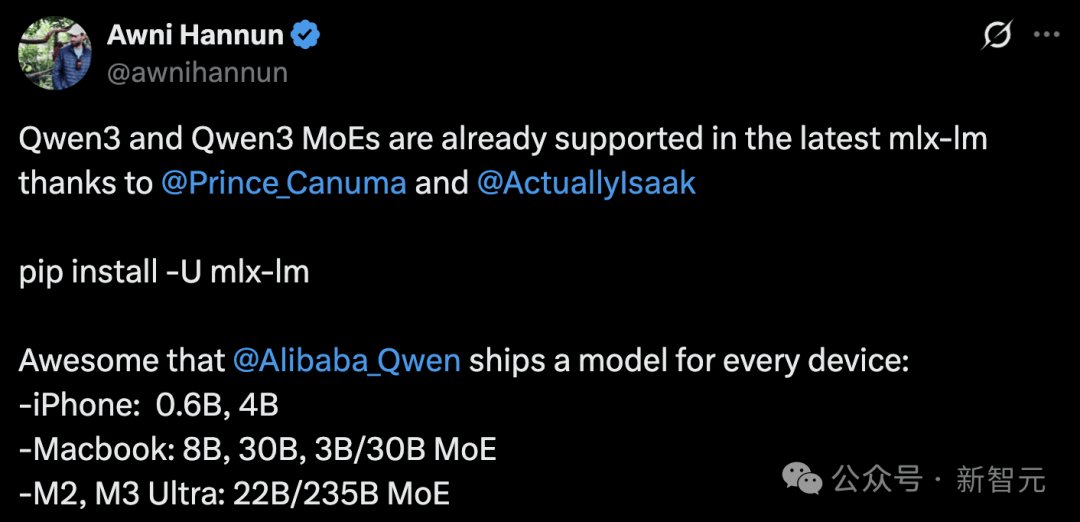
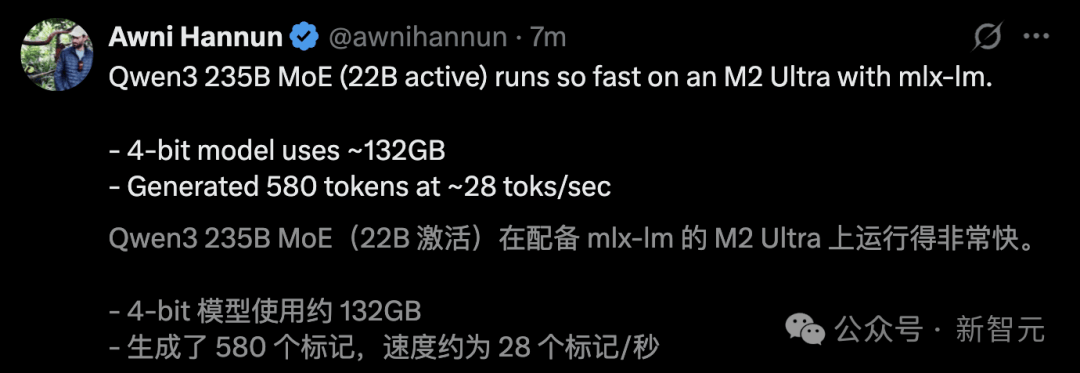
他在M2 Ultra上运行了Qwen3 235B MoE,生成速度高达28 token/s。
有网友实测后发现,与Qwen3大小相同的Llama模型,简直不在一个级别上。前者推理更深入,保持更长上下文,还能解决更难的问题。

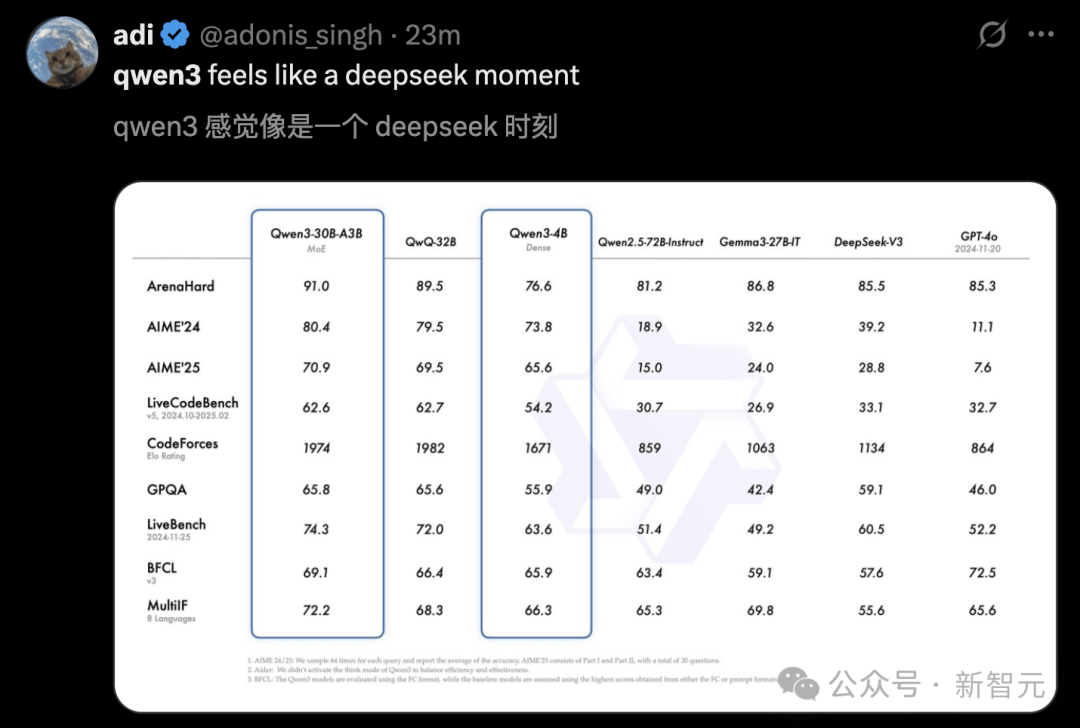
还有人表示,Qwen3就像是一个DeepSeek时刻。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







