Google's DeepMind researchers have unveiled a new method to accelerate AI training, significantly reducing the computational resources and time needed to do the work. This new approach to the typically energy-intensive process could make AI development both faster and cheaper, according to a recent research paper—and that could be good news for the environment.
"Our approach—multimodal contrastive learning with joint example selection (JEST)—surpasses state-of-the-art models with up to 13 times fewer iterations and 10 times less computation," the study said.
The AI industry is known for its high energy consumption. Large-scale AI systems like ChatGPT require major processing power, which in turn demands a lot of energy and water for cooling these systems. Microsoft's water consumption, for example, reportedly spiked by 34% from 2021 to 2022 due to increased AI computing demands, with ChatGPT accused of consuming nearly half a liter of water every 5 to 50 prompts.
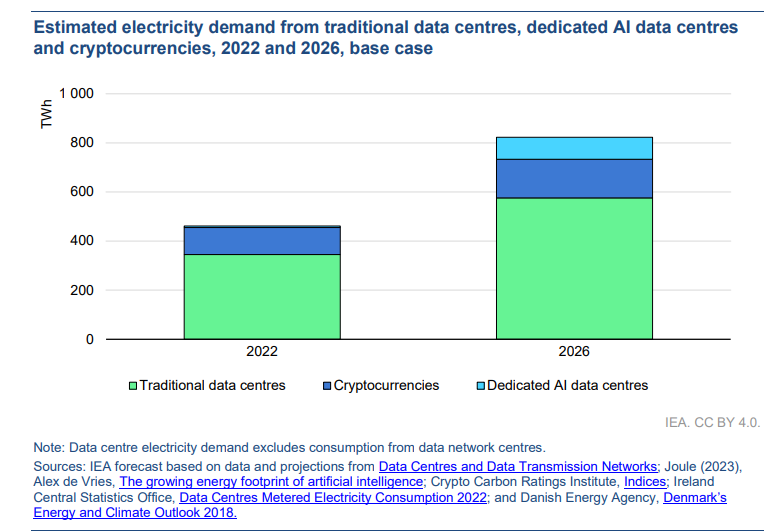
The International Energy Agency (IEA) projects that data center electricity consumption will double from 2022 to 2026—drawing comparisons between the power demands of AI and the oft-criticized energy profile of the cryptocurrency mining industry.
However, approaches like JEST could offer a solution. By optimizing data selection for AI training, Google said, JEST can significantly reduce the number of iterations and computational power needed, which could lower overall energy consumption. This method aligns with efforts to improve the efficiency of AI technologies and mitigate their environmental impact.
If the technique proves effective at scale, AI trainers will require only a fraction of the power used to train their models. This means that they could create either more powerful AI tools with the same resources they currently use, or consume fewer resources to develop newer models.
How JEST works
JEST operates by selecting complementary batches of data to maximize the AI model's learnability. Unlike traditional methods that select individual examples, this algorithm considers the composition of the entire set.
For instance, imagine you are learning multiple languages. Instead of learning English, German, and Norwegian separately, perhaps in order of difficulty, you might find it more effective to study them together in a way where the knowledge of one supports the learning of another.
Google took a similar approach, and it proved successful.
"We demonstrate that jointly selecting batches of data is more effective for learning than selecting examples independently," the researchers stated in their paper.
To do so, Google researchers used “multimodal contrastive learning,” where the JEST process identified dependencies between data points. This method improves the speed and efficiency of AI training while requiring much less computing power.
Key to the approach was starting with pre-trained reference models to steer the data selection process, Google noted. This technique allowed the model to focus on high-quality, well-curated datasets, further optimizing the training efficiency.
"The quality of a batch is also a function of its composition, in addition to the summed quality of its data points considered independently," the paper explained.
The study's experiments showed solid performance gains across various benchmarks. For instance, training on the common WebLI dataset using JEST showed remarkable improvements in learning speed and resource efficiency.
The researchers also found that the algorithm quickly discovered highly learnable sub-batches, accelerating the training process by focusing on specific pieces of data that “match” together. This technique, referred to as "data quality bootstrapping," values quality over quantity and has proven better for AI training.
"A reference model trained on a small curated dataset can effectively guide the curation of a much larger dataset, allowing the training of a model which strongly surpasses the quality of the reference model on many downstream tasks," the paper said.
Edited by Ryan Ozawa.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






