Distillation is not plagiarism, but a necessary means of technological evolution.
Author: Deng Yongyi, Intelligent Emergence

Image source: Generated by Wujie AI
During the Spring Festival of 2025, the hottest topic was not just Nezha 2, but also an application called DeepSeek—this inspirational story has been recounted multiple times: On January 20, the AI startup DeepSeek, located in Hangzhou, released its new model R1, which competes with OpenAI's current strongest reasoning model o1, truly igniting global interest.
In just one week since its launch, the DeepSeek App has already garnered over 20 million downloads, ranking first in more than 140 countries. Its growth rate has surpassed that of ChatGPT, which was launched in 2022, and it currently accounts for about 20% of the latter's user base.
How popular is it? As of February 8, the number of DeepSeek users has exceeded 100 million, reaching far beyond AI enthusiasts, extending from China to the global stage. From the elderly and children to stand-up comedians and politicians, everyone is talking about DeepSeek.

Even now, the impact brought by DeepSeek continues. In the past two weeks, DeepSeek has rapidly followed the script of TikTok—exploding in popularity and experiencing rapid growth, defeating many American competitors, and even placing DeepSeek on the geopolitical edge: the U.S. and Europe have begun discussing "national security implications," with many regions quickly issuing orders to ban downloads or installations.
A16Z partner Marc Andreessen even exclaimed that the emergence of DeepSeek is another "Sputnik Moment."
(A term originating from the Cold War, referring to the Soviet Union's successful launch of the world's first artificial satellite, Sputnik 1, in 1957, which caused panic in American society as it realized its position was being challenged and its technological advantage could be overturned.)
However, with fame comes controversy, and within the tech community, DeepSeek has also fallen into disputes over "distillation," "data theft," and more.
As of now, DeepSeek has not made any public response, and these controversies have fallen into two extremes: fervent supporters elevate DeepSeek-R1 to a "national fortune-level" innovation; while some tech practitioners question DeepSeek's ultra-low training costs and distillation training methods, believing these innovations are being overly celebrated.
Is DeepSeek "stealing" from OpenAI? More like the thief shouting to catch the thief
Almost from the moment DeepSeek exploded in popularity, Silicon Valley AI giants including OpenAI and Microsoft have publicly voiced their concerns, focusing on DeepSeek's data. David Sachs, the U.S. government's AI and crypto chief, has also publicly stated that DeepSeek "absorbs" ChatGPT's knowledge through a technique called distillation.
OpenAI stated in a report by the Financial Times that it has found signs of DeepSeek "distilling" ChatGPT, claiming this violates OpenAI's model usage agreement. However, OpenAI has not provided specific evidence.
In fact, this is an unfounded accusation.
Distillation is a normal technique in large model training. This often occurs during the training phase—using the outputs of a larger, more powerful model (teacher model) to help a smaller model (student model) learn better performance. For specific tasks, the smaller model can achieve similar results at a lower cost.
Distillation is also not plagiarism. To put it simply, distillation is more like having a teacher solve all the difficult problems and compile perfect solution notes—these notes contain not just answers, but various optimal methods; ordinary students (small models) only need to learn directly from these notes and then output their own answers, checking against the notes to see if they align with the teacher's reasoning.
DeepSeek's most notable contribution lies in its greater use of unsupervised learning in this process—allowing machines to self-feedback and reducing human feedback (RLHF). The most direct result is that the model's training costs have significantly decreased—this is also the source of many criticisms.
The DeepSeek-V3 paper mentioned the specific training cluster scale for its V3 model (2048 H800 chips). Many have estimated this cost to be around $5.5 million, which is about one-tenth of the training costs of models from Meta, Google, and others.
However, it should be noted that DeepSeek has long indicated in its papers that this is only the cost of a single run of the final training, without including the costs of earlier equipment, personnel, and training losses.
In the AI field, distillation is not a new concept; many model vendors have disclosed their own distillation work. For example, Meta has previously announced how its models are distilled—Llama 2 uses a larger, smarter model to generate data that includes thought processes and methods, which is then fine-tuned in its smaller-scale reasoning model.
△Source: Meta FAIR
But distillation also has its drawbacks.
An AI application practitioner from a major company told Intelligent Emergence that while distillation can quickly enhance model capabilities, its downside is that the data generated by the "teacher model" is too clean and lacks diversity. Learning from such data, the model will resemble a standardized "pre-made dish," and its capabilities cannot exceed those of the teacher model.
Data quality largely determines the effectiveness of model training. If most of the model training is completed through distillation, it may lead to overly homogenized models. Today, there are numerous large models globally, and each company will provide its own "essence version" of the model; distilling an identical model is not particularly meaningful.
A more critical issue is that the hallucination problem may become more severe. This is because the small model, to some extent, only mimics the "skin" of the large model, making it difficult to deeply understand the underlying logic, which can lead to poorer performance on new tasks.
Therefore, to give the model its own characteristics, AI engineers need to intervene from the data stage—what kind of data to choose, the data ratio, and the training methods will all make the final trained model very different.
A typical example is the current OpenAI and Anthropic. OpenAI and Anthropic are among the first Silicon Valley companies to develop large models, and neither had ready-made models for distillation; instead, they directly crawled and learned from publicly available networks and datasets.
Different learning paths have also led to significant differences in the styles of the two models—now, ChatGPT resembles a diligent engineering student, adept at solving various problems in life and work; while Claude excels in the humanities, being recognized as the king of writing tasks, but also performs well in coding tasks.
Another irony in OpenAI's accusations lies in using a vaguely defined clause to accuse DeepSeek, even though it has done similar things itself.
From its inception, OpenAI was an open-source-oriented organization, but after GPT-4, it shifted to closed-source. OpenAI's training has crawled through publicly available data from around the world. Therefore, after choosing to go closed-source, OpenAI has been embroiled in copyright disputes with news media and publishers.
OpenAI's accusation of DeepSeek's "distillation" has been mocked as "the thief shouting to catch the thief" because neither OpenAI o1 nor DeepSeek R1 disclosed details about their data preparation in their papers, leaving this issue shrouded in ambiguity.
Moreover, when DeepSeek-R1 was released, it even chose the MIT open-source license—one of the most permissive open-source licenses. DeepSeek-R1 allows commercial use, permits distillation, and provides the public with six distilled small models that users can directly deploy on mobile phones and PCs, demonstrating a sincere contribution to the open-source community.
On February 5, former Stability AI research director Tanishq Mathew Abraham also wrote an article pointing out that this accusation treads on gray areas: first, OpenAI has not provided evidence showing that DeepSeek directly utilized GPT for distillation. He speculated that one possible scenario is that DeepSeek found datasets generated using ChatGPT (many of which are already available on the market), and this situation has not been explicitly prohibited by OpenAI.
Is distillation the standard for determining whether to pursue AGI?
In the public discourse, many people now use "whether to distill" as a criterion to define whether something is plagiarism or whether AGI is being pursued, which is rather arbitrary.
DeepSeek's work has reignited interest in the concept of "distillation," which is, in fact, a technology that emerged nearly a decade ago.
In 2015, a paper titled "Distilling the Knowledge in a Neural Network," co-authored by AI luminaries Hinton, Oriol Vinyals, and Jeff Dean, formally introduced the "knowledge distillation" technique in large models, which has since become a standard in the field of large models.
For model vendors focusing on specific fields and tasks, distillation is actually a more realistic path.
An AI practitioner told Intelligent Emergence that there are hardly any large model vendors in China that do not engage in distillation; this is almost an open secret. "The data from the public internet has almost been exhausted, and the cost of pre-training and data labeling from scratch is difficult for even large companies to bear."
One exception is ByteDance. In the recently released Doubao 1.5 pro version, ByteDance explicitly stated that "no data generated by any other models was used during the training process, firmly refusing to take the shortcut of distillation," expressing its determination to pursue AGI.
The decision of major companies to avoid distillation has practical considerations, such as avoiding many subsequent compliance disputes. Under the premise of being closed-source, this also creates a certain barrier to model capabilities. According to Intelligent Emergence, ByteDance's current data labeling costs are already on par with Silicon Valley levels—up to $200 per entry. This high-quality data requires experts in specific fields, such as those with master's or doctoral degrees, to perform the labeling.
For many participants in the AI field, whether using distillation or other engineering methods, it is essentially an exploration of the boundaries of the Scaling Law. This is a necessary condition for exploring AGI, but not a sufficient condition.
In the first two years of the large model boom, the Scaling Law was often crudely understood as "great effort yields miraculous results," meaning that stacking computing power and parameters could lead to the emergence of intelligence, which is more relevant during the pre-training phase.
Today, the heated discussion around "distillation" actually reflects an underlying shift in the development paradigm of large models: the Scaling Law still exists, but it has truly shifted from the pre-training phase to the post-training and inference phases.
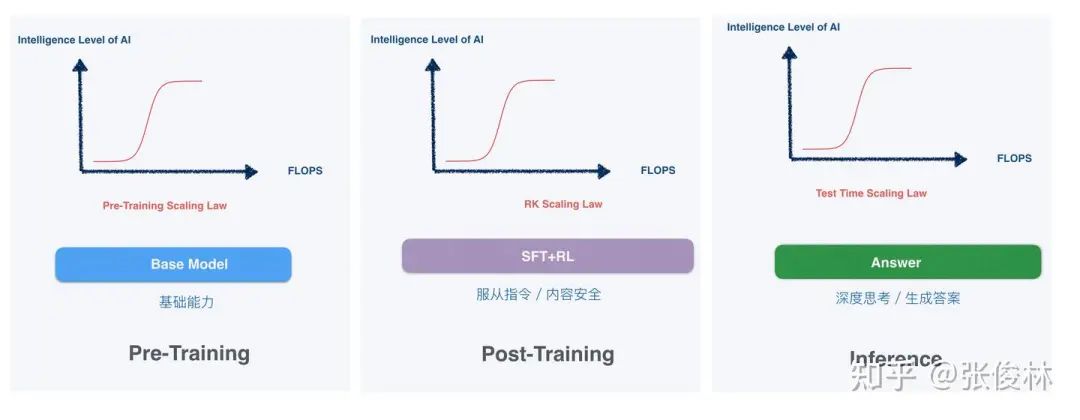
△Source: Column article by Zhang Junlin, PhD, Institute of Software, Chinese Academy of Sciences
OpenAI's o1 was released in September 2024 and is considered a landmark in the transition of the Scaling Law to post-training and inference; it remains the world's leading reasoning model. However, the problem is that OpenAI has never publicly disclosed its training methods and details, and the application costs remain high: the cost of o1 pro is as high as $200/month, and the inference speed is still slow, which is seen as a major constraint on AI application development.
During this time, most of the work in the AI community has been focused on replicating the effects of o1 while also needing to reduce inference costs to enable applications in more scenarios. The milestone significance of DeepSeek lies not only in significantly shortening the time for open-source models to catch up with top closed-source models—achieving this in just about three months and nearly matching several metrics of o1—but more importantly, in finding the key techniques for o1's capability leap and making them open-source.
An important premise that cannot be ignored is that DeepSeek's innovation was accomplished on the shoulders of giants. Viewing engineering methods like "distillation" merely as shortcuts is too narrow; this is more a victory of open-source culture.
The ecological co-prosperity and open-source effects brought by DeepSeek have quickly become apparent. Shortly after its explosive popularity, a new work by "AI mother" Fei-Fei Li also went viral: using Google's Gemini as the "teacher model" and the fine-tuned Alibaba Qwen2.5 as the "student model," a reasoning model s1 was trained through distillation and other methods for less than $50, replicating the model capabilities of DeepSeek-R1 and OpenAI-o1.
NVIDIA is also a typical case. After the release of DeepSeek-R1, although NVIDIA's market value plummeted by about $600 billion overnight, creating the largest single-day evaporation in history, it quickly rebounded the next day, rising by about 9%—the market remains optimistic about the strong inference demand brought by R1.
It is foreseeable that after various parties in the large model field absorb the capabilities of R1, a wave of AI application innovation will follow.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






