中国的人工智能研究人员实现了许多人认为遥不可及的目标:一个免费的、开源的人工智能模型,其性能可以与或超过OpenAI最先进的推理系统。更令人瞩目的是,他们是如何做到的:通过让人工智能通过试错自我学习,类似于人类的学习方式。
“DeepSeek-R1-Zero是一个通过大规模强化学习(RL)训练的模型,没有监督微调(SFT)作为初步步骤,展现出卓越的推理能力。”研究论文中写道。
“强化学习”是一种方法,模型因做出正确决策而获得奖励,因做出错误决策而受到惩罚,而不需要知道哪个是正确的,哪个是错误的。在一系列决策之后,它学习遵循那些结果所强化的路径。
最初,在监督微调阶段,一组人类告诉模型他们想要的期望输出,给它提供上下文以了解什么是好的,什么不是。这导致了下一个阶段,即强化学习,在这个阶段,模型提供不同的输出,人类对最佳输出进行排名。这个过程反复进行,直到模型知道如何持续提供令人满意的结果。
图片:Deepseek
DeepSeek R1在人工智能发展中是一个重要的里程碑,因为人类在训练中的参与最小。与其他在大量监督数据上训练的模型不同,DeepSeek R1主要通过机械强化学习进行学习——本质上是通过实验和获取反馈来弄清楚什么有效。
“通过强化学习,DeepSeek-R1-Zero自然展现出众多强大而有趣的推理行为,”研究人员在论文中表示。该模型甚至发展出自我验证和反思等复杂能力,而这些并不是明确编程的结果。
在模型的训练过程中,它自然学会了将更多的“思考时间”分配给复杂问题,并发展出捕捉自身错误的能力。研究人员强调了一个“恍然大悟”的时刻,模型学会了重新评估其对问题的初步方法——这是它并没有被明确编程去做的事情。
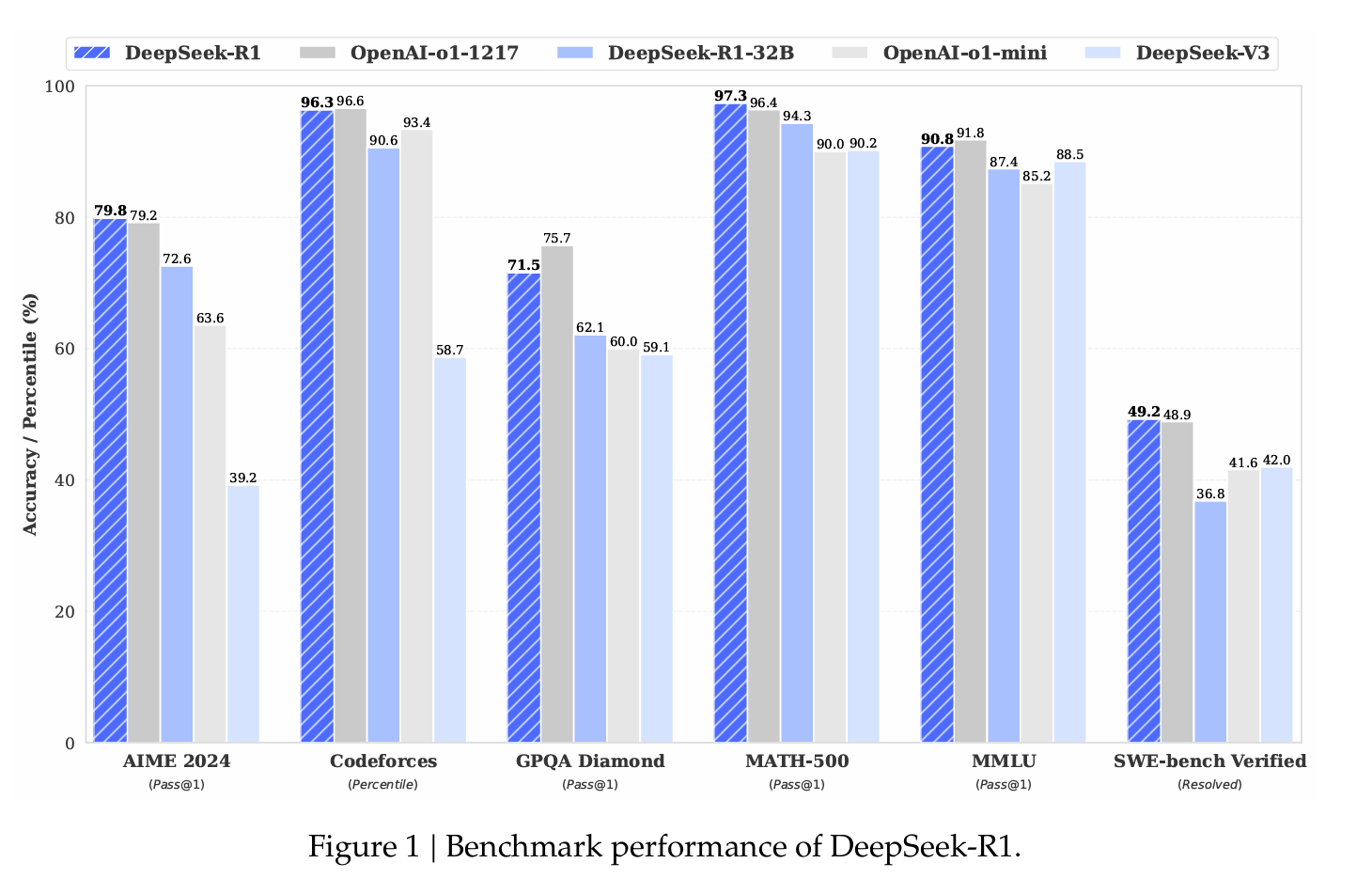
性能数据令人印象深刻。在AIME 2024数学基准测试中,DeepSeek R1达到了79.8%的成功率,超过了OpenAI的o1推理模型。在标准化编码测试中,它展示了“专家级”表现,在Codeforces上获得了2029的Elo评分,超过了96.3%的人工竞争者。
图片:Deepseek
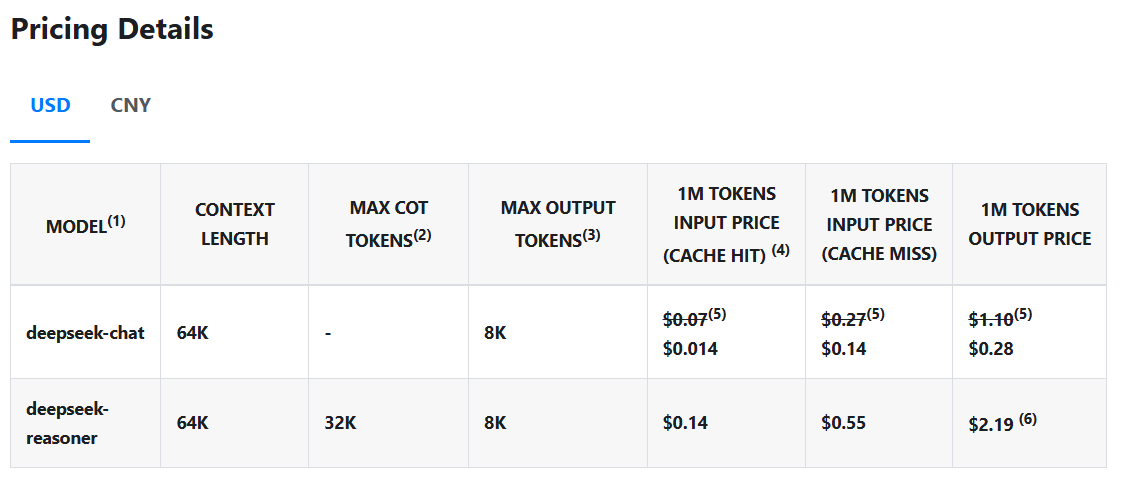
但真正使DeepSeek R1与众不同的是其成本——或者说缺乏成本。该模型的查询费用仅为$0.14每百万个标记,而OpenAI的费用为$7.50,使其便宜98%。与专有模型不同,DeepSeek R1的代码和训练方法完全开源,采用MIT许可证,这意味着任何人都可以获取该模型,使用并修改它而不受限制。
图片:Deepseek
人工智能领导者的反应
DeepSeek R1的发布引发了人工智能行业领导者的强烈反响,许多人强调了一个完全开源模型在推理能力上与专有领导者相匹配的重要性。
Nvidia的首席研究员Jim Fan博士发表了或许是最尖锐的评论,直接将其与OpenAI的初衷进行了对比。“我们生活在一个非美国公司保持OpenAI原始使命的时间线上——真正开放的前沿研究,赋能所有人,”Fan指出,赞扬DeepSeek前所未有的透明度。
Fan强调了DeepSeek强化学习方法的重要性:“他们或许是第一个展示出强化学习飞轮持续增长的开源软件项目。”他还称赞DeepSeek直接分享“原始算法和matplotlib学习曲线”,与行业中更常见的炒作驱动的公告形成对比。
苹果公司的研究员Awni Hannun提到,人们可以在自己的Mac上本地运行模型的量化版本。
传统上,由于缺乏与Nvidia的CUDA软件的兼容性,苹果设备在人工智能方面一直较弱,但这种情况似乎正在改变。例如,人工智能研究员Alex Cheema能够在8台苹果Mac Mini单元共同运行的情况下运行完整模型——这仍然比运行当前最强大的人工智能模型所需的服务器便宜。
也就是说,用户可以在他们的Mac上运行DeepSeek R1的轻量版本,且具有良好的准确性和效率。
然而,最有趣的反应是在思考开源行业与专有模型之间的接近程度,以及这一发展可能对OpenAI作为推理人工智能模型领域领导者的潜在影响后产生的。
Stability AI的创始人Emad Mostaque采取了挑衅的立场,暗示这一发布给资金更充足的竞争对手施加了压力:“你能想象成为一个筹集了十亿美元的前沿实验室,现在你无法发布最新模型,因为它无法击败DeepSeek吗?”
同样的推理,但以更严肃的论证,科技企业家Arnaud Bertrand解释说,竞争性开源模型的出现可能对OpenAI造成潜在伤害,因为这使得其模型对那些可能愿意为每个任务花费大量资金的高级用户吸引力下降。
“这就好像有人发布了一款与iPhone相当的手机,但售价为30美元而不是1000美元。这是如此戏剧化。”
Perplexity AI的首席执行官Arvind Srinivas从市场影响的角度框定了这一发布:“DeepSeek在很大程度上复制了o1 mini,并将其开源。”在后续观察中,他指出了进展的快速步伐:“看到推理如此迅速地商品化真是有点疯狂。”
Srinivas表示,他的团队将致力于将DeepSeek R1的推理能力带入未来的Perplexity Pro中。
快速上手
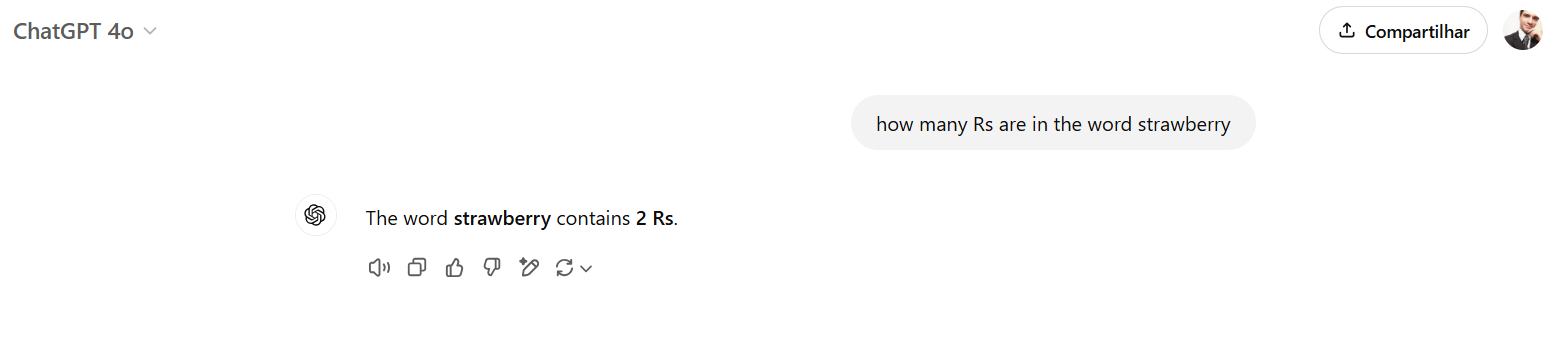
我们进行了一些快速测试,将该模型与OpenAI o1进行比较,从一个众所周知的问题开始:“草莓这个词中有多少个R?”
通常,模型很难提供正确答案,因为它们并不是处理单词——而是处理标记,即概念的数字表示。
GPT-4o失败了,OpenAI o1成功了——DeepSeek R1也是如此。
然而,o1在推理过程中非常简洁,而DeepSeek则应用了较重的推理输出。有趣的是,DeepSeek的回答感觉更像人类。在推理过程中,模型似乎在自言自语,使用了俚语和机器上不常见但人类更广泛使用的词汇。
例如,在反思R的数量时,模型对自己说:“好吧,让我弄清楚(这个)。”它在辩论时也使用了“Hmmm”,甚至说了“等一下,不。等一下,让我们分解一下。”

该模型最终达到了正确的结果,但花费了大量时间进行推理和输出标记。在典型的定价条件下,这将是一个劣势;但考虑到目前的情况,它可以输出比OpenAI o1更多的标记,并且仍然具有竞争力。
另一个测试模型推理能力的方法是玩“间谍”游戏,识别短故事中的罪犯。我们从Github上的BIG-bench数据集中选择了一个样本。(完整故事可在这里获取,涉及一次前往偏远雪地的学校旅行,学生和老师面临一系列奇怪的失踪事件,模型必须找出谁是跟踪者。)
两个模型都思考了超过一分钟。然而,ChatGPT在解决谜题之前崩溃了:
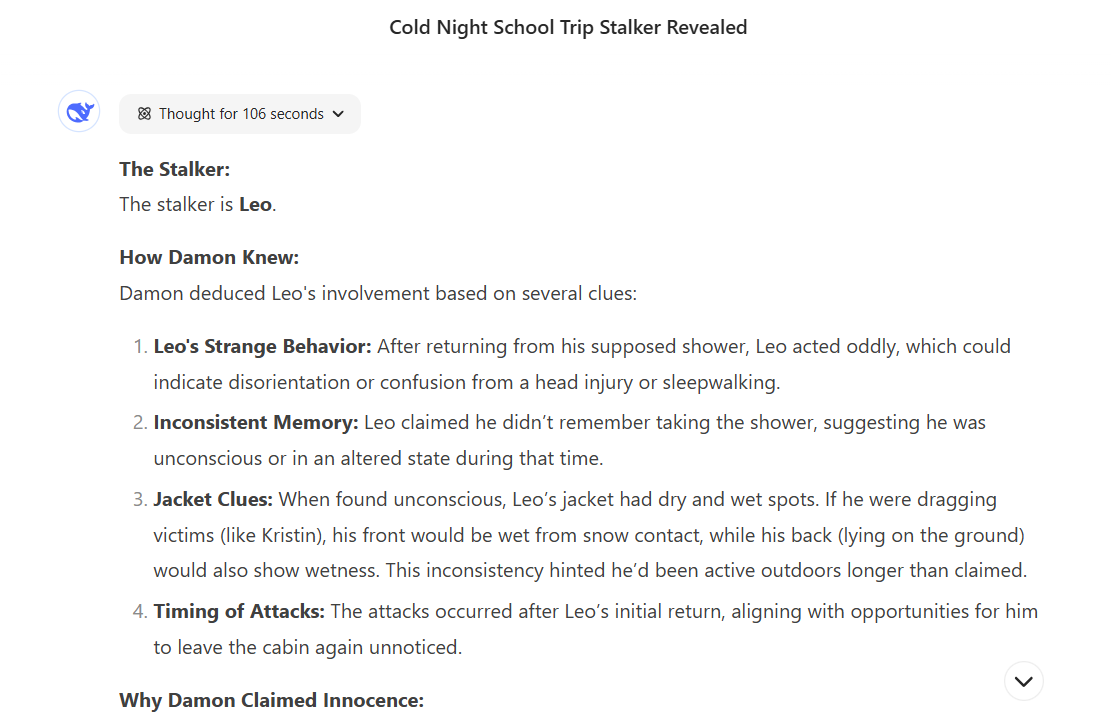
但DeepSeek在“思考”了106秒后给出了正确答案。思考过程是正确的,模型甚至能够在得出错误(但仍然足够合逻辑)结论后自我纠正。
较小版本的可访问性特别给研究人员留下了深刻印象。作为背景,1.5B模型如此小,以至于理论上可以在强大的智能手机上本地运行。根据Hugging Face的数据科学家Vaibhav Srivastav的说法,甚至一个如此小的Deepseek R1量化版本也能够与GPT-4o和Claude 3.5 Sonnet正面交锋。
就在一周前,加州大学伯克利分校的SkyNove发布了Sky T1,这是一种推理模型,也能够与OpenAI o1预览版竞争。
有兴趣在本地运行该模型的用户可以从Github或Hugging Face下载。用户可以下载、运行、去除审查,或通过微调将其适应不同的专业领域。
或者,如果您想在线尝试该模型,可以访问Hugging Chat或DeepSeek的Web Portal,这是ChatGPT的一个不错替代品——尤其是因为它是免费的、开源的,并且是唯一一个除了ChatGPT之外为推理构建的模型的AI聊天机器人界面。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






