Author: Yu Yan, Reporter from The Paper
· A headhunter responsible for recruiting high-end tech talent in the large model field told The Paper that DeepSeek's hiring logic is not much different from that of other companies in the large model sector. The core label for talent is "young and high potential," meaning individuals born around 1998, with ideally no more than five years of work experience, characterized as "smart, STEM-oriented, young, and inexperienced."
· Industry insiders believe that compared to other domestic large model startups, DeepSeek is fortunate to have no financing pressure, not needing to prove itself to investors, and not having to balance technical iterations of the model with product application optimizations. However, as a commercial company, after significant investment, it will inevitably face the pressures and challenges currently confronting other model companies, sooner or later.
Which company is the hottest in China's large model circle in 2024? Hangzhou DeepSeek Artificial Intelligence Basic Technology Research Co., Ltd. (hereinafter referred to as DeepSeek) is certainly a strong contender. If DeepSeek was the initiator of the large model price war last year, entering the public eye, it completely ignited the discourse in the large model circle after releasing the open-source model DeepSeek-V3 and the inference model DeepSeek-R1 at the end of the year. People are both amazed by its high cost-performance training costs (reportedly, DeepSeek-V3 only cost $5.576 million in training) and applaud its open-source model and public technical reports. The release of DeepSeek-R1 has excited many scientists, developers, and users, with some even considering DeepSeek a strong competitor to OpenAI's o1 and other inference models.
How has this low-profile company managed to create high-performance large models at extremely low training costs? What has contributed to its current popularity? What challenges will it face in the future if it wants to continue riding the waves in the "model circle"?
Algorithmic Innovation Significantly Reduces Computing Costs
"DeepSeek invested early and accumulated a lot, having its own unique features in algorithms." An executive from a prominent domestic large model startup mentioned DeepSeek, stating that its core advantage lies in algorithmic innovation, "Chinese companies, due to a lack of computing power, pay more attention to cost-saving in computing power than OpenAI."
According to information released by DeepSeek regarding DeepSeek-R1, it extensively utilized reinforcement learning technology in the post-training phase, significantly enhancing the model's inference capabilities with very few labeled data. In tasks such as mathematics, coding, and natural language reasoning, its performance rivals that of OpenAI's o1 official version.
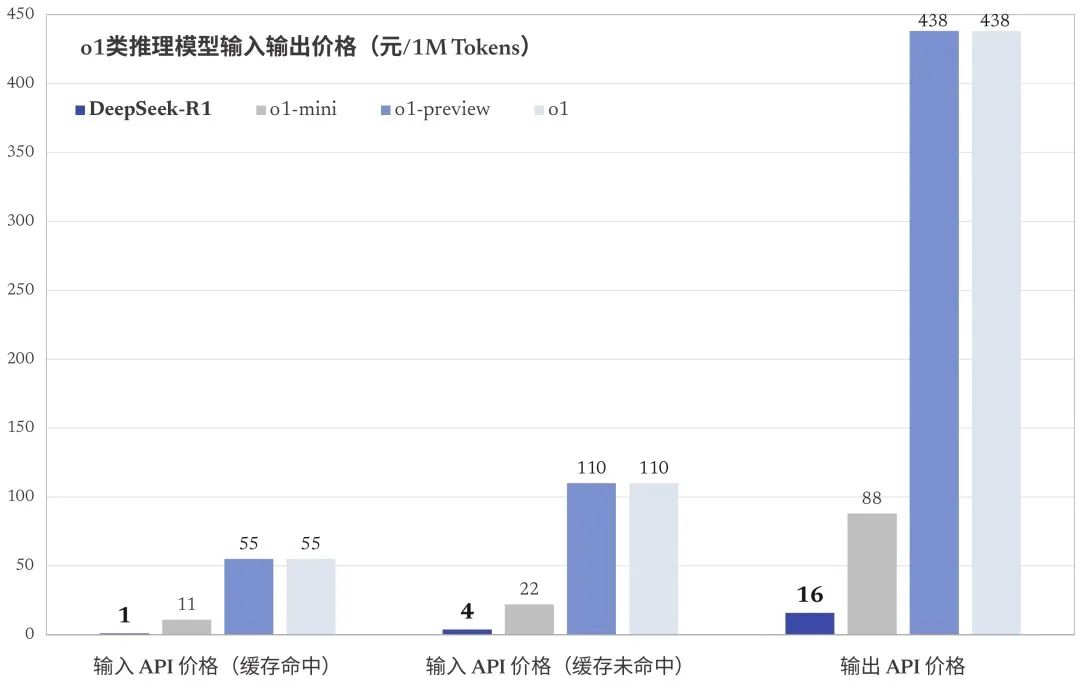
DeepSeek-R1 API Pricing
DeepSeek founder Liang Wenfeng has repeatedly emphasized that DeepSeek is committed to developing a differentiated technological path rather than replicating OpenAI's model, and it must find more effective methods to train its models.
"They have optimized the model architecture using a series of engineering techniques, such as innovatively employing model mixing methods, with the essential goal of reducing costs through engineering to achieve profitability," a senior industry insider told The Paper.
From the information disclosed by DeepSeek, it can be seen that significant progress has been made in the MLA (Multi-head Latent Attention) mechanism and the self-developed DeepSeekMOE (Mixture-of-Experts) structure. These two technological designs make DeepSeek's models more cost-effective by reducing training computational resources and improving training efficiency. According to data from research institution Epoch AI, DeepSeek's latest model is highly efficient.
In terms of data, unlike OpenAI's "massive data feeding" approach, DeepSeek summarizes and classifies data using algorithms, selectively processing it before feeding it to the large model, thereby improving training efficiency and reducing DeepSeek's costs. The emergence of DeepSeek-V3 has achieved a balance between high performance and low cost, providing new possibilities for the development of large models.
"In the future, perhaps there will be no need for ultra-large GPU clusters." After the release of DeepSeek's cost-effective model, OpenAI founding member Andrej Karpathy stated.
Liu Zhiyuan, a tenured associate professor in the Computer Science Department at Tsinghua University, told The Paper that DeepSeek's emergence proves our competitive advantage lies in the extreme efficiency of utilizing limited resources to achieve more with less. The release of R1 indicates that the gap in AI capabilities between us and the U.S. has significantly narrowed. The Economist also reported in its latest issue: "DeepSeek is simultaneously changing the tech industry with its low-cost training and innovative model design."
Demis Hassabis, CEO and co-founder of Google DeepMind, stated that while it is not entirely clear how much DeepSeek relies on Western systems for training data and open-source models, the achievements of the team are indeed impressive. On one hand, he acknowledges that China has very strong engineering and scaling capabilities; on the other hand, he points out that the West still leads and needs to consider how to maintain the leading position of Western frontier models.
Years of Focus Yielding Results
DeepSeek's innovations are not the result of a day’s work but rather the culmination of years of "incubation" and long-term planning. Liang Wenfeng is also the founder of the leading quantitative private equity firm, Huanfang Quantitative. DeepSeek is believed to have fully utilized the funds, data, and resources accumulated by Huanfang Quantitative.
Liang Wenfeng graduated with both undergraduate and master's degrees from Zhejiang University, holding degrees in Information and Electronic Engineering. Since 2008, he has led a team to explore fully automated quantitative trading using machine learning and other technologies. In 2015, Huanfang Quantitative was established, launching its first AI model the following year, with the first trading positions generated by deep learning going live. By 2018, it established AI as its main development direction. In 2020, Huanfang invested over 100 million yuan in the AI supercomputer "Firefly No. 1," which is said to rival the computing power of 40,000 personal computers. In 2021, Huanfang invested a billion to build "Firefly No. 2," equipped with 10,000 A100 GPU chips. At that time, there were fewer than five companies in China with over 10,000 GPUs, and apart from Huanfang Quantitative, the other four were all major internet firms.
In July 2023, DeepSeek was officially established, entering the field of general artificial intelligence, and has never sought external financing.
"With relatively ample resources and no financing pressure, the first few years focused solely on models rather than products, making DeepSeek appear more straightforward and focused compared to other domestic large model companies, allowing for breakthroughs in engineering technology and algorithms," said the aforementioned executive from a domestic large model company.
Additionally, as the large model industry increasingly moves towards closure, with OpenAI being humorously referred to as CloseAI, DeepSeek's open-source models and public technical reports have garnered much praise from developers, allowing its technical brand to quickly stand out in both domestic and international large model markets.
A researcher told The Paper that DeepSeek's openness is remarkable, with the open-sourcing of models V3 and R1 raising the benchmark level for open-source models in the market.
Success Proves the Power of Youth
"DeepSeek's success has also showcased the power of young people; fundamentally, this generation of AI development needs young minds," a person from a model company told The Paper.
Previously, Jack Clark, former policy director at OpenAI and co-founder of Anthropic, believed that DeepSeek had hired "a group of enigmatic geniuses." In response, Liang Wenfeng stated in an interview with a media outlet that there are no enigmatic geniuses, just graduates from top domestic universities, PhD interns, and some young people who graduated only a few years ago.
From the existing media reports, it can be seen that the biggest characteristic of the DeepSeek team is its prestigious educational background and youth; even at the team leader level, most are under 35 years old. With a team of fewer than 140 people, engineers and researchers mostly come from top domestic universities such as Tsinghua University, Peking University, Sun Yat-sen University, and Beijing University of Posts and Telecommunications, with relatively short work experience.
A headhunter responsible for recruiting high-end tech talent in the large model field told The Paper that DeepSeek's hiring logic is not much different from that of other companies in the large model sector. The core label for talent is "young and high potential," meaning individuals born around 1998, with ideally no more than five years of work experience, characterized as "smart, STEM-oriented, young, and inexperienced."
However, the aforementioned headhunter also stated that large model startups are essentially startups and do not lack the desire to recruit top AI talent from overseas, but the reality is that few top overseas AI talents are willing to return.
A DeepSeek employee, who wished to remain anonymous, revealed to The Paper that the company has a flat management structure and a good atmosphere for free communication. Liang Wenfeng's whereabouts are often unpredictable, and most of the time, communication with him is online.
This employee previously worked on large model technology research and development at a major domestic firm but felt like a cog in the machine, unable to create value, ultimately choosing to join DeepSeek. In his view, DeepSeek is currently more focused on foundational model technology.
DeepSeek's work atmosphere is entirely bottom-up, with natural division of labor, and there are no limits on the movement of resources and personnel. "Everyone brings their own ideas and doesn't need to be pushed. When encountering problems during exploration, they will pull people in for discussion," Liang Wenfeng stated in a previous interview.
"It is too early to say that China’s AI has surpassed the U.S."
American business media Business Insider analyzed that the newly released R1 indicates that China can compete with some of the top AI models in the industry and keep pace with the cutting-edge developments in Silicon Valley; furthermore, the open-sourcing of such advanced AI could pose a challenge to companies trying to make huge profits by selling technology.
However, it may still be too early to proclaim that "China's AI has surpassed the U.S." Liu Zhiyuan publicly stated that we need to be cautious about public opinion swinging from extreme pessimism to extreme optimism, believing that we have fully surpassed and are far ahead, "not at all." Liu Zhiyuan believes that current AGI technologies are still rapidly evolving, and the future development path remains unclear. China is still in a catching-up phase; although it is no longer out of reach, it can only be said to be within sight. "Following closely on a path already explored by others is relatively easy; the greater challenge lies in how to forge new paths in the fog."
"Everyone is too anxious and doesn't realize that DeepSeek has finally emerged." Someone close to DeepSeek expressed to The Paper that the speed of change in the industry is too fast to predict what can be done next, and we can only wait for changes in the next Q3 quarter.
Demis Hassabis acknowledges that China has very strong engineering and scaling capabilities, but he also points out that the West still leads and needs to consider how to maintain the leading position of Western frontier models.
Although Liang Wenfeng previously stated that DeepSeek would only focus on models and not products, as a commercial company, it is almost impossible to continue only making models without developing products. On January 15, DeepSeek officially released its app. Sources close to DeepSeek indicated that commercialization has been put on the agenda.
Industry insiders believe that compared to other domestic large model startups, DeepSeek is fortunate to have no financing pressure, not needing to prove itself to investors, and not having to balance technical iterations of the model with product application optimizations. However, as a commercial company, after significant investment, it will inevitably face the pressures and challenges currently confronting other model companies, sooner or later. "This emergence has provided DeepSeek with a successful marketing opportunity on the eve of commercialization, but after true commercialization, it will need to face market scrutiny, and whether it can continue to ride the waves remains uncertain," said the aforementioned model company insider.
What is certain is that DeepSeek will face more pressures and challenges in the future. The race towards general models has only just begun, and who can win will depend on sustained investment and technological iterations. However, industry insiders also believe that "for the domestic model industry, having a company like DeepSeek with genuine technological strength joining is a good thing."
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







