Stability AI 可能正在开始它自己的救赎之路。在 SD3 Medium 令人失望之后,他们通过发布两个新模型重新振作,这两个模型在 七月时就已承诺:Stable Diffusion 3.5 Large 和 Stable Diffusion 3.5 Large Turbo。
“在六月,我们发布了 Stable Diffusion 3 Medium,这是 Stable Diffusion 3 系列的首次公开发布。这个版本没有完全达到我们的标准或我们社区的期望,”Stability 在 官方博客文章 中表示。“在听取了宝贵的社区反馈后,我们没有选择快速修复,而是花时间进一步开发一个版本,以推进我们转变视觉媒体的使命。”
我们生成了一些图像来尝试一下,然后才匆忙撰写这条突发新闻——结果相当不错。尤其是作为基础模型。
SD 3.5 家族旨在运行在消费级系统上——即使在某些标准下也算是低端——使得高级图像生成比以往任何时候都更容易获得。是的,他们听到了关于之前版本的抱怨,因此这一版本承诺会好得多——如此之多,以至于他们的特色图像是一位躺在草地上的女性, 这是对早前同样挑战所引发的恐怖场景 的讽刺。

图片:Stability AI
此次发布的另一个重要方面是新的许可模型。Stable Diffusion 3.5 采用了更宽松的许可,允许商业和非商业使用。小型企业和从该工具中获得收入少于 1,000,000 美元的人可以免费使用和构建这些模型。
收入较高的人必须联系 Stability 以协商费用。相比之下,Black Forest Labs 提供 其低端的 Flux Schnell 免费,其中级模型 Flux Dev 在非商业使用下免费,而其 SOTA 模型 Flux Pro 是一个 闭源模型。 (作为参考,Flux 通常被认为是目前可用的最佳开源图像生成器——至少在当前的后 SDXL 时代。)
Stable Diffusion 3.5 的内容是什么?
Stability AI 正在发布三种版本的 Stable Diffusion 3.5,所有这些版本都满足不同的需求:
Stable Diffusion 3.5 Large:这是大版本,具有 80 亿个参数,旨在提供一流的图像质量和严格的提示遵循。它适用于专业使用,特别是在 1 兆像素分辨率下,但可以处理多种风格和视觉格式。
Stable Diffusion 3.5 Large Turbo:对于那些想要在质量和速度之间做出一些妥协的人来说,这个精简版的大模型是你的首选。它只需四个步骤就能生成高质量图像——与正常的 SD3.5 需要大约 30 步才能生成良好质量的图像不同。它相当于 Flux Schell。
Stable Diffusion 3.5 Medium:即将推出,这个模型具有 25 亿个参数,并针对消费硬件进行了优化。它是需要在 0.25 到 2 兆像素分辨率之间提供稳定性能的用户的中间选择,而不牺牲定制的便利性。
这些模型更加灵活,允许用户根据特定的创意需求进行微调。如果你担心你的消费级 GPU 是否能处理这些,Stability AI 会为你提供支持。我们的测试显示,Large Turbo 在一台配备 6GB VRAM 的普通 RTX 2060 上大约需要 40 秒就能生成图像。


未量化的完整版本在同样的低端硬件上需要超过 3 分钟,但这是质量的代价。
内部改进
Stability AI 正在追赶 Flux,后者是定制化的首选模型。为了改善用户体验,Stability 重新构想了 SD 3.5 的行为。“在开发模型时,我们优先考虑了可定制性,以提供一个灵活的基础进行构建。为此,我们将查询-键归一化集成到变换器块中,稳定了模型训练过程,并简化了进一步的微调和开发,”Stability 说。
换句话说,无论你是想要创建自定义风格的艺术家,还是希望构建 AI 驱动应用程序的开发者,你都可以比以前更轻松地调整和完善这些模型。Stability 甚至分享了一份 LoRA 训练指南,帮助你更快地启动。
LoRA(低秩适应)是一种微调模型以专注于特定概念的技术——无论是风格还是主题——而无需重新训练整个大型基础模型。

说明:没有 LoRA 的同一生成与使用 LoRA 添加更多细节的对比。图片来源:Civitai
当然,灵活性带来了一些权衡。模型现在变得如此创造性,以至于 Stability 警告说“缺乏特异性的提示可能导致输出的不确定性增加,审美水平可能会有所不同”。
如果你仍然对 Stable Diffusion 3.5 感到犹豫,而它的“不确定性”让你退却,这里有一点未来保障——它支持“负提示”,这意味着你的提示可以包含不做某事的指令。这对那些希望在不费力的情况下精炼文本和图像生成的人来说是一个巨大的好处。
对于那些希望对生成结果有更多控制的人来说,这是一个不错的补充。此外,它似乎在处理传统的 SDXL 提示风格方面表现良好。事实上,在某些方面,SD3.5 的提示风格更接近 MidJourney 而非 Flux,使用户能够创造性地发挥,而无需 语言学学位。
除了定制化,Stable Diffusion 3.5 在其他领域也有所进展:
- 提示遵循:Large 模型在遵循用户输入方面现在甚至可以与更大的模型相媲美,并且在图像生成器的世界中处于领先地位。以至于 Stability 确保 SD 3.5 large 在提示遵循方面优于 Flux.1 Dev——尽管在审美质量上仍然不及。
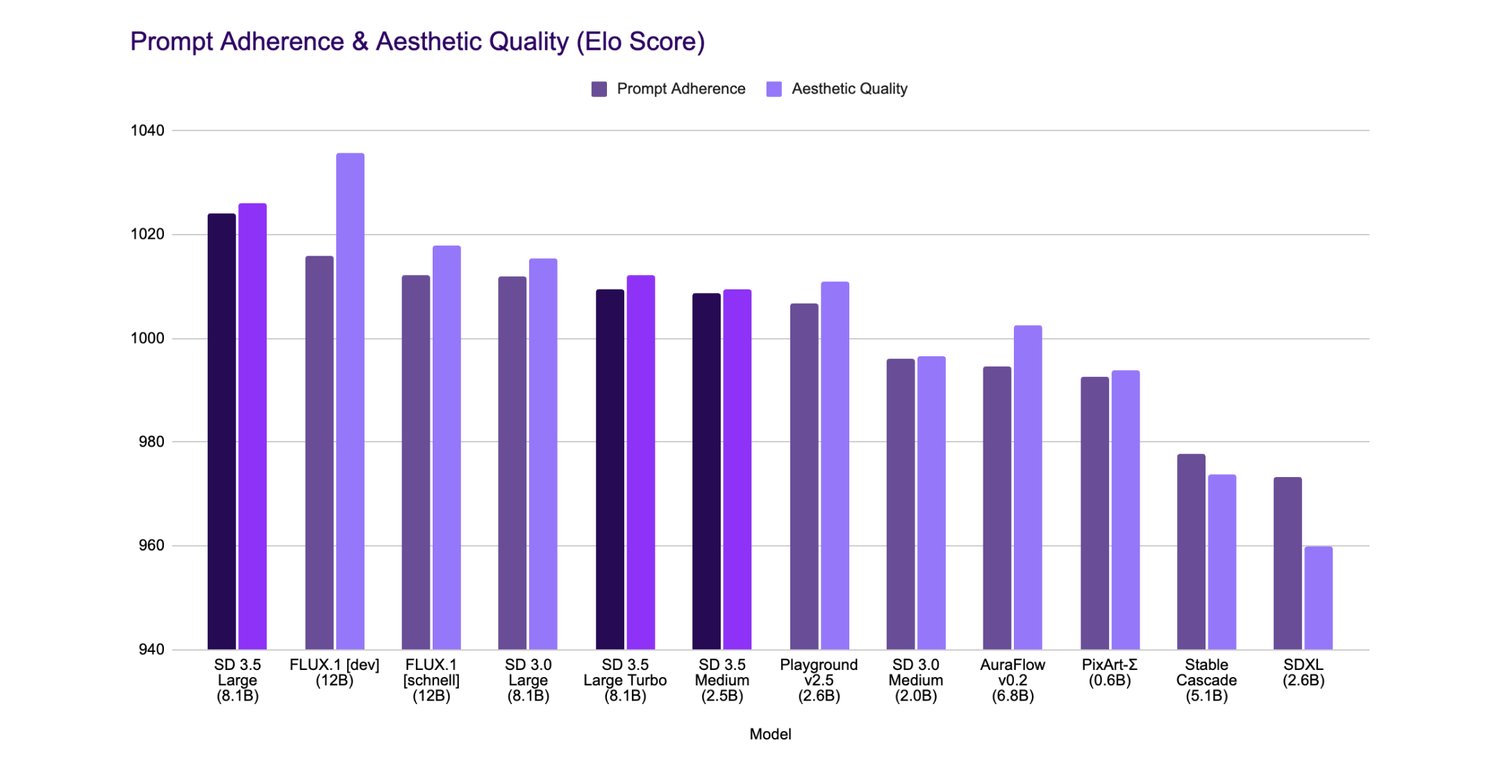
图片:Stability AI
图像质量:我们谈论的是生成能够与一些最耗资源的模型相媲美的图像,而不会消耗过多的 GPU 内存。在 Stability 的基准测试中,Flux.1 Dev 略微领先,但 SD 3.5 Large 更高效且资源占用更少。SD 3.5 Large Turbo 在遵循性和质量上可与 Flux.1 Schnell 相媲美。
风格多样性:无论你是想要 3D 渲染、照片真实感图像、线条艺术还是绘画风格,Stable Diffusion 3.5 都能应对。它处理的风格范围比 Flux 更广——至少在我们的快速测试中是这样。
确实值得一提的是——它没有审查。SD3.5 Large 可以生成某些类型的内容,包括裸体,尽管这并不完美。无论好坏,该模型并没有故意限制,因此为用户提供了完全的创作自由(尽管为了获得最佳效果,可能需要微调和一些特定的提示)。
当 SD3 发布时,这一点受到了严重批评,并被指出是其在解剖理解方面失败的主要原因之一。我们可以确认它生成 NSFW 图像的能力,然而,该模型并不在最佳 Flux 微调的同一水平上,但与原始 Flux 模型相当。
但请注意:尽管 SD3.5 功能强大,你们这些 NSFW Furry 艺术家不应该指望很快会有 Pony Diffusion 模型——或者根本不会。最受欢迎和强大的 NSFW 模型的创作者确认他们对开发 SD3.5 微调不感兴趣。相反,他们选择以 Auraflow 为基础构建他们的模型。一旦完成,他们可能会考虑 Flux。
对于那些喜欢 tinkering 的人,ComfyUI 现在支持 Stable Diffusion 3.5,允许使用基于节点的工作流进行本地推理。有很多现成的工作流示例,如果你在 RAM 较低的情况下挣扎,但想尝试完整的 SD3.5 体验,Comfy 推出了一个实验性的 fp8 缩放模型,可以降低内存使用。
接下来是什么?
在 10 月 29 日,我们将获得 Stable Diffusion 3.5 Medium 的使用权,不久之后 Stability 承诺将为 SD 3.5 发布 Control Nets。
ControlNets 承诺带来先进的控制功能,专为专业用例量身定制,它们很可能将 SD3.5 的能力提升到一个新的水平。如果你想了解更多,可以阅读我们关于 SD 1.5 的简要指南 的总结。然而,使用 ControlNets 将使用户能够选择主题的姿势、玩弄深度图、根据涂鸦重新构想场景等。

原始图像与使用 Controlnet 影响主题姿势的生成图像。图片来源:Jose Lanz
那么,Stable Diffusion 3.5 是 Flux 杀手吗?还不是,但它确实开始看起来像一个竞争者。一些用户仍然会 挑剔,尤其是在 SD3 Medium 失败的戏剧之后。但随着解剖处理的改善、更清晰的许可以及在提示遵循性和输出质量方面的显著提升,很难争辩这不是一个巨大的进步。Stability AI 正在从过去的错误中学习,朝着一个更先进的 AI 工具对所有人更可及的未来迈进。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






