"Starting from open-source papers and open-source code, has it now evolved into an open-source thinking chain?"
Author: Andrew Lu, Team Late Point

Image source: Generated by Boundless AI
On February 18, Kimi and DeepSeek both released new advancements on the same day, namely MoBA and NSA, both of which are improvements on the "Attention Mechanism."
Today, one of the main developers of MoBA, Andrew Lu, posted on Zhihu, recounting three pitfalls he encountered during the development process, which he referred to as "three entries into the cliff of reflection." His signature on Zhihu is "New LLM Trainer."
A comment under this response reads: "Starting from open-source papers and open-source code, has it now evolved into an open-source thinking chain?"
The importance of the attention mechanism lies in the fact that it is the core mechanism of current large language models (LLMs). Going back to the Transformer paper that initiated the LLM revolution in June 2017, the title was: Attention Is All You Need, which has been cited over 153,000 times to date.
The attention mechanism allows AI models to know, like humans, what to "focus on" and what to "ignore" when processing information, capturing the most critical parts of the information.
The attention mechanism plays a role during both the training phase and the inference phase of large models. Its general working principle is that when a piece of data is input, such as "I like to eat apples," the large model calculates the relationship of each word (Token) in the sentence with other words to understand semantic information.
As the context that the large model needs to process becomes longer, the Full Attention mechanism originally adopted by the standard Transformer becomes intolerable in terms of computational resource usage. This is because the initial process requires calculating the importance scores of all input words and then weighted calculations to determine which words are the most important, leading to a computational complexity that grows quadratically (non-linearly) with the length of the text. As stated in the "Abstract" section of the MoBA paper:
"The inherent quadratic increase in computational complexity of traditional attention mechanisms brings daunting computational costs."
At the same time, researchers are pursuing the ability for large models to handle sufficiently long contexts—multi-turn dialogues, complex reasoning, memory capabilities… These characteristics that AGI should possess require longer context capabilities.
Finding an optimization method for the attention mechanism that does not consume excessive computational resources and memory while not sacrificing model performance has thus become an important topic in large model research.
This is the technical background behind several companies converging on "attention."
In addition to DeepSeek's NSA and Kimi's MoBA, in mid-January of this year, another Chinese large model startup, MiniMax, also implemented a new attention mechanism on a large scale in its first open-source model, MiniMax-01. MiniMax's founder, Yan Junjie, told us at the time that this was one of the main innovations of MiniMax-01.
The co-founder of Wallface Intelligence and associate professor in the Department of Computer Science at Tsinghua University, Liu Zhiyuan, also published InfLLM in 2024, which also involves a sparse attention improvement, and this paper has been cited by the NSA paper.
Among these results, the attention mechanisms in NSA, MoBA, and InfLLM all belong to "Sparse Attention Mechanisms"; while MiniMax-01's attempt is primarily in another direction: "Linear Attention Mechanism."
One of the authors of SeerAttention, Microsoft Research Asia senior researcher Cao Shijie, told us: Overall, the linear attention mechanism makes more and more radical changes to the standard attention mechanism, aiming to directly solve the problem of quadratic explosion in computation as the text length increases (hence it is non-linear). A possible cost of this could be the loss of capturing complex dependencies in long contexts; the sparse attention mechanism, on the other hand, attempts to find a more robust optimization method by utilizing the inherent sparsity of attention.
At the same time, I would like to recommend Cao Shijie's highly praised answer on Zhihu regarding the attention mechanism: https://www.zhihu.com/people/cao-shi-jie-67/answers
(He answered the question: "What information is worth paying attention to in the new DeepSeek paper NSA attention mechanism published by Liang Wenfeng? What impact will it have?")
Fu Tianyu, a PhD student at Tsinghua University's NICS-EFC laboratory and a co-author of MoA (Mixture of Sparse Attention), said that under the broad direction of sparse attention mechanisms: "Both NSA and MoBA introduced dynamic attention methods, which can dynamically select the KV Cache blocks that need to compute fine-grained attention. Compared to some sparse attention mechanisms that use static methods, this can improve model performance. Both methods also introduced sparse attention during model training, rather than only during inference, which further enhances model performance."
(Note: The KV Cache block is a cache that stores previously computed Key labels and Value values; where Key labels refer to identification tags used in attention mechanism-related calculations to identify data features or data locations, so that when calculating attention weights, they can match and associate with other data. The Value values correspond to the Key labels and usually contain the actual data content to be processed, such as semantic vectors of words or phrases.)
At the same time, this time, the Dark Side of the Moon not only released a detailed technical paper on MoBA but also published the MoBA project code on GitHub. This set of code has been in online use in the Dark Side of the Moon's own product Kimi for over a year.
* The following is Andrew Lu's self-narration on Zhihu, authorized by the author. The original text contains many AI terms, and the gray text in parentheses is an editor's note. Original post link: https://www.zhihu.com/people/deer-andrew
Andrew Lu's R&D Narrative
At the invitation of Professor Zhang (Assistant Professor at Tsinghua University), I am here to share the ups and downs of my journey in developing MoBA, which I jokingly refer to as "three entries into the cliff of reflection." (Andrew Lu's response was to the question: "How do you evaluate Kimi's open-source sparse attention framework MoBA? What highlights do both it and DeepSeek's NSA have?")
The Beginning of MoBA
The MoBA project started very early, shortly after the Dark Side of the Moon was established at the end of May 2023. On my first day of work, I was pulled into a small room by Tim (co-founder of the Dark Side of the Moon, Zhou Xinyu) to start working on Long Context Training with Professor Qiu (Qiu Jiezhong from Zhejiang University / Zhijiang Laboratory, the proposer of the MoBA idea) and Dylan (a researcher at the Dark Side of the Moon). I would like to thank Tim for his patience and guidance, as he had high hopes for a newcomer to LLM and was willing to cultivate me. Many of the big shots involved in developing various online models and model-related technologies, like me, were basically starting from scratch with LLM.
At that time, the general level in the industry was not very high; everyone was working with 4K pre-training (the model could handle input and output lengths of about 4000 tokens, a few thousand Chinese characters). The project initially was called 16K on 16B, meaning to perform 16K length pre-training on a 16B (160 billion parameters) model. However, this requirement quickly changed in August to needing to support 128K pre-training. This was the first requirement in the design of MoBA: to quickly train a model that could support 128K length from scratch, without needing to continue training on an already trained model.
This raises an interesting question: in May/June 2023, the industry generally believed that training on long texts (directly using long texts to train the model) would yield better results than training a shorter model and then trying to extend it. This perception only changed when long Llama (a large model developed by Meta that supports long text processing) appeared in the second half of 2023. We also conducted strict validations, and in fact, short text training + length activation had better token efficiency (the effective information contribution per token increased, meaning the model could achieve higher quality tasks with fewer tokens). Naturally, the first function designed in MoBA became a tear of the times.
During this period, the structural design of MoBA was also more "radical." Compared to the current "simplified" results, the initially proposed MoBA was a two-layer attention mechanism serial scheme with cross attention (an attention mechanism that processes the relationship between two different text data segments). The gate (which controls how input data is weighted across various expert networks) itself was a non-parametric structure (no parameters, no need for data training), but to better learn historical tokens, we added a cross attention and corresponding parameters between each Transformer layer (to better remember historical information). At this point, the MoBA design had already incorporated the Context Parallel idea that everyone is familiar with (the complete context sequence is stored across different nodes and only concentrated when needed for computation). We laid out the entire context sequence across data parallel nodes, treating the context within each data parallel node as an expert in a Mixture of Experts (MoE) system, sending tokens that needed attention to the corresponding expert for cross attention and then communicating the results back. We integrated the work of fastmoe (an early MoE training framework) into Megatron-LM (a now widely used large model training framework from Nvidia) to support communication capabilities between experts.
We referred to this idea as MoBA v0.5.
(Editor's note: The inspiration for MoBA comes from the current mainstream large model MoE structure. MoE refers to the fact that when large models operate, only a portion of the expert parameters are activated each time, rather than all, thus saving computational power; the core idea of MoBA is "only look at the most relevant context each time, rather than all context, thus saving computation and cost.")
As time progressed to early August 2023, the main model's Pre-Train had already trained a large number of tokens, making another round costly. This marked the first entry of MoBA, which significantly changed its structure and added extra parameters, into the cliff of reflection.
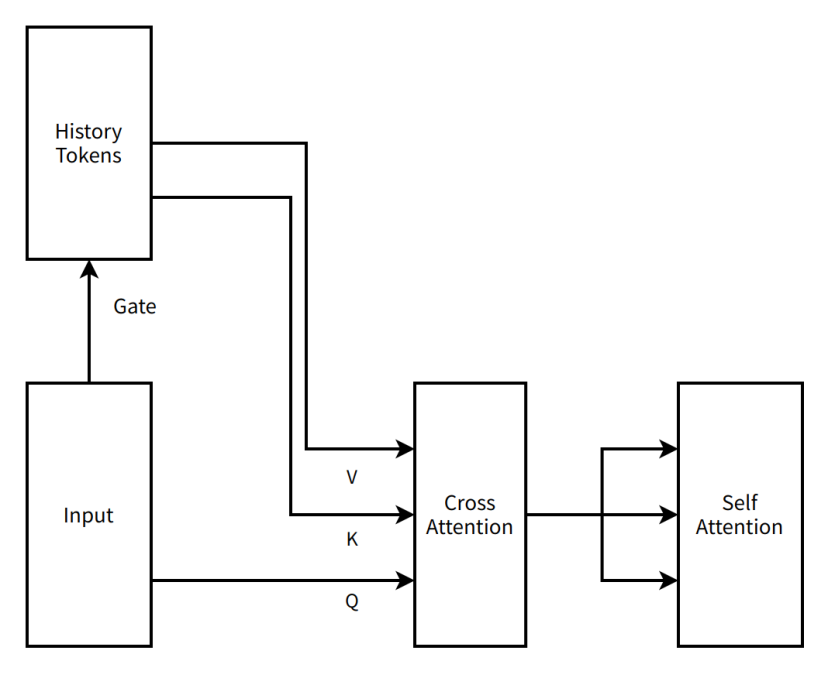
A very simple diagram of MoBA v0.5
Editor’s note:
History Tokens — In natural language processing and other scenarios, this represents a collection of previously processed text units.
Gate — A structure in neural networks used to control the flow of information.
Input — The data or information received by the model.
V (Value) — In the attention mechanism, this contains the actual data content to be processed or focused on, such as semantic vectors.
K (Key) — In the attention mechanism, this is an identification label used to mark data features or locations, allowing it to match and associate with other data.
Q (Query) — In the attention mechanism, this is a vector used to retrieve relevant information from key-value pairs.
Cross Attention — A type of attention mechanism that focuses on inputs from different sources, such as associating inputs with historical information.
Self Attention — A type of attention mechanism where the model focuses on its own input, capturing internal dependencies within the input.
First Entry into the Cliff of Reflection
Entering the cliff of reflection is, of course, a playful term; it is a time to stop and seek improvement solutions, as well as a time to deeply understand the new structure. The first time entering the cliff of reflection was quick to enter and quick to exit. Tim, as the idea king of the Dark Side of the Moon, came up with a new improvement idea, transforming MoBA from a serial two-layer attention scheme to a parallel single-layer attention scheme. MoBA no longer increased additional model parameters but instead utilized existing attention mechanism parameters to learn all information within a sequence simultaneously, allowing for Continue Training without significantly altering the current structure.
We referred to this idea as MoBA v1.
MoBA v1 was actually a product of Sparse Attention Context Parallel. At that time, Context Parallel was not widely adopted, and MoBA v1 demonstrated extremely high end-to-end acceleration capabilities. After validating its effectiveness on 3B and 7B models, we hit a wall at larger model scales, encountering significant loss spikes during training (anomalies that occur during model training). Our initial method of merging block attention output was too simplistic, merely summing up, which made it impossible to debug against Full Attention. Debugging without ground truth (the standard answer, referring to the results of Full Attention) was extremely difficult, and we exhausted various stability techniques available at the time without resolution. Due to issues arising from training on larger models, MoBA entered the cliff of reflection for the second time.
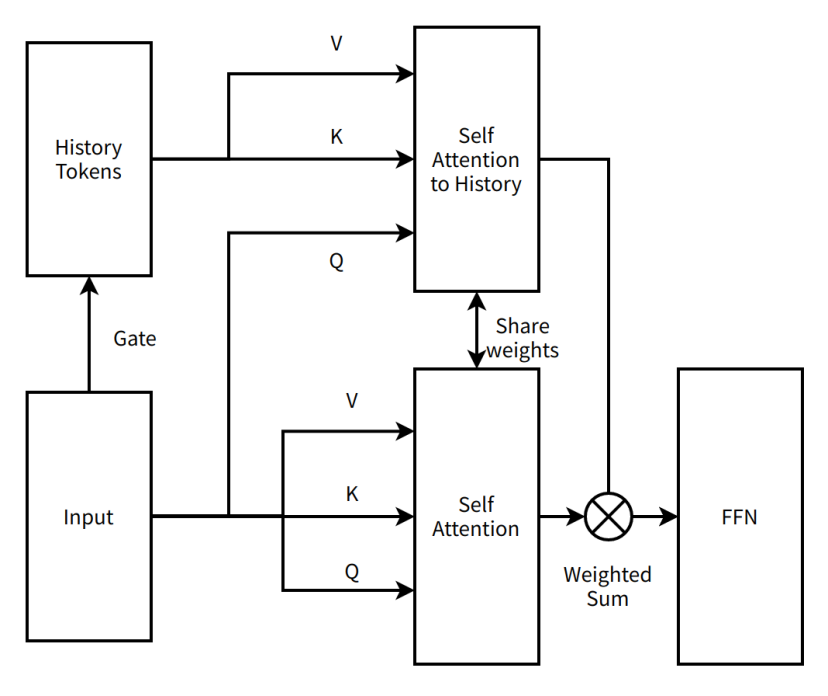
A very simple diagram of MoBA v1
Editor’s note:
Self Attention to History — A type of attention mechanism where the model focuses on historical tokens, capturing the dependencies between the current input and historical information.
Share weights — Different parts of a neural network use the same weight parameters to reduce the number of parameters and improve model generalization.
FFN (Feed-Forward Neural Network) — A basic neural network structure where data flows in a single direction from the input layer through hidden layers to the output layer.
Weighted Sum — An operation that sums multiple values according to their respective weights.
Second Entry into the Cliff of Reflection
The second stay in the cliff of reflection lasted longer, starting in September 2023 and extending until early 2024 when we finally exited. However, being in the cliff of reflection did not mean being abandoned; I experienced the second major characteristic of working at the Dark Side of the Moon: saturated rescue.
In addition to Tim and Professor Qiu, who were consistently outputting strong ideas, Su Jianlin (a researcher at the Dark Side of the Moon), Liu Jingyuan (a researcher at the Dark Side of the Moon), and various other experts participated in intense discussions, beginning to dismantle and correct MoBA. The first thing to be corrected was the simple Weighted Sum aggregation. After trying various methods of multiplying and adding with the Gate Matrix, Tim pulled out Online Softmax from the archives (which allows processing one data point at a time rather than requiring all data to compute), suggesting that this should work. One of the biggest benefits of using Online Softmax was that we could reduce sparsity to 0 (selecting all blocks), allowing for strict debugging against a mathematically equivalent Full Attention, which resolved many of the challenges encountered in implementation. However, the design of splitting contexts across data parallel nodes still led to imbalance issues. After distributing a data sample across data parallel nodes, the first few tokens on the first data parallel rank would be attended to by a vast number of subsequent Qs, resulting in poor balance and slowing down acceleration efficiency. This phenomenon is also known by a more widely recognized name — Attention Sink.
At this point, Professor Zhang visited, and after hearing our thoughts, proposed a new idea: to separate Context Parallel capabilities from MoBA. Context Parallel is Context Parallel, and MoBA is MoBA. MoBA should return to being a Sparse Attention mechanism itself rather than a distributed Sparse Attention training framework. As long as the GPU memory can accommodate it, we could completely handle all contexts on a single machine, using MoBA for computational acceleration and organizing and transmitting context between machines through Context Parallel. Thus, we re-implemented MoBA v2, which closely resembled the MoBA that everyone sees today.
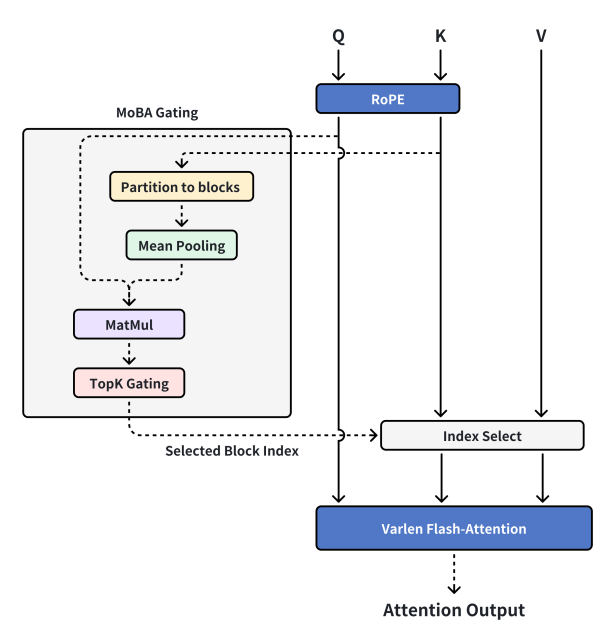
The current design of MoBA
Editor’s note:
MoBA Gating — A specific gating mechanism within MoBA.
RoPE (Rotary Position Embedding) — A technique for adding positional information to sequences.
Partition to blocks — Dividing data into different blocks.
Mean Pooling — An operation in deep learning for downsampling data by calculating the average value within a region.
MatMul (Matrix-Multiply) — A mathematical operation used to compute the product of two matrices.
TopK Gating — A gating mechanism that selects the top K important elements.
Selected Block Index — Indicates the number of the selected block.
Index Select — Selecting corresponding elements from data based on indices.
Varlen Flash-Attention — An attention mechanism suitable for variable-length sequences with high computational efficiency.
Attention Output — The output results after the attention mechanism calculations.
MoBA v2 was stable and trainable, aligning perfectly with short texts and Full Attention, and the Scaling Law appeared very reliable, smoothly supporting deployment to online models. We therefore added more resources, and after a series of debugging and consuming the hair of several members of the infra team, we managed to achieve a full green score in needle-in-a-haystack testing for the Pretrain model activated by MoBA (meeting the standards for large models handling long texts). At this point, we felt very good and began the deployment process.
However, the most unexpected thing was that there was only an unexpected issue. During the SFT (Supervised Fine-Tuning) phase, some data carried a very sparse loss mask (resulting in only 1% or even fewer tokens having gradients for training) (the loss mask refers to the technique of selecting which parts participate in measuring the model's prediction results against the standard answers), which led to MoBA performing well on most SFT tasks, but for longer text summarization tasks, the loss mask became increasingly sparse, resulting in lower learning efficiency. MoBA was paused in the near-deployment process, entering the cliff of reflection for the third time.
Third Entry into the Cliff of Reflection
The third entry into the cliff of reflection was actually the most tense. By this time, the entire project had incurred significant sunk costs, and the company had invested substantial computational and human resources. If issues arose in the end-to-end long text application scenarios, the earlier research would be nearly wasted. Fortunately, due to MoBA's excellent mathematical properties, in a new round of saturated rescue experiments and ablation studies (which investigate the impact of removing certain parts of the model or changing certain settings on model performance), we found that removing the loss mask performed very well, while including the loss mask did not yield satisfactory results. We realized that the tokens with gradients were too sparse during the SFT phase, leading to low learning efficiency. Therefore, we modified the last few layers to Full Attention to increase the density of gradient-carrying tokens during backpropagation, improving learning efficiency for specific tasks. Subsequent experiments confirmed that this switch did not significantly affect the performance of the reverted Sparse Attention, maintaining parity with the Full Attention across various metrics at a length of 1M (1 million). MoBA returned from the cliff of reflection once again and successfully went live to serve users.
Finally, I would like to thank all the great minds for their support, the company's strong backing, and the massive GPUs. What we are now releasing is the code we use online, which has been validated over a long period. It has been stripped of various extra designs due to actual needs, maintaining an extremely simple structure while possessing sufficient effectiveness as a Sparse Attention structure. I hope MoBA and its origin, CoT (Chain of Thought), can bring some help and value to everyone.
FAQ
I would like to take this opportunity to answer some frequently asked questions over the past couple of days. I have been bothering Professor Zhang and Su Jianlin to act as customer service to answer questions, and I feel quite sorry about that. Here are a few common questions along with their answers.
1. Is MoBA ineffective for Decoding (the text generation process during model inference)?
MoBA is effective for Decoding, very effective for MHA (Multi-Head Attention), less effective for GQA (Grouped Query Attention), and least effective for MQA (Multi-Query Attention). The principle is quite simple: in the case of MHA, each Q has its corresponding KV cache. In an ideal scenario, MoBA's gate can calculate and store the representative token for each block during the prefill stage (the computation phase when processing input for the first time). This token will not change in subsequent operations, allowing all IO (input-output operations) to primarily come from the KV cache after index select (the operation of selecting data by index). In this case, the sparsity of MoBA determines the extent of IO reduction.
However, for GQA and MQA, since a group of Q Heads actually shares the same KV cache, when each Q Head can freely choose the blocks of interest, it is very likely to fill up the IO optimization brought by sparsity. For example, consider a scenario with 16 Q Heads in MQA, where MoBA splits the entire sequence into 16 parts. This means that in the worst-case scenario, each Q Head is interested in the context blocks numbered from 1 to 16, which would diminish the advantage of saving IO. The more Q Heads that can freely choose KV Blocks, the worse the effect.
Due to the existence of the phenomenon of "Q Heads freely choosing KV Blocks," a natural improvement idea is to merge. If everyone selects the same Block, wouldn't that optimize IO? Yes, but in our actual tests, especially for pre-trained models that have already incurred significant costs, each Q Head has its unique "taste," and forcibly merging is not as effective as retraining from scratch.
2. Is self attention (the self-attention mechanism) mandatory in MoBA? Will the neighbors of self be mandatory?
No, it is not mandatory. This is a known area that may cause some confusion. We ultimately choose to trust SGD (Stochastic Gradient Descent). The current implementation of the MoBA gate is very straightforward. Interested individuals can easily modify the gate to make it mandatory to select the previous chunk, but our tests show that the benefits of this modification are marginal.
3. Does MoBA have a Triton implementation (a framework for writing high-performance GPU code developed by OpenAI)?
We implemented a version that improved end-to-end performance by over 10%, but maintaining the Triton implementation to keep up with the mainline is quite costly. Therefore, after multiple iterations, we have paused further optimization of it.
*Project addresses for several results mentioned at the beginning of the article (the GitHub pages include links to technical papers; DeepSeek has not yet launched on NSA's GitHub page):
MoBA GitHub page: https://github.com/MoonshotAI/MoBA
NSA technical paper: https://arxiv.org/abs/2502.11089
MiniMax-01 GitHub page: https://github.com/MiniMax-AI/MiniMax-01
InfLLM GitHub page: https://github.com/thunlp/InfLLM?tab=readme-ov-file
SeerAttention GitHub page: https://github.com/microsoft/SeerAttention
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






