One of the Ethereum applications that excites me the most is prediction markets.
Author: Vitalik, Ethereum Founder
Translated by: 0xjs@Golden Finance
One of the Ethereum applications that excites me the most is prediction markets. In 2014, I wrote an article about futarchy, a governance model based on predictions conceived by Robin Hanson. As early as 2015, I was an active user and supporter of Augur (look, my name is in the Wikipedia article). I made $58,000 betting on the 2020 election. This year, I have been a close supporter and follower of Polymarket.
For many people, prediction markets are just betting on elections, and betting on elections is gambling—if it can bring people enjoyment, that's great, but fundamentally, it's not any more interesting than buying random tokens on pump.fun. From this perspective, my interest in prediction markets seems puzzling. Therefore, in this article, I aim to explain why this concept excites me. In short, I believe (i) that even existing prediction markets are a very useful tool for the world, and additionally (ii) that prediction markets are just an example of a larger, very powerful category that has the potential to create better implementations in social media, science, news, governance, and other fields. I will refer to this category as "info finance."
The Dual Nature of Polymarket: A Betting Site for Participants, a News Site for Everyone Else
In the past week, Polymarket has been a very effective source of information regarding the U.S. elections. Polymarket not only predicted a 60/40 chance of Trump winning (while other sources predicted 50/50, which is not particularly impressive), but it also showcased other advantages: when the results came out, despite many experts and news sources enticing the audience with favorable news for Harris, Polymarket directly revealed the truth: the chance of Trump winning was over 95%, while the chance of taking control of all government departments was over 90%.
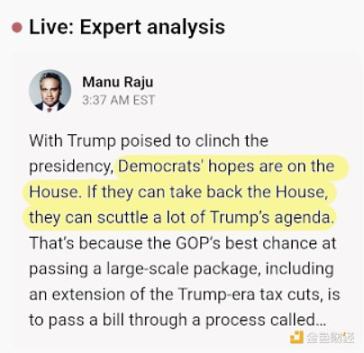
Both screenshots were taken at 3:40 AM EST on November 6.
But for me, this isn't even the best example of what makes Polymarket interesting. So let's look at another example: the elections in Venezuela in July. The day after the election, I remember catching a glimpse of someone protesting the highly manipulated election results in Venezuela. At first, I didn't pay much attention. I knew Maduro was one of those "basically dictators," so I thought he would certainly rig every election to maintain his power, and of course, there would be protests, and of course, the protests would fail—unfortunately, many others had failed. But then while scrolling through Polymarket, I saw this:
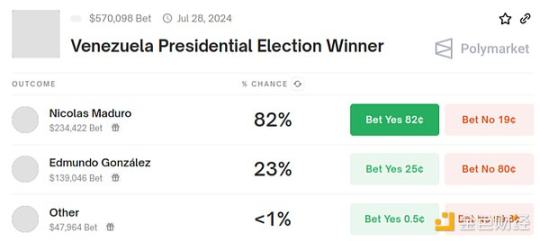
People were willing to bet over $100,000 that the chance of Maduro being overthrown in this election was 23%. Now I started to pay attention.
Of course, we know the unfortunate outcome of this situation. Ultimately, Maduro did remain in power. However, the market made me realize that this time, the attempt to overthrow Maduro was serious. The scale of the protests was massive, and the opposition executed a surprisingly effective strategy to demonstrate to the world how fraudulent the election was. If I hadn't received the initial signal from Polymarket that "this time, something is worth paying attention to," I wouldn't have even started to pay attention.
You should never fully trust Polymarket's betting charts: if everyone believes the betting charts, then any wealthy person can manipulate the betting charts, and no one would dare to bet against them. On the other hand, fully trusting the news is also a bad idea. News has sensational motives and tends to exaggerate the consequences of anything for clicks. Sometimes this is justified, and sometimes it isn't. If you see a sensational article but then go to the market and find that the probability of the related event hasn't changed at all, then skepticism is warranted. Or, if you see unexpectedly high or low probabilities in the market, or an unexpected sudden change, that's a signal to read the news and see what caused it. Conclusion: by reading both the news and the betting charts, you can gain more information than by reading either one alone.
Let's recap what is happening here. If you are a gambler, then you can bet on Polymarket, which is a betting site for you. If you are not a gambler, then you can read the betting charts, which is a news site for you. You should never fully trust the betting charts, but I personally have incorporated reading the betting charts as a step in my information-gathering workflow (alongside traditional media and social media), which helps me obtain more information more effectively.
Info Finance in a Broader Sense
Now, we enter the important part: predicting election outcomes is just the first application. The broader concept is that you can use finance as a way to coordinate incentive mechanisms to provide valuable information to the audience. Now, a natural response is: isn't all finance fundamentally related to information? Different participants make different buying and selling decisions because they have different views on what will happen in the future (aside from personal needs like risk preferences and hedging desires), and you can infer a lot about the world by reading market prices.
To me, info finance is like that, but structurally correct. Similar to structurally correct concepts in software engineering, info finance is a discipline that requires you to (i) start with the facts you want to know, and then (ii) deliberately design a market to optimally extract that information from market participants.
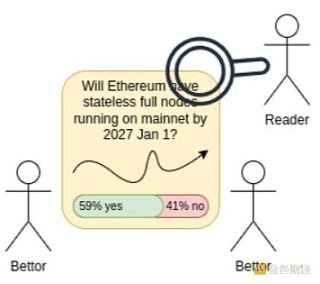
Info finance is a three-sided market: bettors make predictions, readers read predictions. The market outputs predictions about the future as a public good (because that is its designed purpose).
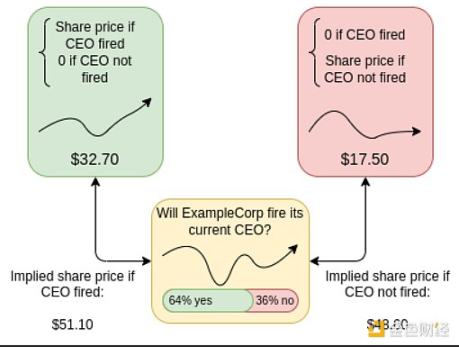
Prediction markets are one example: you want to know a specific fact about the future, so you set up a market for people to bet on that fact. Another example is decision markets: you want to know which decision, A or B, will yield better results based on some metric M. To achieve this, you set up conditional markets: you ask people to bet on (i) which decision will be chosen, (ii) if decision A is chosen, the value of M will be obtained, otherwise zero, (iii) if decision B is chosen, the value of M will be obtained, otherwise zero. With these three variables, you can determine whether the market believes decision A or decision B is more favorable for obtaining the value of M.
I expect that one technology driving the development of info finance in the next decade will be AI (whether large models or future technologies). This is because many of the most interesting applications of info finance relate to "micro" issues: millions of small markets where the decisions have relatively small impacts when viewed individually. In fact, low-volume markets often cannot operate effectively: for experienced participants, spending time on detailed analysis just to gain a few hundred dollars in profit is not worthwhile, and many believe that such markets cannot operate at all without subsidies, as there are not enough naive traders to allow experienced traders to profit from anything other than the largest and most sensational issues. AI completely changes this equation, meaning that even in markets with a volume of $10, we can potentially obtain fairly high-quality information. Even if subsidies are needed, the amount of subsidy per issue becomes very affordable.
Info Finance Needs Human Distillation
Judgment
Suppose you have a trusted human judgment mechanism, and that mechanism has the legitimacy that the entire community trusts, but making judgments takes a long time and is costly. However, you want to access at least one approximate copy of that "expensive mechanism" in real-time at low cost. Here’s an idea proposed by Robin Hanson: every time you need to make a decision, you establish a prediction market predicting what result that expensive mechanism would yield if called. You let the prediction market run and put in a small amount of money to subsidize the market makers.
99.99% of the time, you actually won't call the expensive mechanism: maybe you'll "revoke the transaction" and return everyone's contributions, or you just give everyone zero, or you look at whether the average price is closer to 0 or 1 and treat it as a basic fact. 0.01% of the time—possibly random, possibly for the markets with the highest volume, possibly a combination of both—you will actually run the expensive mechanism and compensate participants accordingly.
This gives you a credible, neutral, fast, and cheap "distilled version" that reflects the behavior of your originally highly trusted but costly mechanism (using the term "distilled" as an analogy to "distillation" in LLMs). Over time, this distilled mechanism roughly reflects the behavior of the original mechanism—because only participants who help achieve that outcome can profit, while others will lose money.
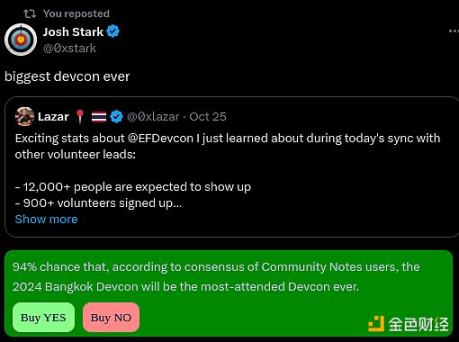
A model combining possible prediction markets + community notes.
This applies not only to social media but also to DAOs. One major issue with DAOs is that there are too many decisions, and most people are unwilling to participate, leading to either widespread use of delegation, which carries the risks of centralization and agency failure common in representative democracies, or vulnerability to attacks. If actual voting in a DAO occurs infrequently, and most decisions are determined by prediction markets predicting voting outcomes through a combination of humans and AI, then such a DAO could operate well.
As we saw in the example of decision markets, info finance contains many potential pathways to solve important issues in decentralized governance, with the key being the balance between market and non-market: the market is the "engine," while other non-financial trust mechanisms are the "steering wheel."
Other Use Cases of Info Finance
Personal tokens—such as Bitclout (now known as deso), friend.tech, and many other projects that create tokens for everyone and make them easy to speculate on—are a category I refer to as "primitive info finance." They deliberately create market prices for specific variables (i.e., the expected future reputation of a person), but the exact information revealed by the prices is too vague and subject to reflexivity and bubble dynamics. There is potential to create improved versions of such protocols and address important issues like talent discovery by more carefully considering the economic design of the tokens (especially where their ultimate value comes from). Robin Hanson's idea of reputation futures is a possible end state here.
Advertising—ultimately, the "expensive but trusted signal" is whether you will buy a product. Info finance based on that signal can help people determine what to purchase.
Scientific peer review—there has been a "replication crisis" in the scientific community, where certain well-known results have become part of common wisdom in some cases but ultimately cannot be replicated in new research. We could attempt to identify results that need to be re-examined through prediction markets. Before re-examination, such markets would also allow readers to quickly estimate how much they should trust any particular result. Experimental ideas in this vein have been conducted and seem to have been successful so far.
Public goods funding—one of the main issues with the public goods funding mechanisms used in Ethereum is their "popularity contest" nature. Each contributor needs to conduct their own marketing on social media to gain recognition, making it difficult for those who cannot do so or who naturally have more "background" roles to secure significant funding. An attractive solution is to try to track the entire dependency graph: for each positive outcome, which projects contributed how much, and then for each project, which projects contributed how much, and so on. The main challenge of this design is figuring out the weights of the edges to make it resistant to manipulation. After all, such manipulation has been occurring. A distilled human judgment mechanism may help.
Conclusion
These ideas have been theorized for a long time: the earliest works on prediction markets and even decision markets date back decades, while similar discussions in financial theory are even older. However, I believe the current decade presents a unique opportunity for the following reasons:
Info finance addresses the trust issues that people actually face. A common concern of this era is the lack of knowledge (worse yet, the lack of consensus) about whom to trust in political, scientific, and business environments. Info finance applications can help be part of the solution.
We now have scalable blockchains as a foundation. Until recently, the fees were too high to truly realize these ideas. Now, they are no longer prohibitively high.
AI as participants. When info finance has to rely on human participation for every issue, it is relatively difficult to operate effectively. AI greatly improves this situation, enabling effective markets even on small-scale issues. Many markets may have a combination of AI and human participants, especially when the number of specific issues suddenly shifts from small to large.
To fully leverage this opportunity, we should go beyond merely predicting elections and explore what else info finance can bring us.
Special thanks to Robin Hanson and Alex Tabarrok for their feedback and comments.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







