AI companies used to measure themselves against industry leader OpenAI. No more. Now that China’s DeepSeek has emerged as the frontrunner, it’s become the one to beat.
On Monday, DeepSeek turned the AI industry on its head, causing billions of dollars in losses on Wall Street while raising questions about how efficient some U.S. startups—and venture capital— actually are.
Now, two new AI powerhouses have entered the ring: The Allen Institute for AI in Seattle and Alibaba in China; both claim their models are on a par with or better than DeepSeek V3.
The Allen Institute for AI, a U.S.-based research organization known for the release of a more modest vision model named Molmo, today unveiled a new version of Tülu 3, a free, open-source 405-billion parameter large language model.
“We are thrilled to announce the launch of Tülu 3 405B—the first application of fully open post-training recipes to the largest open-weight models,” the Paul Allen-funded non-profit said in a blog post. “With this release, we demonstrate the scalability and effectiveness of our post-training recipe applied at 405B parameter scale.”
For those who like comparing sizes, Meta’s latest LLM, Llama-3.3, has 70 billion parameters, and its largest model to date is Llama-3.1 405b—the same size as Tülu 3.
The model was so big that it demanded extraordinary computational resources, requiring 32 nodes with 256 GPUs running in parallel for training.
The Allen Institute hit several roadblocks while building its model. The sheer size of Tülu 3 meant the team had to split the workload across hundreds of specialized computer chips, with 240 chips handling the training process while 16 others managed real-time operations.
Even with this massive computing power, the system frequently crashed and required round-the-clock supervision to keep it running.
Tülu 3's breakthrough centered on its novel Reinforcement Learning with Verifiable Rewards (RLVR) framework, which showed particular strength in mathematical reasoning tasks.
Each RLVR iteration took approximately 35 minutes, with inference requiring 550 seconds, weight transfer 25 seconds, and training 1,500 seconds, with the AI getting better at problem-solving with each round.
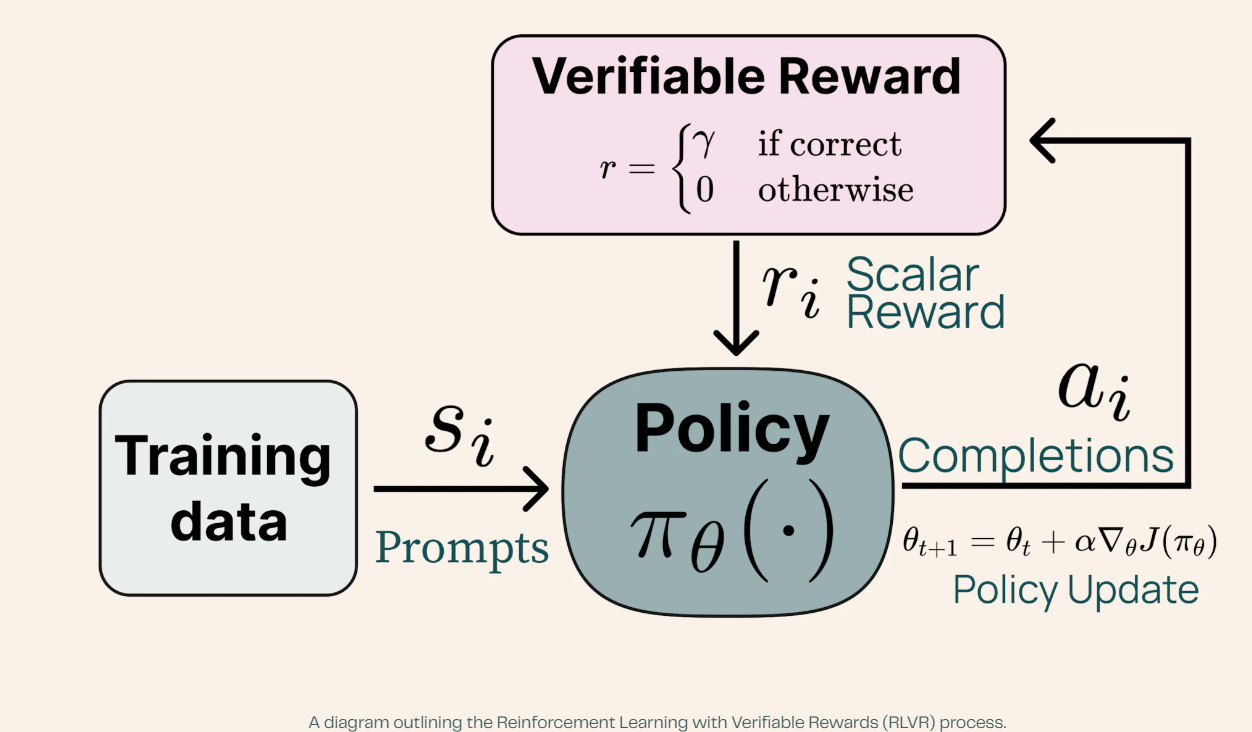
Image: Ai2
Reinforcement Learning with Verifiable Rewards (RLVR) is a training approach that seems like a sophisticated tutoring system.
The AI received specific tasks, like solving math problems, and got instant feedback on whether its answers were correct.
However, unlike traditional AI training (like the one used by openAI to train ChatGPT), where human feedback can be subjective, RLVR only rewarded the AI when it produced verifiably correct answers, similar to how a math teacher knows exactly when a student's solution is right or wrong.
This is why the model is so good at math and logic problems but not the best at other tasks like creative writing, roleplay, or factual analysis.
The model is available at Allen AI’s playground, a free site with a UI similar to ChatGPT and other AI chatbots.
Our tests confirmed what could be expected from a model this big.
It is very good at solving problems and applying logic. We provided different random problems from a number of math and science benchmarks and it was able to output good answers, even easier to understand when compared to the sample answers that benchmarks provided.
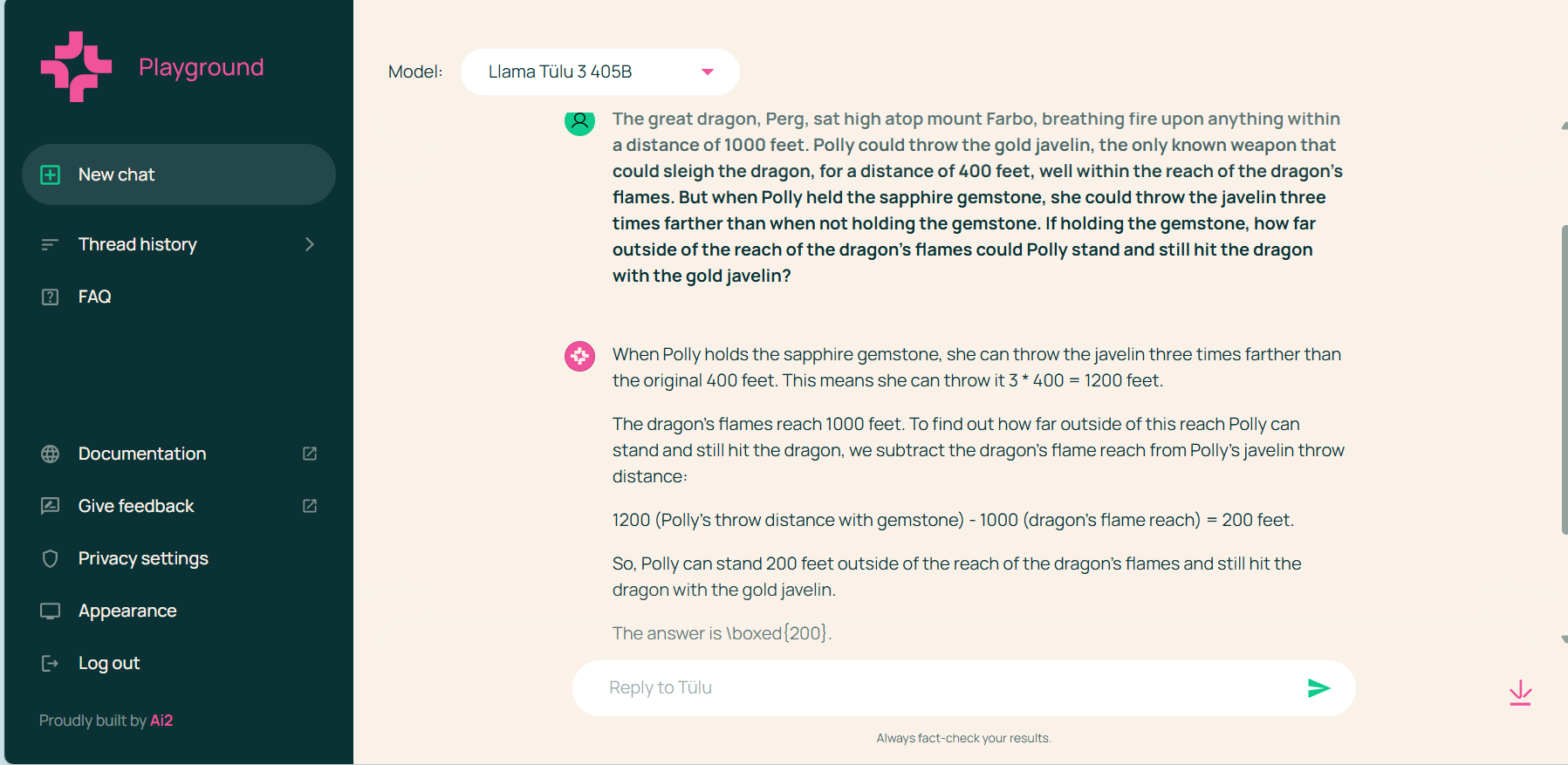
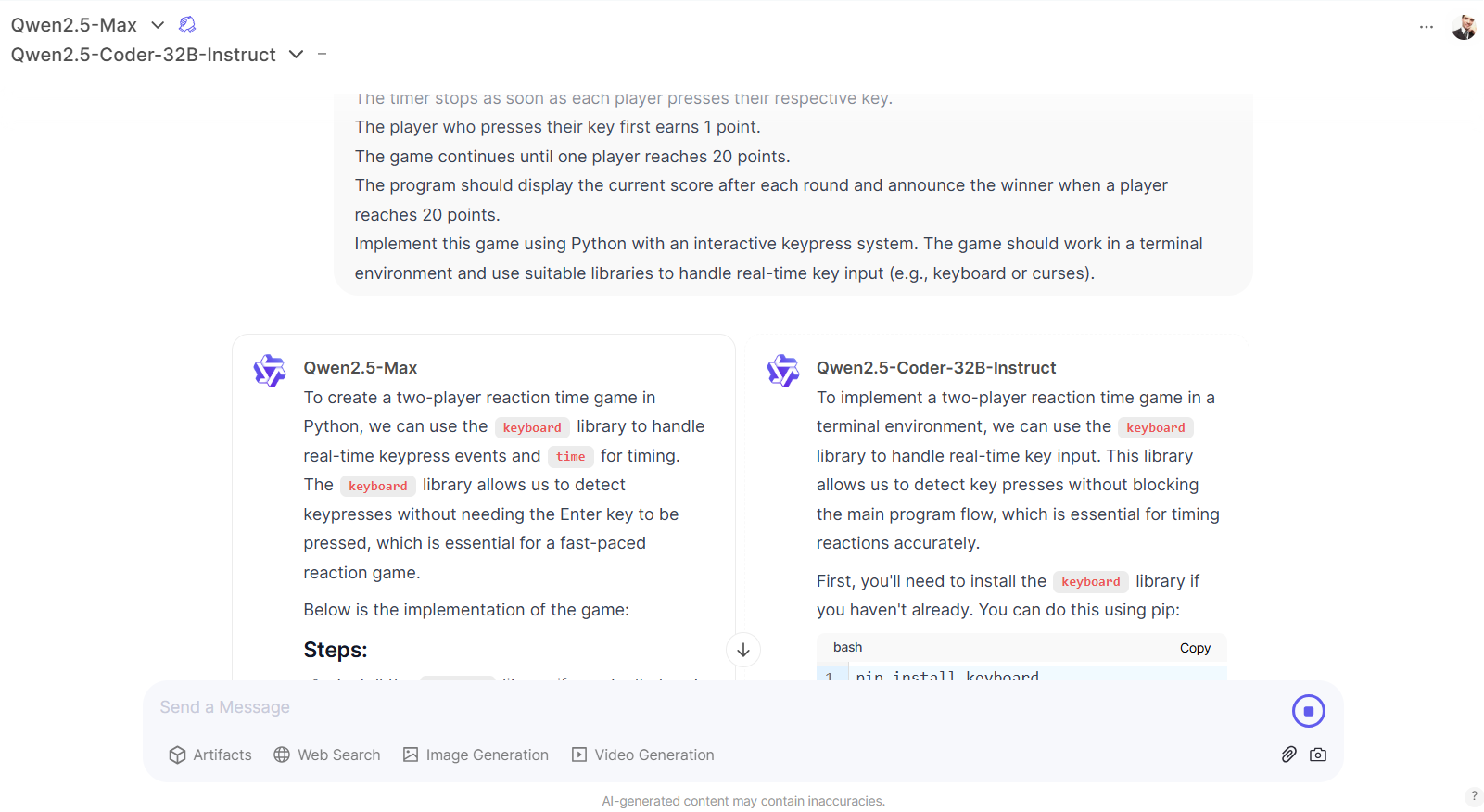
However, it failed in other logical language-related tasks that didn’t involve math, such as writing sentences that end in a specific word.
Also, Tülu 3 isn’t multimodal. Instead, it stuck to what it knew best—churning out text. No fancy image generation or embedded Chain-of-Thought tricks here.
On the upside, the interface is free to use, requiring a simple login, either via Allen AI’s playground or by downloading the weights to run locally.
The model is available for download via Hugging Face, with alternatives going from 8 billion parameters to the gigantic 405 billion parameters version.
Chinese Tech Giant Enters the Fray
Meanwhile, China isn’t resting on DeepSeek’s laurels.
Amid all the hubbub, Alibaba dropped Qwen 2.5-Max, a massive language model trained on over 20 trillion tokens.
The Chinese tech giant released the model during the Lunar New Year, just days after DeepSeek R1 disrupted the market.
Benchmark tests showed Qwen 2.5-Max outperformed DeepSeek V3 in several key areas, including coding, math, reasoning, and general knowledge, as evaluated using benchmarks like Arena-Hard, LiveBench, LiveCodeBench, and GPQA-Diamond.
The model demonstrated competitive results against industry leaders like GPT-4o and Claude 3.5-Sonne,t according to the model’s card.
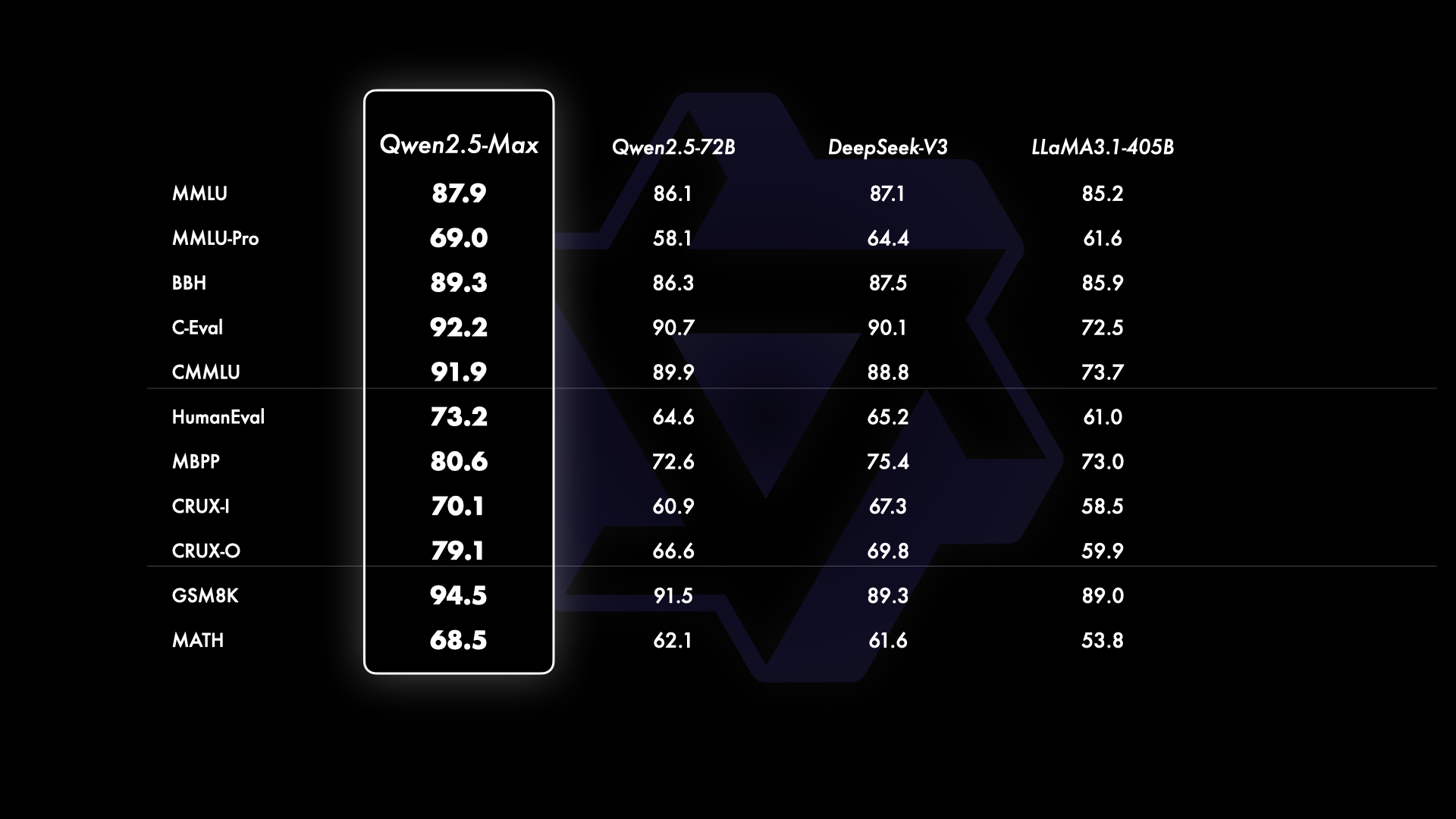
Image: Alibaba
Alibaba made the model available through its cloud platform with an OpenAI-compatible API, allowing developers to integrate it using familiar tools and methods.
The company's documentation showed detailed examples of implementation, suggesting a push for widespread adoption.
But Alibaba’s Qwen Chat web portal is the best option for general users and seems pretty impressive—for those who are okay with creating an account there. It is probably the most versatile AI chatbot interface currently available.
Qwen Chat allows users to generate text, code, and images flawlessly. It also supports web search functionality, artifacts, and even a very good video generator, all in the same UI—for free.
It also has a unique function in which users can choose two different models to “battle” against each other to provide the best response.
Overall, Qwen’s UI is more versatile than Allen AI’s.
In text responses, Qwen2.5-Max proved to be better than Tülu 3 at creative writing and reasoning tasks that involved language analysis. For example, it was capable of generating phrases ending in a specific word.
Its video generator is a nice addition and is arguably on par with offers like Kling or Luma Labs—definitely better than what Sora can make.
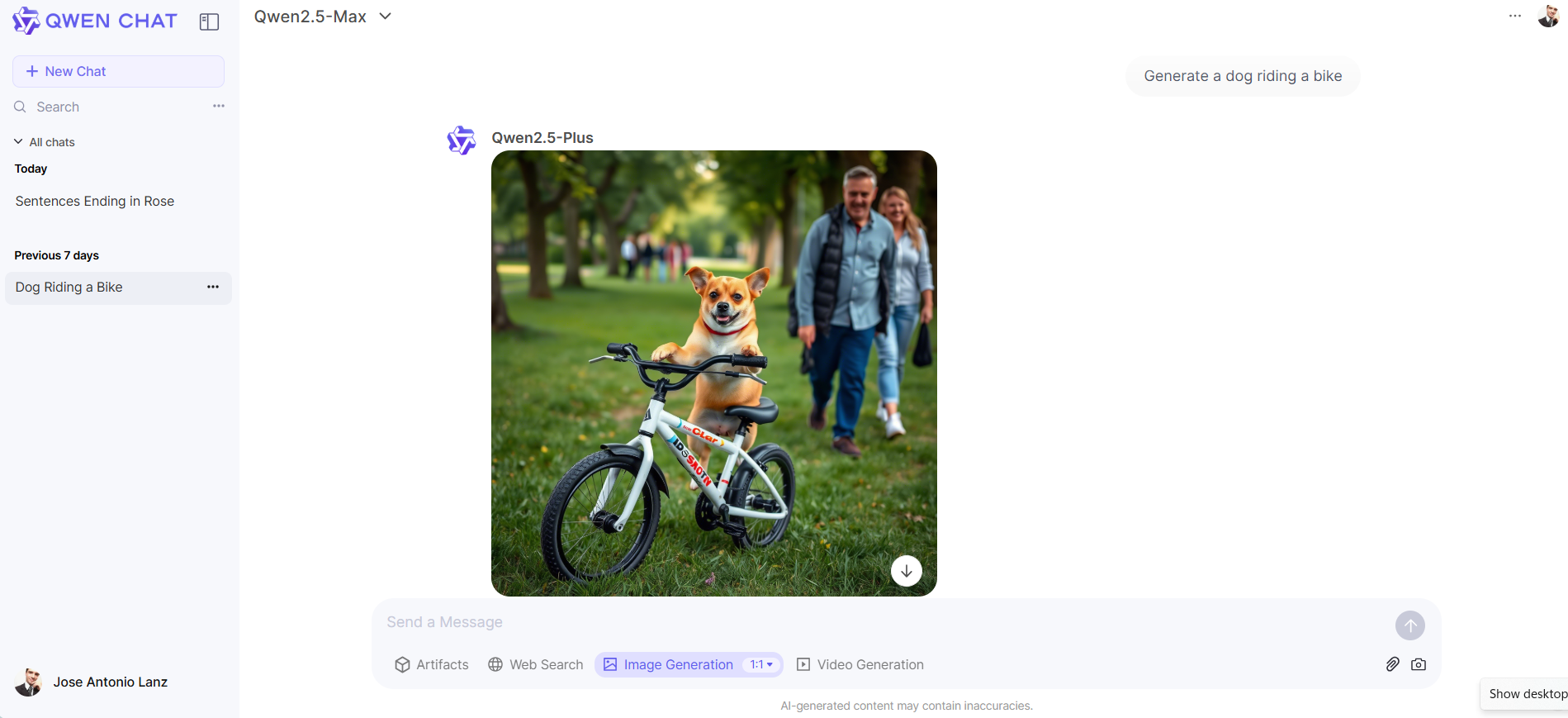
Also, its image generator provides realistic and pleasant images, showing a clear advantage over OpenAI’s DALL-E 3, but clearly behind top models like Flux or MidJourney.
The triple release of DeepSeek, Qwen2.5-Max, and Tülu 3 just gave the open-source AI world its most significant boost in a while.
DeepSeek had already turned heads by building its R1 reasoning model using earlier Qwen technology for distillation, proving open-source AI could match billion-dollar tech giants at a fraction of the cost.
And now Qwen2.5-Max has upped the ante. If DeepSeek follows its established playbook—leveraging Qwen's architecture—its next reasoning model could pack an even bigger punch.
Still, this could be a good opportunity for the Allen Institute. OpenAI is racing to launch its o3 reasoning model, which some industry analysts estimated could cost users up to $1,000 per query.
If so, Tülu 3's arrival could be a great open-source alternative—especially for developers wary of building on Chinese technology due to security concerns or regulatory requirements.
Edited by Josh Quittner and Sebastian Sinclair
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






