Source: Silicon Alien

Image Source: Generated by Wujie AI
As the world's top machine learning tool library, a new transformers model, Qwen2, has quietly appeared on Hugging Face recently. Yes, it is the second generation of the Qwen model from Alibaba Tongyi Qianwen. However, the algorithm team of Tongyi remains mysterious about this on social media.
"Let it remain a mystery"
In other words, the information on Hugging Face is equivalent to a "spoiler." The possibility of a spoiler indicates that the official "release" is not far away.
Every move of this full-size open-source model from China has attracted the attention of developers in the open-source community. So, what information does this spoiler reveal? Let's take a look.

According to the Overview section of the Qwen2 page, this new generation of the base model also includes versions of different parameter sizes. This brief introduction mentions that Qwen2 is based on the Transformer architecture, using a mix of SwiGLU activation, attention QKV bias, group query attention, sliding window attention, and full-sequence attention technologies. According to the introduction, Qwen2 also provides an improved tokenizer that adapts to various natural languages and code.
Let's briefly explain these technologies. First, SwiGLU activation. It is a type of activation function, formally known as Swish-Gated Linear Unit. Just by its name, it is clear that the SwiGLU activation function combines the characteristics of the Swish activation function and the Gated Linear Unit (GLU). The Swish activation function is a non-linear function that approaches a linear transformation as the input approaches positive infinity, which helps alleviate the vanishing gradient problem. GLU is a type of gated activation function commonly used in sequence modeling tasks. GLU divides the input into two parts, with one part passing through a Sigmoid gate and the other part passing through a tanh gate. The two are then element-wise multiplied to produce the final output. This gating mechanism allows the network to selectively pass information, enhancing modeling capabilities.
In the transformers model, the attention mechanism is a way of computation that allows the model to consider the dependencies between different positions when processing input sequences and dynamically allocate attention to different parts of the input. The core of the Transformer is the self-attention mechanism, which plays a crucial role in natural language processing tasks.
Self-attention can be represented as the word embedding of each input position being mapped to three different vector spaces: Query, Key, and Value. The Query vector is used to query relevant information, the Key vector is responsible for matching with the Query to determine relevance, and the Value vector contains the actual information that needs attention at each position. The attention QKV bias mentioned by Qwen2 happens to be the initials of Query, Key, and Value. This means that in the self-attention mechanism, by introducing bias terms, the model can more flexibly capture potential patterns or features in the input sequence and can fine-tune its attention behavior for specific tasks or datasets.
It uses a variant of the attention mechanism. In the traditional self-attention mechanism, all queries calculate attention weights by computing their similarity with all keys. In group query attention, the concept of grouping queries is introduced, and queries are divided into multiple groups, with each group of queries only calculating similarity with the corresponding group of keys to obtain attention weights.
The traditional self-attention mechanism requires calculating the similarity between all queries and keys, resulting in a computational complexity of the square of the input sequence length. Sliding window attention reduces the computational complexity by introducing the concept of a sliding window, limiting each query to calculate similarity with keys within a certain range around it.
In contrast, full-sequence attention allows each position in the model to attend to all other positions in the sequence and calculate weight allocation based on this. This mechanism can capture arbitrary distance dependencies between sequences, but it has a high computational cost for long sequences.
The hybrid attention mechanism formed by combining the two can maintain relatively low computational complexity while retaining and utilizing global context information as much as possible. For example, using local sliding window attention in certain layers to save resources, while using full-sequence attention in other layers or key nodes to ensure comprehensive capture of global dependencies.
Comparison of Qwen's capabilities
Finally, let's take a look at this "improved tokenizer." The so-called tokenizer, its English name is tokenizer. This name exposes its main function, which is to segment the original text data into a series of meaningful and manageable small units, often called tokens.
According to the technical report of Qwen (or different from Qwen2, it can be called Qwen1), it adopts a more efficient tokenizer in encoding different language information and demonstrates higher compression rates in multiple languages. According to the code submitted by Qwen2, some details of this "improved tokenizer" can be seen.
First, it still supports multiple languages: the tokenizer supports text processing in multiple languages by using Unicode characters and byte encoding, allowing it to handle text data containing multiple character sets. Secondly, it uses a cache to store the segmented results, which helps improve segmentation efficiency, especially when processing large amounts of text. Before segmentation, the tokenizer uses regular expressions (regex) to preprocess the text, which helps simplify subsequent segmentation steps, such as removing punctuation and non-alphanumeric characters.
In terms of overall approach, it still uses byte pair encoding (BPE), which is an effective vocabulary expansion method that builds a vocabulary table by iteratively merging the most common character pairs, thereby helping to handle unknown vocabulary (UNKs). It also provides various configuration options, such as error handling strategy (errors), unknown word token (unktoken), beginning-of-sequence token (bostoken), end-of-sequence token (eostoken), and padding token (padtoken). These options allow users to customize the behavior of the tokenizer according to specific needs.
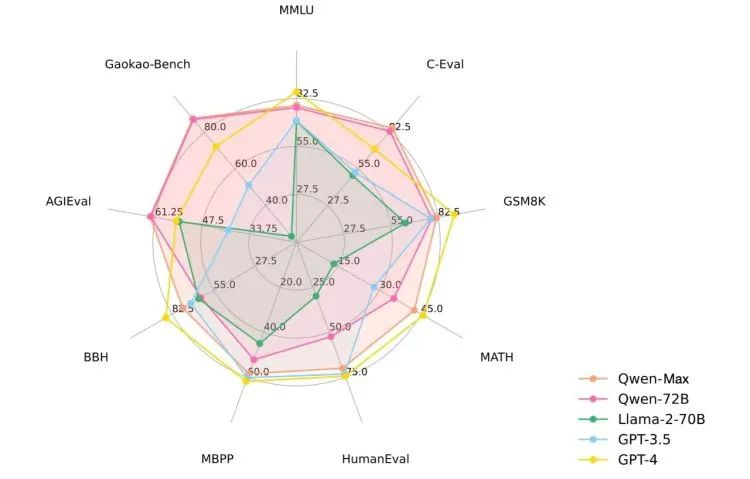
From these few spoilers, it can be seen that Qwen2 continues to improve the pre-training methods at the base model level. Since the release of Qwen, the entire Tongyi family has been iterating and updating at an astonishing speed, with Qwen-VL, Qwen-Audio, and others being successively released. Recently, Qwen-VL has just launched two upgraded versions, Qwen-VL-Plus and Max, achieving a significant improvement in multimodal capabilities.
This full-size and multi-category feature makes the Qwen series one of the most popular base models in the open-source community. In the "spoiler" code this time, it can also be seen that Qwen2 may first release its 7-billion-parameter version, named Qwen2-7B-beta and Qwen-7B-Chat-beta.

Moreover, another important piece of information is that the code currently uploaded shows that the open-source license for the Qwen2 model is still Apache 2.0, which means that this currently most comprehensive open-source large model in China will continue to be free for commercial use.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







