Original Source: AIGC Open Community

Image Source: Generated by Wujie AI
At the first OpenAI Developer Conference on November 7th, in addition to launching a series of heavyweight products, two products were also open-sourced: the new Consistency Decoder and the latest speech recognition model Whisper v3.
It is reported that the Consistency Decoder can replace the Stable Diffusion VAE decoder. This decoder can improve all images compatible with Stable Diffusion 1.0+ VAE, especially in text, faces, and straight lines. Within just one day of its launch, it received 1100 stars on Github.
Whisper large-v3 is the latest version of the previously open-sourced whisper model by OpenAI, with significant performance improvements in various languages. OpenAI will provide Whisper v3 in future API plans.
Decoder Address: https://github.com/openai/consistencydecoder
Whisper v3 Address: https://github.com/openai/whisper
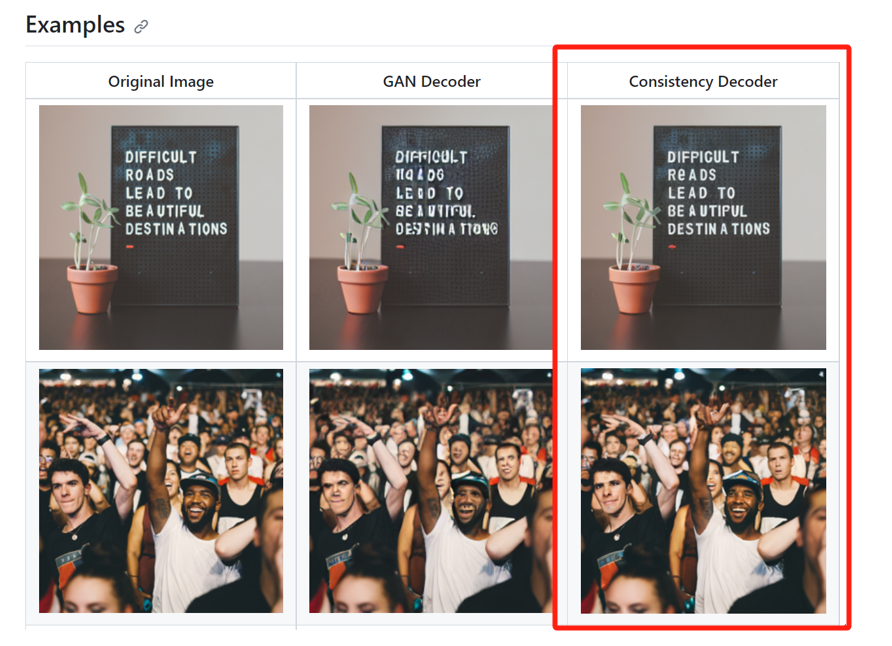
Consistency Decoder Effect Display
The Consistency Decoder is a new member of the OpenAI "consistency" family, so the "AIGC Open Community" would like to introduce another innovative model previously open-sourced by OpenAI—Consistency Models.
The emergence of diffusion models has greatly promoted the development of various fields such as text, images, videos, and audio, leading to the emergence of well-known models such as GAN and VAE. However, these models rely too much on iterative sampling processes during inference, resulting in very slow generation efficiency or poor image quality.
To break through this technological bottleneck, OpenAI proposed the Consistency Models framework and open-sourced it. The biggest advantage of this technology is to support high-quality single-step generation while retaining the advantages of iterative generation. In simple terms, it can make text and image models fast and accurate in the inference process, achieving both offense and defense.
In addition, Consistency Models can be used by extracting pre-trained diffusion models, or trained as independent generation models, with strong compatibility and flexibility.
Open Source Address: https://github.com/openai/consistency_models
Paper: https://arxiv.org/abs/2303.01469
To help everyone better understand the technical characteristics of Consistency Models, the "AIGC Open Community" will first briefly introduce the principles of diffusion models.
What Is a Diffusion Model
The diffusion model mainly generates data by simulating the diffusion process, with the core technology being to consider the data as the result of a simple random process (e.g., Gaussian white noise) undergoing a series of smoothing transformations.
The diffusion model mainly consists of two major components: Forward Process (Diffusion Process): The original data is gradually diffused by adding noise until it becomes unrecognizable noise.
Specifically, a little noise is added at each step, and the intensity of the noise usually increases as the steps progress. This process can be described by a stochastic differential equation.
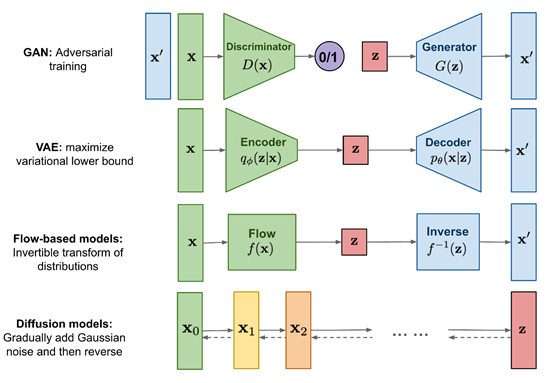
Reverse Process (Denoising Process): Then, a learned model is used to reconstruct the original data from the noisy data.
This process is usually carried out by optimizing an objective function, with the goal of making the reconstructed data as similar as possible to the original data.
Introduction to Consistency Models
Inspired by the diffusion model technology, Consistency Models directly map noise to data distribution, generating high-quality images without the need for an iterative process. Experimental results have shown that if the points on the same trajectory of the model output remain consistent, this mapping can be effectively learned.

In simple terms, Consistency Models directly abandon the step-by-step denoising process and instead directly learn to map random noise to complex images, while adding consistency rules to avoid situations where the generated images do not match expectations.
To put it more plainly, if we were to make a mapo tofu, we would need to cut the tofu, prepare the ingredients, stir-fry in a wok over high heat, add seasoning, and then serve. However, the method of Consistency Models is to directly produce a plate of mapo tofu, skipping all the preparation processes, and the taste and dish are made according to the user's standards, which is the magic of this technology.
Based on the above technical concepts, OpenAI researchers used two methods, knowledge distillation and direct training, to train Consistency Models.
Knowledge Distillation: Using a pre-trained diffusion model (such as Diffusion) to generate some data pairs, and then training Consistency Models to make the outputs of these data pairs as close as possible, to perform knowledge distillation with the diffusion model.

Direct Training Method: Learning the mapping from data to noise directly from the training set samples, without relying on pre-trained models. The main approach is to perform data augmentation by adding noise, and then optimize the consistency between the output before and after augmentation.
Experimental Data
Researchers tested Consistency Models on multiple image datasets, including CIFAR-10, ImageNet 64x64, and LSUN 256x256.
The results show that knowledge distillation-trained Consistency Models performed the best, surpassing the best existing distillation technique, Progressive Distillation, on all datasets and steps.
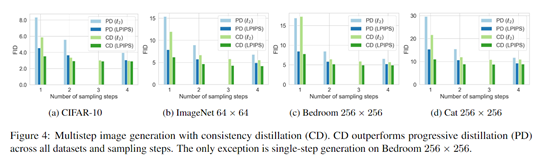
For example, on CIFAR-10, single-step generation achieved a new record FID of 3.55, and two-step generation achieved 2.93; on ImageNet 64x64, single-step generation had an FID of 6.20, and two-step generation had 4.70, both setting new records.
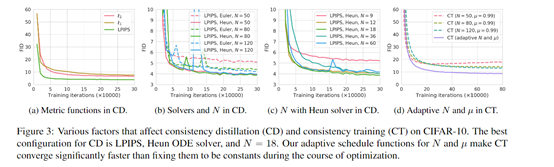
Under the direct training method, Consistency Models also demonstrated strong capabilities, outperforming most single-step generation models on CIFAR-10 and approaching Progressive Distillation in quality.
In addition, the model supports zero-shot image editing, enabling various tasks such as image denoising, interpolation, coloring, super-resolution generation, and stroke generation without the need for specific training.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







