Let me share some thoughts after watching the #Grok3 launch event today. I can describe it in a few words: mixed feelings, as we are falling into a confirmation bias (as shown in Figure 4).
Although I am not a professional AI investor, I can be considered an outstanding amateur in AI investment. Let me explain why I feel this way, based on my experiences from this afternoon.
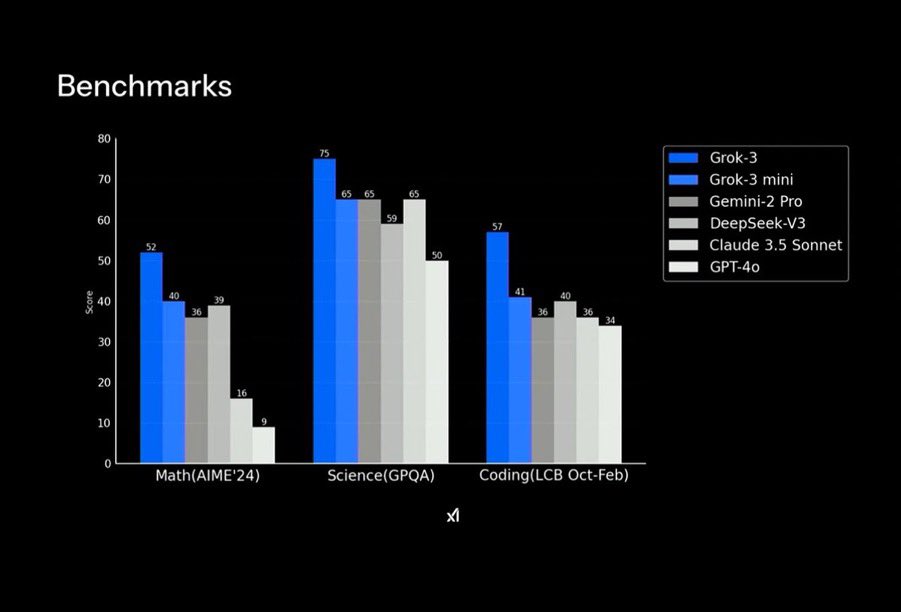
First of all, it is certain that the performance score of #Grok3 indeed surpasses many currently known mainstream models, especially in benchmark tests for mathematics, science, and programming, where it can be described as far ahead. The Grok3 Reasoning Beta, which possesses reasoning capabilities, is an unbeatable presence, just as Musk said, currently the most powerful AI model on Earth, with no flaws. However, I still express some disappointment.
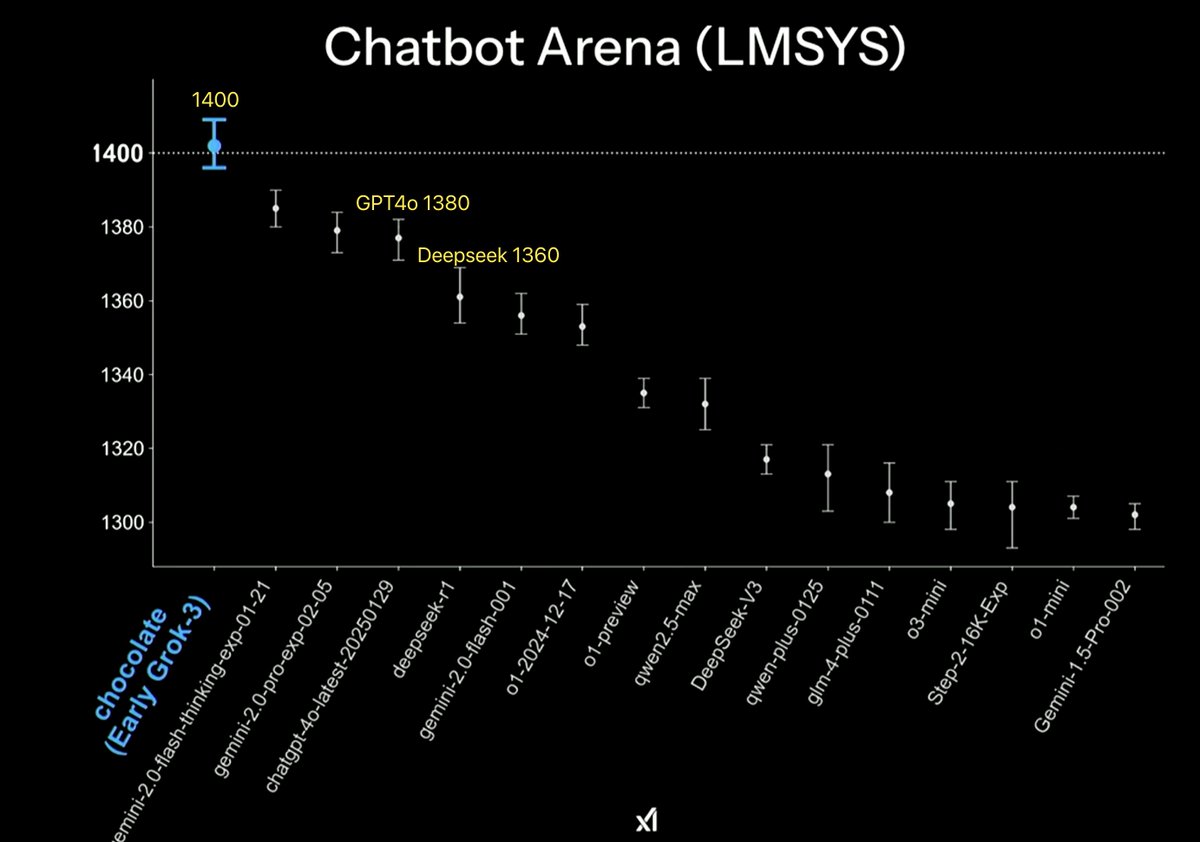
Why do I say this? From the actual situation, especially the evaluation data from LMSYS 📊, we can see that Grok3 scored 1400, GPT4o scored 1380, and Deepseek R1 scored 1360. The difference between them is not too significant, around 1%-3%. However, based on my experience from an afternoon of testing using Big-Bench and CLUE, including some classic Tower of Hanoi problems, multimodal recognition, and writing sorting algorithms in Python, the actual performance is comparable to GPT4o and Deepseek, but in Python, the speed and accuracy are slightly lower than Deepseek.
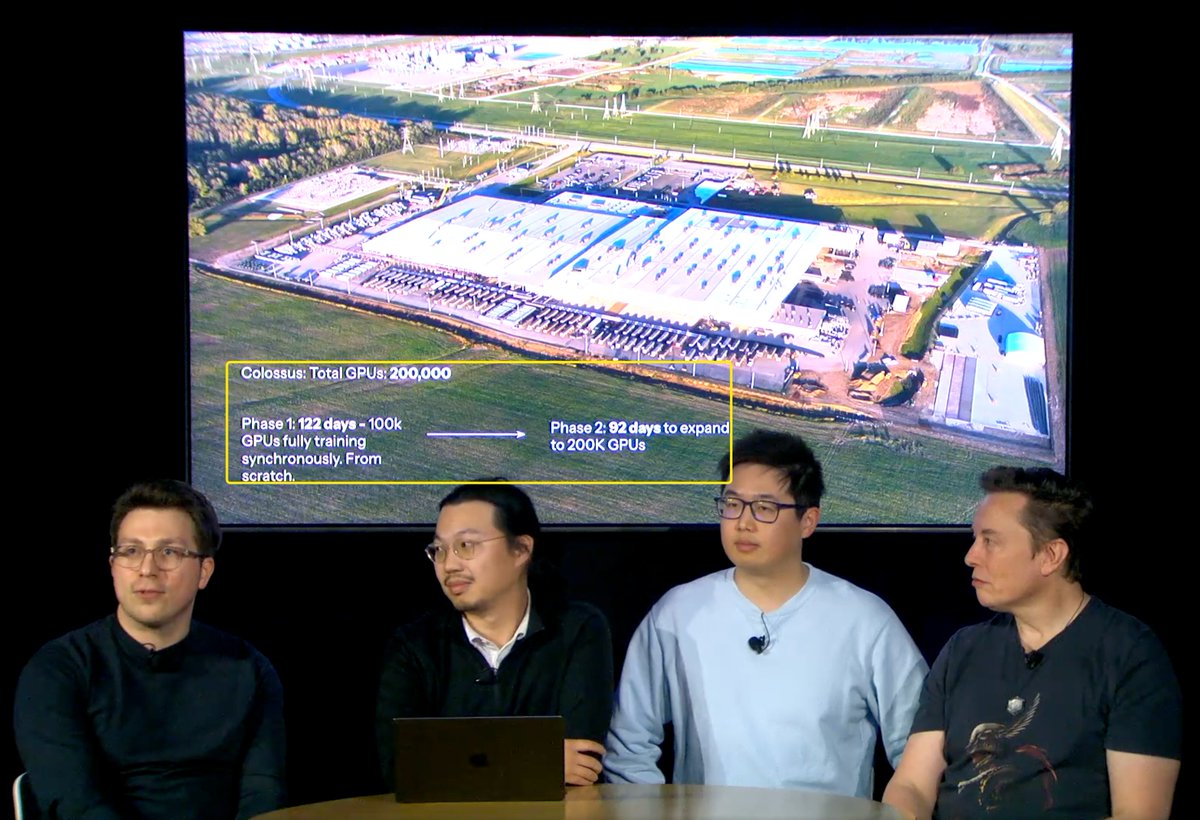
The key point is that achieving this performance comes at a considerable cost for #Grok3, with 200,000 GPUs (reportedly H100), accumulating 200 million GPU hours during training. I can only say that the cost is too high, with a significant waste of energy. GPT4o achieved 1380 points at only one-tenth of the cost, and Deepseek (using the older H800 GPUs) achieved 1360 points at only one-hundredth of the cost. One can only say that financial power is impressive; the landlord's family is indeed wealthy. It feels like using a cannon to shoot a mosquito.
Why do I say that many in #AI have fallen into a 'confirmation bias', believing that simply increasing the radius of a circle will increase its area? They have faith in the 'scale effect'. If the development of #AI continues with everyone piling up performance scores and scale, it would be a massacre and irresponsibility towards the human environment. At a certain scale, the marginal effect begins to diminish.
Therefore, the current development of AI faces a critical 'confirmation bias': over-reliance on scale effects while neglecting the true enhancement of efficiency and the core of intelligence. With the rise of large models like GPT-3, GPT-4, and the soon-to-be-released Grok-3, the industry generally believes that as the number of parameters increases, the model's performance will inevitably improve. However, the reality is that as the model size continues to expand, the marginal effect diminishes, and performance improvements do not grow proportionally as expected. For example, GPT-3 has 175 billion parameters, while GPT-4's parameter count reaches 1.8 trillion, an increase of more than ten times, but its performance improvement has not reached ten times. This trend reveals that simply increasing scale and computing power cannot continuously lead to qualitative breakthroughs.
Moreover, the expansion of data scale has not brought the expected performance improvements. Decades of internet data have been consumed, yet AI performance has not achieved dozens or hundreds of times improvement. In contrast, the human brain has puzzled early biologists who could not explain why humans are smarter than other animals. The weight of the human brain cannot compete with that of an elephant, and the number of neurons does not surpass that of a blue whale. So, in terms of computing power, the human brain does not have a significant advantage. As for data, it is even more lacking; most birds have access to visual data that far surpasses that of humans. However, the core advantage of humans is: algorithms. Recently, Fei-Fei Li's team replicated Deepseek's paper with just fifty dollars, proving that the core of an AI model's strength lies in its ability to think and reason, rather than its scale.
Thus, while humans cannot compete with large-scale AI models in terms of computing power and data volume, their core intelligence lies in the efficient operation of algorithms and thinking methods. The human brain does not rely on vast amounts of data but responds flexibly to complex tasks through highly optimized algorithms and reasoning abilities. The power consumption of the human brain is only 20-30 watts, while models like GPT-4 require enormous electricity and computing power, currently maintaining ChatGPT's daily consumption of over 500,000 kilowatt-hours, equivalent to the electricity usage of 20,000 American households. The newly released Grok3 is likely to multiply that by ten, leading to extremely high energy costs and environmental issues.
This is also why innovative AI models like DeepSeek are gradually gaining attention. DeepSeek's core advantage lies in its Mixture of Experts (MOE) model, which is similar to the learning methods of the human brain. Through reinforcement learning mechanisms, AI can achieve intelligence enhancement at lower computational costs. The MOE model adjusts model weights through a reward and punishment mechanism for agents, guiding AI to reason and make decisions more efficiently, rather than simply learning through memory and rules. This approach can avoid the common resource waste seen in training large models and improve the learning efficiency of the model.
In contrast, while the large scale and complexity of large AI models can enhance performance in the short term, as the scale increases, the performance improvements will gradually level off, even showing diminishing marginal effects. Taking Grok3 as an example, despite the surge in the number of GPUs, the performance improvement of the model may not meet the cost invested. If AI development continues to rely solely on computational and data volume, it may face issues of resource waste and uncontrollable costs in the future.
Therefore, future AI development should focus more on efficiency rather than scale. By optimizing algorithms, increasing intelligence density, and utilizing reinforcement learning, AI can enhance true reasoning and judgment capabilities with lower computational and data resource consumption. This will be key to the evolution of AI technology from large-scale reasoning to efficient intelligence, potentially leading the entire industry into a new stage of development. It is worth pondering 🧐

免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







