Source: New Wisdom

Image Source: Generated by Wujie AI
GPT-3.5 only has 200 billion parameters?
Today, the big model circle was blown up by a screenshot in a Microsoft paper. What's going on?
Just a few days ago, Microsoft published a paper and posted it on arXiv, proposing a small-scale diffusion model called CodeFusion with only 75 million parameters.
In terms of performance, the 75 million parameter CodeFusion can compete with state-of-the-art 350M-175B models in terms of top-1 accuracy.

Paper link: https://arxiv.org/abs/2310.17680
The work of this paper is very meaningful, but what caught everyone's attention is—
When comparing with ChatGPT (gpt-3.5-turbo), the nominal parameter size is only 20B!
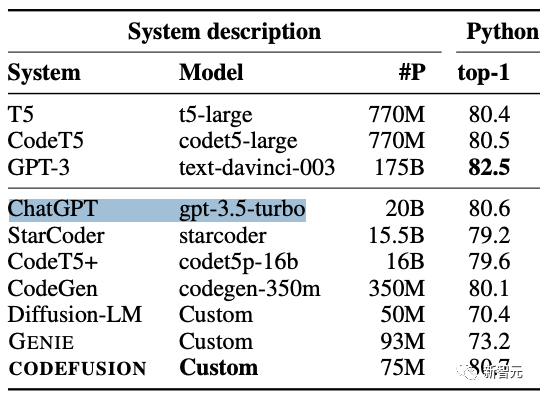
Before this, everyone's guess for the parameter size of GPT-3.5 was 175 billion, which is almost ten times larger!
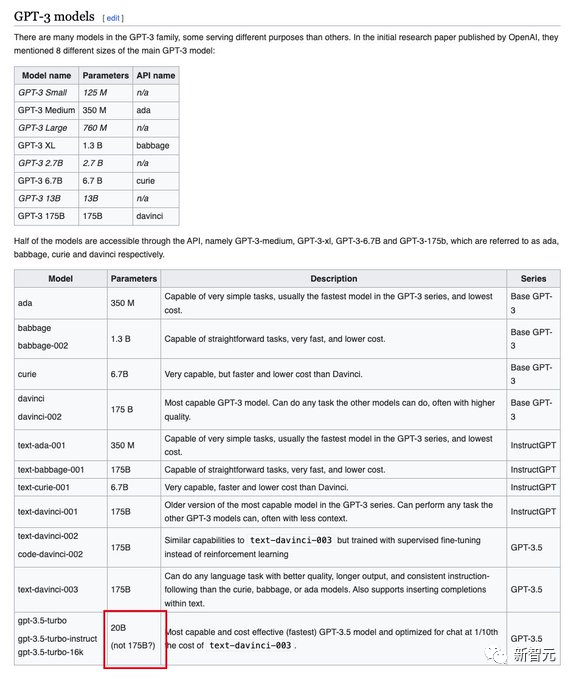
According to the revelations in this paper, netizens have also updated the introduction of GPT-3.5 on Wikipedia, directly changing the parameter size to 20B.
As soon as the news came out, it directly hit the hot search on Zhihu, and netizens were all shocked.

Some people said, "I need to review the blog post about distilling my previous model."

Is it a "mistake" or a "fact"?
The netizen's revelation post instantly sparked intense discussions.
Currently, more than 680,000 people have come to watch.
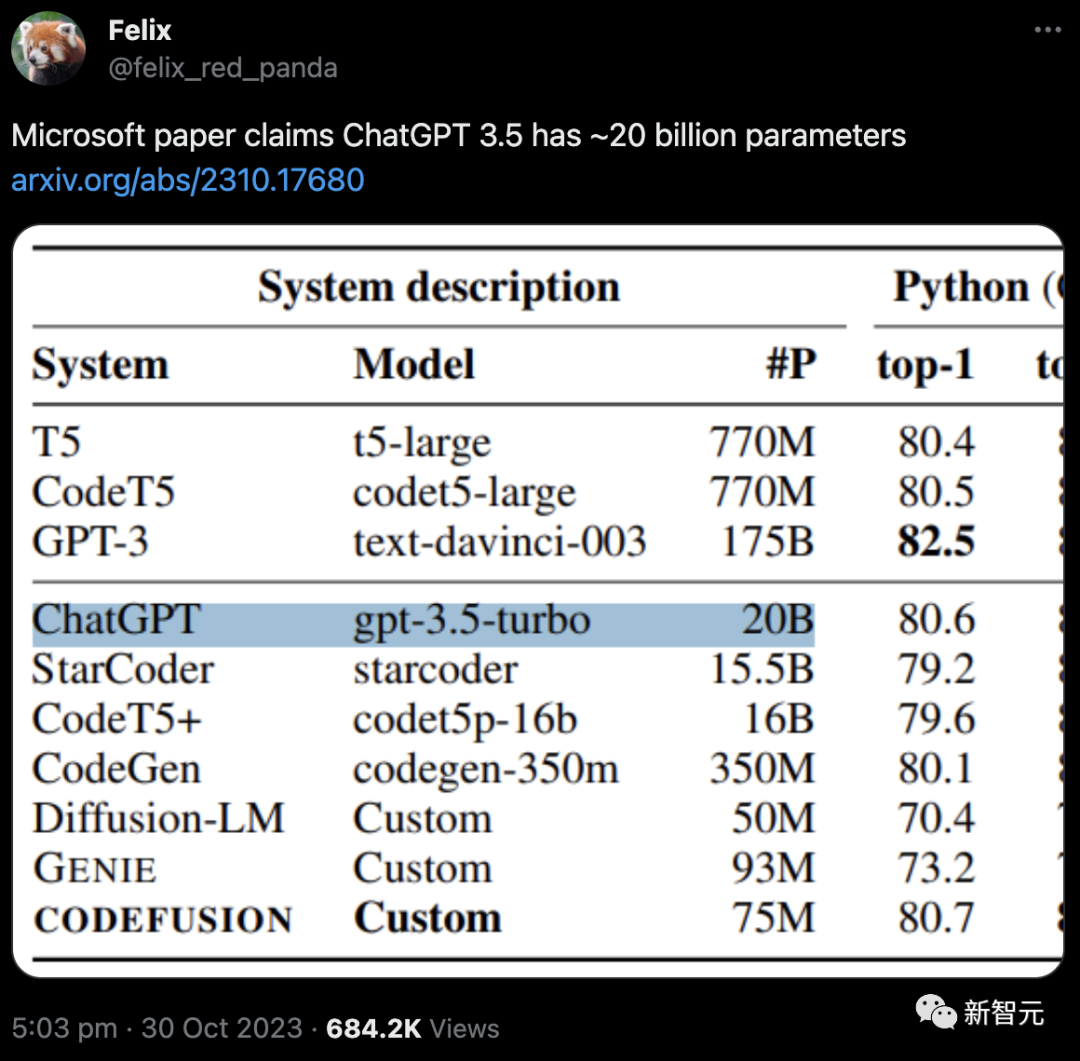
This guy said that several authors of the paper are also using Twitter, and it is estimated that they will personally come forward to explain soon.

As for this mysterious "20B," netizens have different opinions.

Some speculate that this is likely a typo by the author. For example, it was originally 120B, or 200B.

Considering various real-world evaluations, there are indeed many small models that can achieve similar results to ChatGPT, such as Mistral-7B.

Perhaps this also indirectly confirms that the size of GPT-3.5 is not large.
Many netizens also believe that the 20B parameter may be accurate, and they exclaimed:
"It's hard to imagine! Falcon-180B and Llama2-70B can't even beat this 20B model."
Some netizens also believe that gpt-3.5-turbo is a refined version of gpt-3.5.
And this "leak" of parameters just indirectly confirms the rumors that gpt-3.5-turbo does not perform as well as the old version of gpt-3.5.
However, according to OpenAI's official documentation, except for the no longer used text-davinci and code-davinci, all members of the GPT-3.5 family are based on gpt-3.5-turbo.



Microsoft Releases CodeFusion
The Microsoft paper that revealed GPT3.5 only has 20B parameters aims to introduce a diffusion model for code generation.
Researchers evaluated this model—CodeFusion—on the task of generating code for Bash, Python, and Microsoft Excel conditional formatting (CF) rules using natural language.
Experiments show that CodeFusion (with only 75M parameters) is comparable to the state-of-the-art LLM (350M-175B parameters) in terms of top-1 accuracy, and its performance and parameter ratio are excellent in top-3 and top-5 accuracy.
Model Architecture
CODEFUSION is used for code generation tasks, and its training is divided into two stages: unsupervised pre-training and supervised fine-tuning.
In the first stage, CODEFUSION uses unlabeled code snippets to train denoisers and decoders. It also uses a trainable embedding layer L to embed code snippets into a continuous space.
In the second stage, CODEFUSION undergoes supervised fine-tuning using text-code pair data. In this stage, the encoder, denoiser, and decoder are adjusted to better perform the task.
In addition, CODEFUSION also draws on previous research on text diffusion, integrating hidden representations D from the decoder into the model to improve performance. During the training process, the model introduces some noise at different steps, then calculates the loss function to ensure that the generated code snippets better meet the expected standards.
In summary, CODEFUSION is a small model for code generation tasks, continuously improving its performance through two stages of training and noise introduction. This model is inspired by research on text diffusion and improves the loss function by integrating hidden representations from the decoder to generate high-quality code snippets.
Evaluation Results
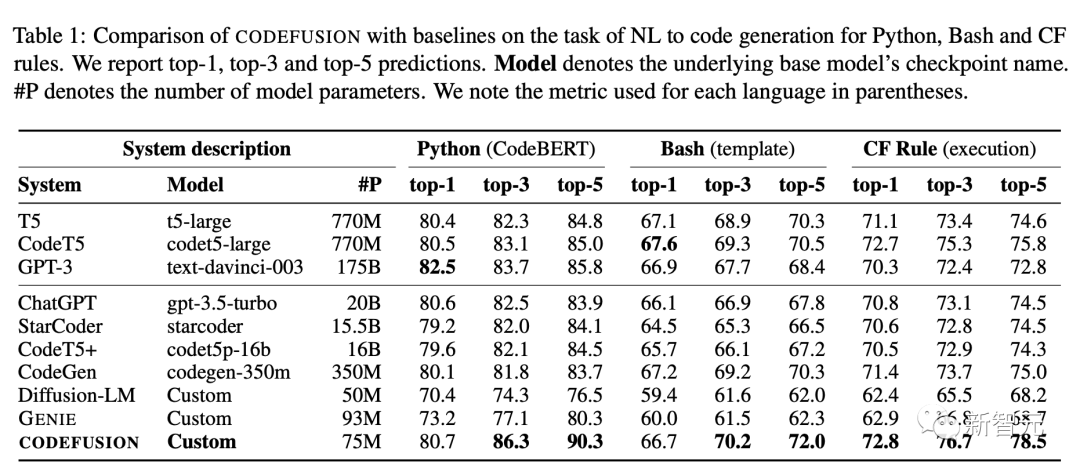
The table below summarizes the performance of the CODEFUSION model compared to various baseline models in top-1, top-3, and top-5 settings.
In top-1, CODEFUSION's performance is comparable to autoregressive models, and in some cases, it performs even better, especially in Python tasks, where only GPT-3 (175B) slightly outperforms CODEFUSION (75M). However, in top-3 and top-5, CODEFUSION is significantly better than all baseline models.
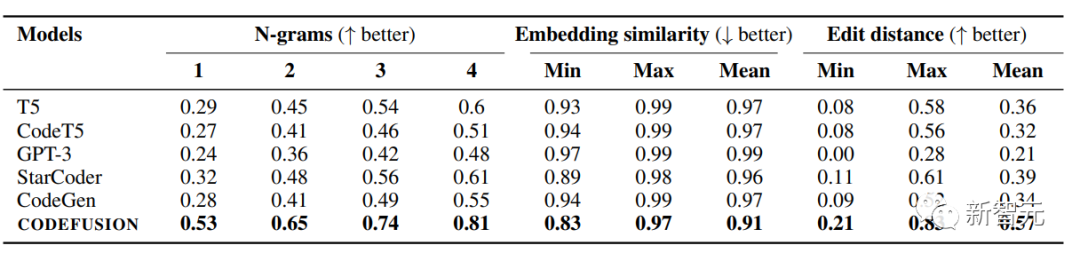
The table below shows the average diversity results of CODEFUSION and autoregressive models (including T5, CodeT5, StarCoder, CodeGen, GPT-3) in various benchmark tasks, examining the top 5 generations of each model.
Compared to autoregressive models, CODEFUSION generates more diverse results and performs better.
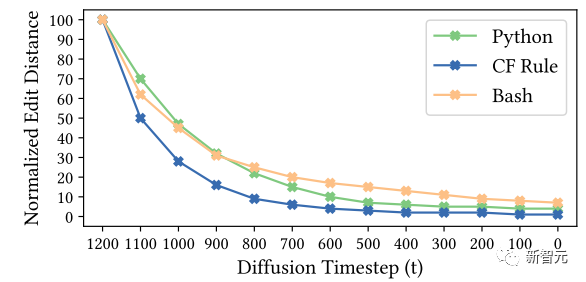
In the ablation experiment, the authors stopped the denoising process and generated code snippets for the current state at time step t ∈ [0, T]. The results obtained at each time step (with an increment of 100 steps) were measured using normalized string edit distance.
This method helps summarize and demonstrate the step-by-step progress of the CODEFUSION model, as shown in the following figure.
After all that's been said, how many parameters does GPT-3.5 actually have? What is the relationship between GPT-4 and GPT-3.5 in terms of technology and other aspects?
Is GPT-3.5 an ensemble of small expert models or a versatile model? Is it achieved through distillation of larger models or training on larger datasets?
The answers to these questions can only be revealed when it is truly open-sourced.
References:
https://arxiv.org/abs/2310.17680
https://twitter.com/felixredpanda/status/1718916631512949248
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








