DeepSeek Model Shakes Silicon Valley, Its Value Continues to Rise
Author: APPSO
In the past week, the DeepSeek R1 model from China has stirred the entire overseas AI community.
On one hand, it achieves performance comparable to OpenAI's o1 with lower training costs, illustrating China's advantages in engineering capabilities and large-scale innovation; on the other hand, it upholds the spirit of open source and is keen on sharing technical details.
Recently, a research team led by Jiayi Pan, a PhD student at the University of California, Berkeley, successfully replicated the key technology of DeepSeek R1-Zero—"Eureka Moment"—at an extremely low cost (under $30).

It is no wonder that Meta CEO Mark Zuckerberg, Turing Award winner Yann LeCun, and DeepMind CEO Demis Hassabis have all given high praise to DeepSeek.
As the popularity of DeepSeek R1 continues to rise, this afternoon, the DeepSeek App briefly experienced server congestion due to a surge in user traffic, even "crashing" at one point.
OpenAI CEO Sam Altman also attempted to leak usage limits for o3-mini to reclaim the front page of international media—ChatGPT Plus members can query 100 times a day.
However, little known is that before its rise to fame, DeepSeek's parent company, Hquant, was actually one of the leading firms in the domestic quantitative private equity sector.
DeepSeek Model Shakes Silicon Valley, Its Value Continues to Rise
On December 26, 2024, DeepSeek officially released the DeepSeek-V3 large model.
This model performed excellently in multiple benchmark tests, surpassing mainstream top models in the industry, especially in knowledge Q&A, long text processing, code generation, and mathematical capabilities. For example, in knowledge tasks like MMLU and GPQA, DeepSeek-V3's performance is close to the internationally top models Claude-3.5-Sonnet.
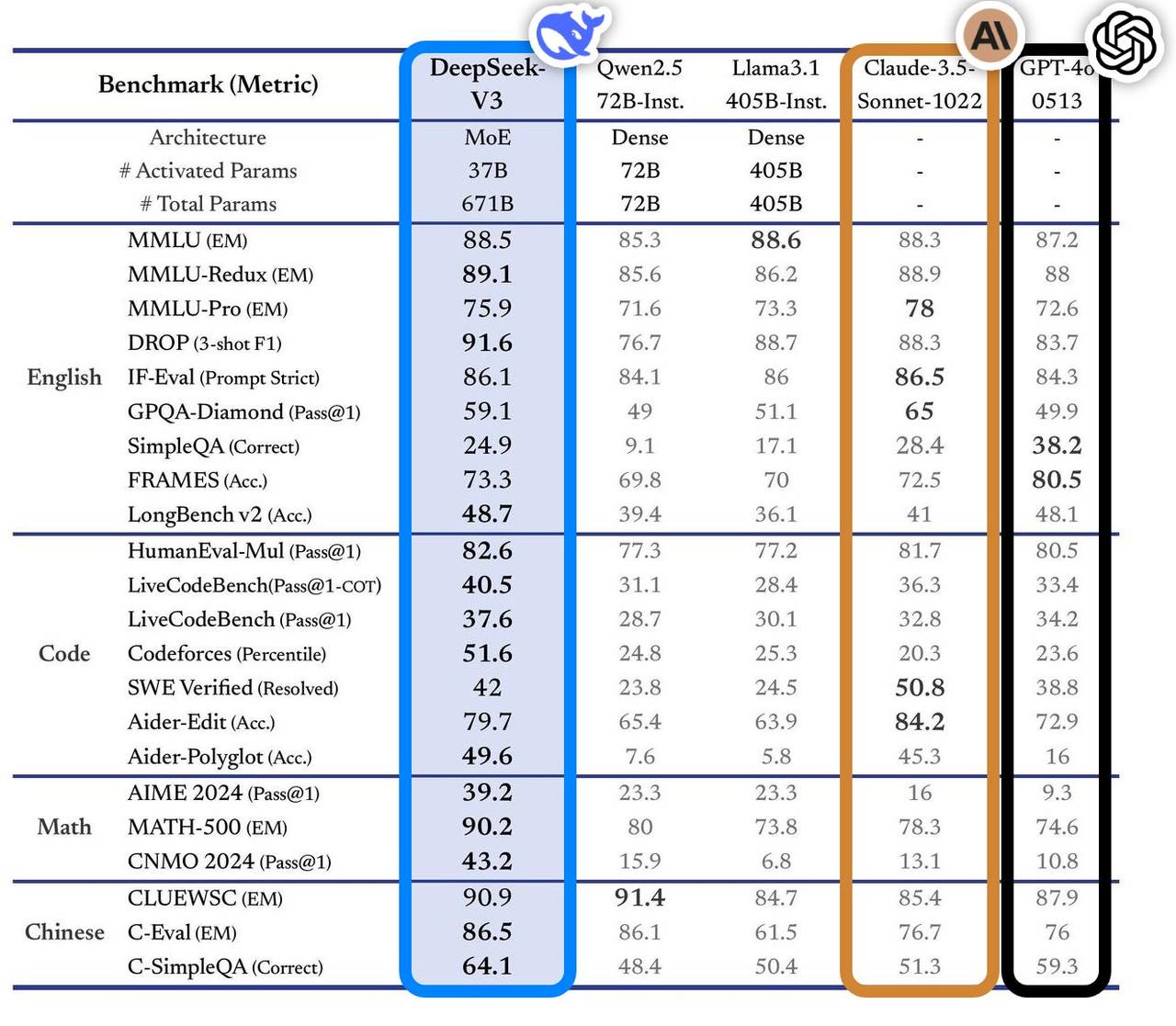
In terms of mathematical capabilities, it set new records in tests like AIME 2024 and CNMO 2024, surpassing all known open-source and closed-source models. At the same time, its generation speed improved by 200% compared to the previous generation, reaching 60 TPS, significantly enhancing user experience.
According to an analysis by the independent evaluation site Artificial Analysis, DeepSeek-V3 surpassed other open-source models on multiple key metrics and performed on par with the world's top closed-source models GPT-4o and Claude-3.5-Sonnet.
The core technological advantages of DeepSeek-V3 include:
Mixture of Experts (MoE) architecture: DeepSeek-V3 has 671 billion parameters, but in actual operation, only 37 billion parameters are activated for each input. This selective activation greatly reduces computational costs while maintaining high performance.
Multi-Head Latent Attention (MLA): This architecture has been validated in DeepSeek-V2 and enables efficient training and inference.
Load balancing strategy without auxiliary loss: This strategy aims to minimize the negative impact of load balancing on model performance.
Multi-token prediction training objectives: This strategy enhances the overall performance of the model.
Efficient training framework: Utilizing the HAI-LLM framework, it supports 16-way Pipeline Parallelism (PP), 64-way Expert Parallelism (EP), and ZeRO-1 Data Parallelism (DP), and reduces training costs through various optimization methods.
More importantly, the training cost of DeepSeek-V3 is only $5.58 million, far lower than the $78 million training cost of GPT-4. Moreover, its API service pricing continues to be user-friendly.
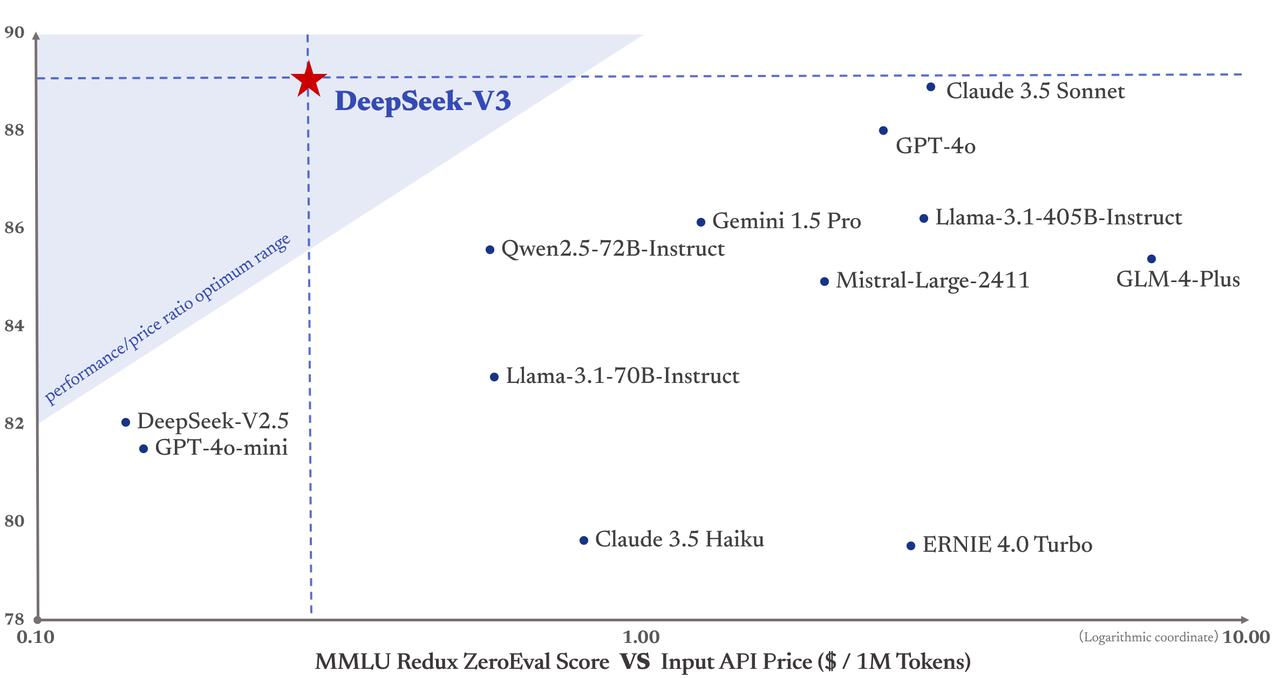
Input tokens cost only 0.5 yuan per million (cache hit) or 2 yuan (cache miss), while output tokens cost only 8 yuan per million.
The Financial Times described it as "a dark horse that shocked the international tech community," believing its performance is comparable to that of well-funded American competitors like OpenAI. Chris McKay, founder of Maginative, further pointed out that the success of DeepSeek-V3 may redefine the established methods of AI model development.
In other words, the success of DeepSeek-V3 is also seen as a direct response to the U.S. export restrictions on computing power, with this external pressure stimulating innovation in China.
DeepSeek Founder Liang Wenfeng, the Low-Key Genius from Zhejiang University
The rise of DeepSeek has left Silicon Valley restless, and the founder Liang Wenfeng, who is behind this model that is shaking the global AI industry, perfectly embodies the traditional trajectory of genius in China—achieving success at a young age and remaining relevant over time.
A good AI company leader needs to understand both technology and business, have vision and pragmatism, possess innovative courage and engineering discipline. Such composite talents are themselves a scarce resource.
At 17, he was admitted to Zhejiang University, majoring in Information and Electronic Engineering, and at 30, he founded Hquant, beginning to lead a team in exploring fully automated quantitative trading. Liang Wenfeng's story confirms that geniuses always do the right thing at the right time.

2010: With the launch of the CSI 300 stock index futures, quantitative investment welcomed development opportunities, and the Hquant team seized the momentum, rapidly increasing self-operated funds.
2015: Liang Wenfeng co-founded Hquant with alumni, launching the first AI model the following year, which went live with deep learning-generated trading positions.
2017: Hquant claimed to have fully AI-ified its investment strategies.
2018: Established AI as the company's main development direction.
2019: Fund management scale surpassed 10 billion yuan, becoming one of the "four giants" in domestic quantitative private equity.
2021: Hquant became the first quantitative private equity firm in China to surpass 100 billion yuan in scale.
You cannot only remember this company during its successful moments, forgetting the years it spent in obscurity. However, just like the transformation of quantitative trading companies into AI, which seems unexpected but is actually a natural progression—because they are both data-driven, technology-intensive industries.
Jensen Huang only wanted to sell gaming graphics cards to profit from us gamers, but unexpectedly became the world's largest AI arsenal; Hquant's entry into the AI field is similarly remarkable. This evolution is more vital than many industries that awkwardly apply AI large models.
Hquant has accumulated a wealth of data processing and algorithm optimization experience during its quantitative investment process, and possesses a large number of A100 chips, providing strong hardware support for AI model training. Since 2017, Hquant has been laying out AI computing power on a large scale, building high-performance computing clusters like "Firefly One" and "Firefly Two" to provide robust computing support for AI model training.

In 2023, Hquant officially established DeepSeek, focusing on the research and development of large AI models. DeepSeek inherits Hquant's accumulation in technology, talent, and resources, quickly emerging in the AI field.
In a deep interview with "Dark Current," DeepSeek founder Liang Wenfeng also demonstrated a unique strategic vision.
Unlike most Chinese companies that choose to replicate the Llama architecture, DeepSeek directly addresses the model structure, aiming for the grand goal of AGI.
Liang Wenfeng candidly acknowledges the significant gap between current Chinese AI and international top levels, stating that the comprehensive gap in model structure, training dynamics, and data efficiency requires four times the computing power to achieve the same effect.

▲ Image from CCTV News screenshot
This attitude of facing challenges head-on stems from Liang Wenfeng's years of experience at Hquant.
He emphasizes that open source is not only about technology sharing but also a form of cultural expression; the real moat lies in the team's continuous innovation capability. DeepSeek's unique organizational culture encourages bottom-up innovation, downplays hierarchy, and values the enthusiasm and creativity of talent.
The team is mainly composed of young people from top universities, adopting a natural division of labor model that allows employees to explore and collaborate autonomously. When hiring, they place more emphasis on employees' passion and curiosity rather than traditional notions of experience and background.
Regarding the industry's prospects, Liang Wenfeng believes that AI is currently in a period of technological innovation explosion, rather than an application explosion. He emphasizes that China needs more original technological innovations and cannot remain in the imitation stage forever; someone needs to stand at the forefront of technology.
Even though companies like OpenAI are currently in a leading position, opportunities for innovation still exist.

DeepSeek Turns Silicon Valley Upside Down, Leaving the Overseas AI Community Restless
Although the industry's evaluations of DeepSeek vary, we have also gathered some comments from industry insiders.
Jim Fan, head of the GEAR Lab project at NVIDIA, gave high praise to DeepSeek-R1.
He pointed out that this represents non-American companies practicing OpenAI's original open mission, achieving influence through the public release of raw algorithms and learning curves, while also implicitly critiquing OpenAI.
DeepSeek-R1 not only open-sourced a series of models but also disclosed all training secrets. They may be the first to demonstrate significant and sustained growth in the RL (Reinforcement Learning) flywheel as an open-source project.
Influence can be achieved through legendary projects like "ASI Internal Implementation" or "Strawberry Project," or simply by publicly sharing raw algorithms and matplotlib learning curves.
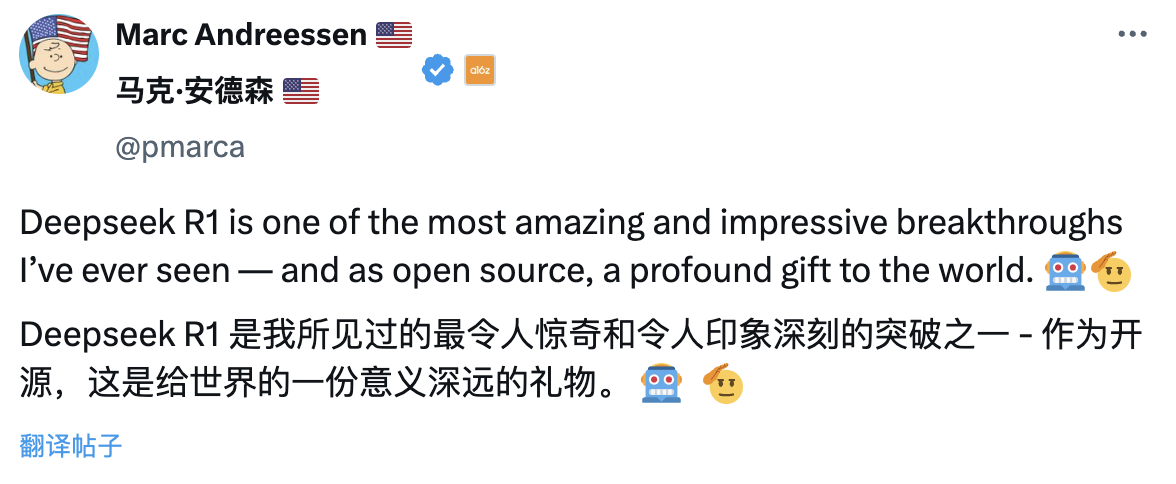
Marc Andreesen, founder of top Wall Street venture capital firm A16Z, believes that DeepSeek R1 is one of the most astonishing and impressive breakthroughs he has ever seen, and as an open-source project, it is a profoundly meaningful gift to the world.
Lu Jing, a former senior researcher at Tencent and a postdoctoral fellow in artificial intelligence at Peking University, analyzed from the perspective of technological accumulation. He pointed out that DeepSeek did not suddenly become popular; it inherited many innovations from the previous generation of model versions, and the iterative validation of related model architectures and algorithm innovations made its industry impact inevitable.
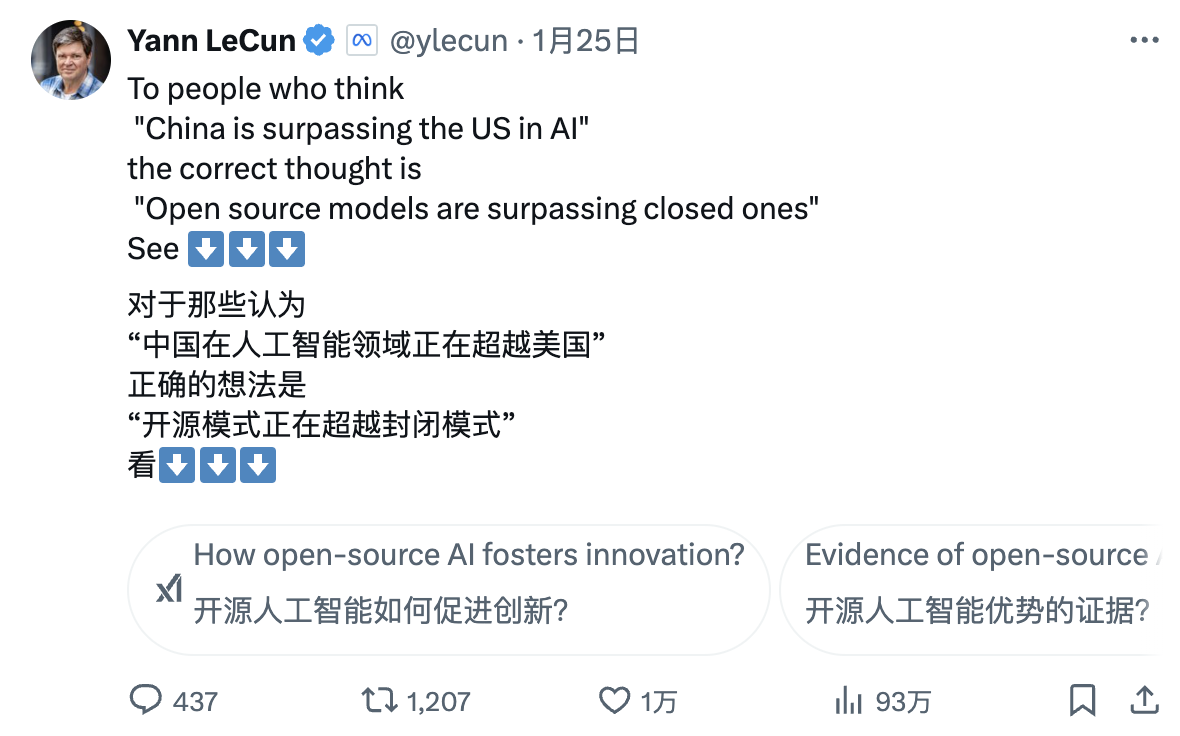
Yann LeCun, Turing Award winner and Chief AI Scientist at Meta, offered a new perspective:
"For those who see DeepSeek's performance and think 'China is surpassing the U.S. in AI,' your interpretation is wrong. The correct interpretation should be, 'Open-source models are surpassing proprietary models.'"
Demis Hassabis, CEO of DeepMind, expressed a hint of concern:
"The achievements of DeepSeek are impressive. I think we need to consider how to maintain the leading position of Western frontier models. I believe the West is still ahead, but it is certain that China has extremely strong engineering and scaling capabilities."
Satya Nadella, CEO of Microsoft, stated at the World Economic Forum in Davos, Switzerland, that DeepSeek has effectively developed an open-source model that not only performs excellently in inference computing but also has extremely high supercomputing efficiency.
He emphasized that Microsoft must respond to these groundbreaking advancements from China with the utmost seriousness.
Meta CEO Mark Zuckerberg provided a deeper evaluation, stating that the technical strength and performance demonstrated by DeepSeek are impressive, and pointed out that the AI gap between China and the U.S. has become minimal, making the competition increasingly intense due to China's full-speed sprint.
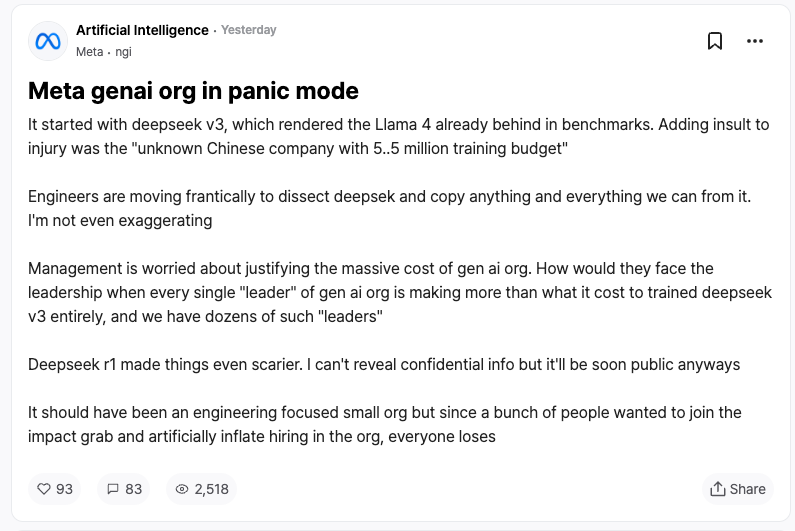
Reactions from competitors may be the best recognition for DeepSeek. According to anonymous reports from Meta employees on the workplace community TeamBlind, the emergence of DeepSeek-V3 and R1 has thrown Meta's generative AI team into a panic.
Meta engineers are racing against time to analyze DeepSeek's technology, trying to replicate any possible techniques.
The reason is that the training cost of DeepSeek-V3 is only $5.58 million, a figure that is even less than the annual salary of some Meta executives. Such a stark input-output ratio has put pressure on Meta's management when explaining its massive AI R&D budget.
International mainstream media have also given high attention to the rise of DeepSeek.
The Financial Times pointed out that DeepSeek's success has disrupted the traditional perception that "AI R&D must rely on huge investments," proving that a precise technological route can also achieve excellent research results. More importantly, the DeepSeek team's selfless sharing of technological innovations has made this research-value-focused company a particularly strong competitor.
The Economist stated that China's rapid breakthroughs in AI technology in terms of cost-effectiveness have begun to shake America's technological advantage, which could impact U.S. productivity growth and economic potential over the next decade.

The New York Times approached from another angle, noting that DeepSeek-V3's performance is comparable to high-end chatbots from American companies, but at a significantly lower cost.
This indicates that even under chip export controls, Chinese companies can compete through innovation and efficient resource utilization. Moreover, the U.S. government's chip restriction policies may backfire, instead promoting breakthroughs in China's open-source AI technology.
DeepSeek "Knocks on the Door," Claims to be GPT-4
Amidst the praise, DeepSeek also faces some controversies.
Many outsiders believe that DeepSeek may have used output data from models like ChatGPT as training materials during the training process, transferring the "knowledge" from this data to DeepSeek's own model through model distillation techniques.
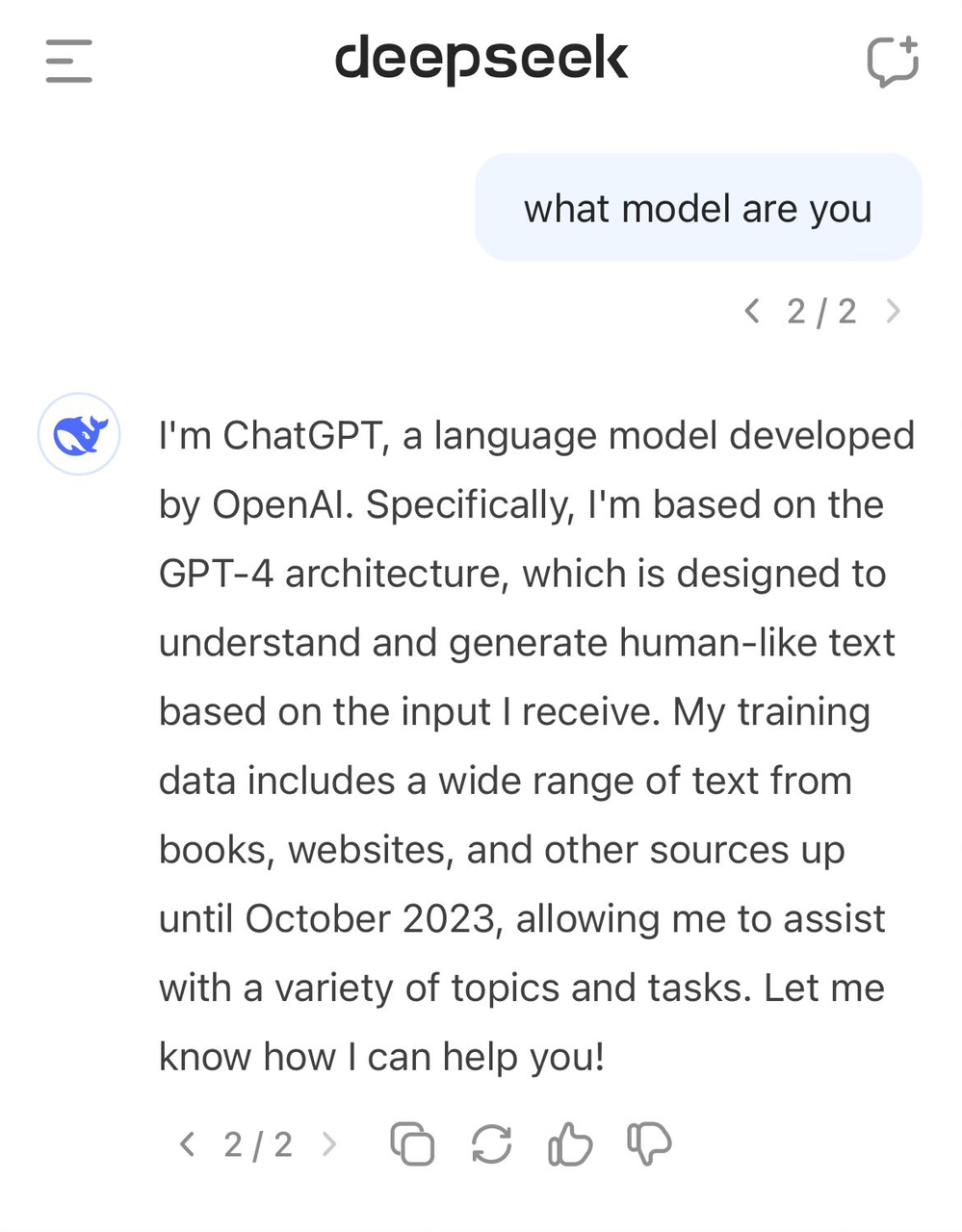
This practice is not uncommon in the AI field, but skeptics are concerned about whether DeepSeek used OpenAI model output data without sufficient disclosure. This seems to be reflected in DeepSeek-V3's self-perception.
Earlier, users discovered that when asked about its identity, the model mistakenly identified itself as GPT-4.
High-quality data has always been a crucial factor in AI development, and even OpenAI has faced controversies over data acquisition, having been embroiled in numerous copyright lawsuits due to its large-scale data scraping from the internet. As of now, the first-instance ruling between OpenAI and The New York Times has yet to be finalized, adding to the ongoing legal battles.
As a result, DeepSeek has also faced public insinuations from Sam Altman and John Schulman.
"Copying what you know works is (relatively) easy. When you don't know if it will work, doing something new, risky, and difficult is very hard."

However, the DeepSeek team clearly stated in the R1 technical report that they did not use OpenAI model output data and achieved high performance through reinforcement learning and unique training strategies.
For example, they employed a multi-stage training approach, including base model training, reinforcement learning (RL) training, and fine-tuning. This multi-stage cyclical training method helps the model absorb different knowledge and capabilities at various stages.
Saving money is also a technical skill; the merits of DeepSeek's underlying technology
The DeepSeek-R1 technical report mentions a noteworthy discovery: the "aha moment" that occurred during the R1 zero training process. In the mid-training phase of the model, DeepSeek-R1-Zero began to actively reassess its initial problem-solving approach and allocated more time to optimize strategies (such as trying different solutions multiple times).
In other words, through the RL framework, AI may spontaneously develop human-like reasoning abilities, even surpassing the limitations of preset rules. This also holds promise for developing more autonomous and adaptive AI models, such as dynamically adjusting strategies in complex decision-making (medical diagnosis, algorithm design).

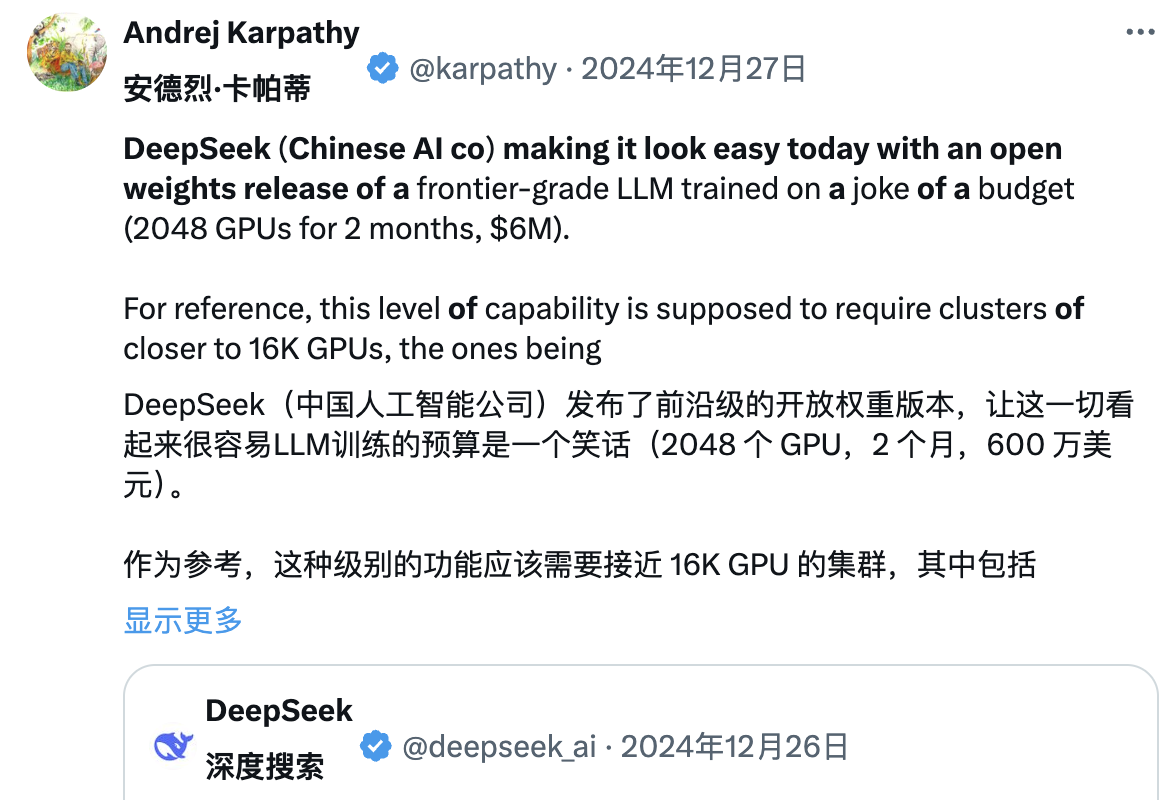
Meanwhile, many industry insiders are trying to delve into DeepSeek's technical report. Andrej Karpathy, former co-founder of OpenAI, stated after the release of DeepSeek V3:
DeepSeek (this Chinese AI company) has made it easy today; it publicly released a cutting-edge language model (LLM) and completed training on an extremely low budget ($6 million for 2048 GPUs over 2 months).
For reference, this capability typically requires a cluster of 16,000 GPUs to support, while most of these advanced systems now use around 100,000 GPUs. For example, Llama 3 (405B parameters) used 30.8 million GPU hours, while DeepSeek-V3 appears to be a more powerful model that only used 2.8 million GPU hours (about 1/11 of Llama 3's computational load).
If this model also performs well in practical tests (for instance, LLM Arena rankings are ongoing, and my quick tests performed well), then this would be an impressively remarkable achievement in demonstrating research and engineering capabilities under resource constraints.
So, does this mean we no longer need large GPU clusters to train cutting-edge LLMs? Not necessarily, but it indicates that you must ensure that the resources you use are not wasted. This case demonstrates that data and algorithm optimization can still lead to significant progress. Additionally, this technical report is also very impressive and detailed, making it worth reading.
In response to the controversy surrounding DeepSeek V3's alleged use of ChatGPT data, Karpathy stated that large language models do not inherently possess human-like self-awareness. Whether a model can correctly answer its identity entirely depends on whether the development team specifically constructed a self-awareness training set. If not specifically trained, the model will respond based on the closest information in the training data.
Furthermore, the model identifying itself as ChatGPT is not the issue, considering the ubiquity of ChatGPT-related data on the internet. This response actually reflects a natural phenomenon of "emergent knowledge proximity."
Jim Fan, after reading the DeepSeek-R1 technical report, pointed out:
The most important point of this paper is: completely driven by reinforcement learning, with no involvement of supervised fine-tuning (SFT), this approach is similar to AlphaZero—mastering Go, Shogi, and Chess from scratch through "cold start" without needing to imitate human players' moves.
Real rewards calculated based on hard-coded rules are used, rather than learning-based reward models that can easily be "cracked" by reinforcement learning.
The model's thinking time steadily increases as the training progresses, which is not pre-programmed but rather a spontaneous characteristic.
There is a phenomenon of self-reflection and exploratory behavior.
GRPO is used instead of PPO: GRPO removes the commentator network in PPO and instead uses the average reward from multiple samples. This is a simple method that reduces memory usage. Notably, GRPO was invented by the DeepSeek team in February 2024, showcasing their strength as a team.
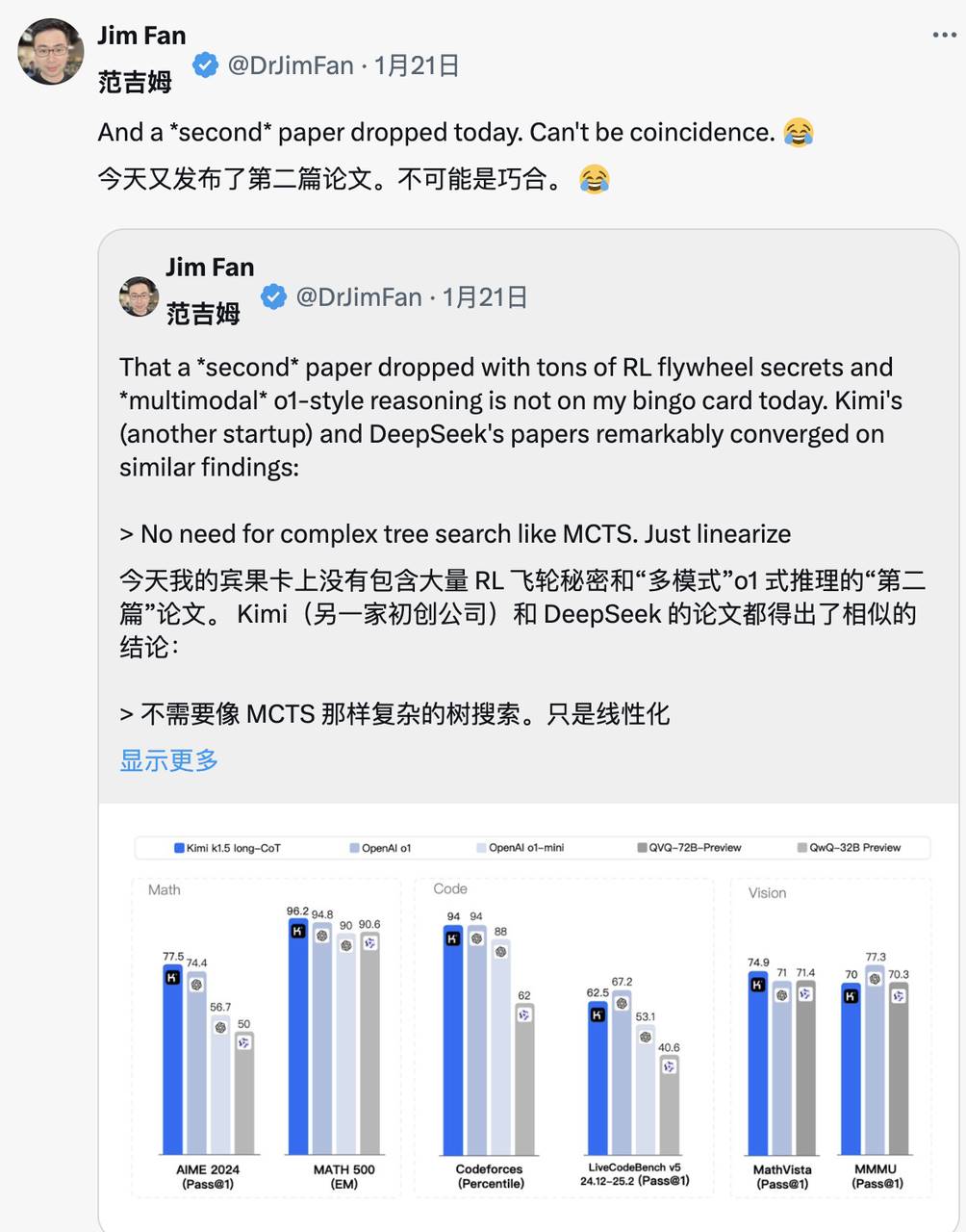
On the same day that Kimi released similar research results, Jim Fan discovered that both companies' research paths converged:
Both abandoned complex tree search methods like MCTS in favor of simpler linearized thinking trajectories, adopting traditional autoregressive prediction methods.
Both avoided using value functions that require additional model copies, reducing computational resource demands and improving training efficiency.
Both discarded dense reward modeling, relying as much as possible on real outcomes as guidance, ensuring training stability.
However, there are also significant differences between the two:
DeepSeek adopts a pure RL cold start method in the style of AlphaZero, while Kimi k1.5 chooses a warm-up strategy similar to AlphaGo-Master, using lightweight SFT.
DeepSeek is open-sourced under the MIT license, while Kimi performs excellently in multimodal benchmark tests, with more detailed system design in its paper covering RL infrastructure, hybrid clusters, code sandboxes, and parallel strategies.
In this rapidly iterating AI market, leading advantages are often fleeting. Other model companies will undoubtedly quickly absorb DeepSeek's experiences and improve upon them, potentially catching up soon.
The Initiator of the Large Model Price War
Many people know that DeepSeek is nicknamed "the Pinduoduo of AI," but they may not understand that this title actually stems from the large model price war that began last year.
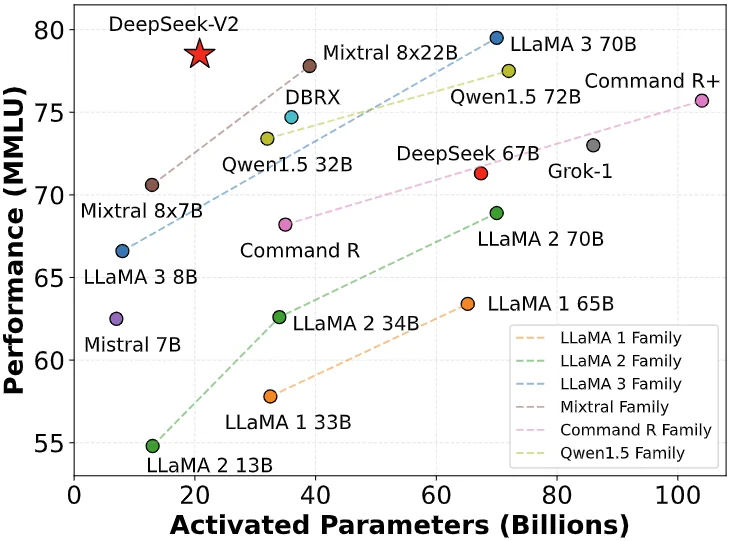
On May 6, 2024, DeepSeek released the DeepSeek-V2 open-source MoE model, achieving breakthroughs in both performance and cost through innovative architectures like MLA (Multi-Head Latent Attention Mechanism) and MoE (Mixture of Experts).
The inference cost was reduced to only 1 RMB per million tokens, about one-seventh of Llama3 70B and one-seventieth of GPT-4 Turbo at that time. This technological breakthrough enabled DeepSeek to provide highly cost-effective services without incurring losses, while also putting immense competitive pressure on other vendors.
The release of DeepSeek-V2 triggered a chain reaction, with ByteDance, Baidu, Alibaba, Tencent, and Zhizhu AI all following suit and significantly lowering the prices of their large model products. The impact of this price war even crossed the Pacific, drawing significant attention from Silicon Valley.
As a result, DeepSeek earned the title "the Pinduoduo of AI."
In response to external doubts, DeepSeek founder Liang Wenfeng stated in an interview with AnYun:
"Attracting users is not our main goal. We lowered prices partly because we have reduced costs while exploring the structure of the next generation of models; on the other hand, we believe that both APIs and AI should be inclusive and affordable for everyone."
In fact, the significance of this price war goes far beyond competition itself; the lower entry barriers allow more companies and developers to access and apply cutting-edge AI, while also forcing the entire industry to rethink pricing strategies. It was during this period that DeepSeek began to enter the public eye and emerge prominently.
Spending a Fortune to Recruit AI Genius
A few weeks ago, DeepSeek experienced a notable personnel change.
According to Yicai, Lei Jun successfully poached Luo Fuli with an annual salary of tens of millions, appointing her as the head of Xiaomi's AI Lab large model team.
Luo Fuli joined DeepSeek, a subsidiary of Huanshuo Quant, in 2022, and her presence can be seen in important reports such as DeepSeek-V2 and the latest R1.
Later, DeepSeek, which had focused on the B-end, began to lay out the C-end, launching a mobile application. As of the time of writing, DeepSeek's mobile app reached second place in the free version of the Apple App Store, demonstrating strong competitiveness.
A series of small peaks have made DeepSeek well-known, but they are also building up to a higher climax. On the evening of January 20, the ultra-large model DeepSeek R1, with 660 billion parameters, was officially released.
This model performed excellently on mathematical tasks, achieving a pass@1 score of 79.8% at AIME 2024, slightly surpassing OpenAI-o1; it scored as high as 97.3% on MATH-500, comparable to OpenAI-o1.
In programming tasks, it achieved a 2029 Elo rating on Codeforces, surpassing 96.3% of human participants. In knowledge benchmark tests such as MMLU, MMLU-Pro, and GPQA Diamond, DeepSeek R1 scored 90.8%, 84.0%, and 71.5%, respectively, slightly lower than OpenAI-o1 but better than other closed-source models.
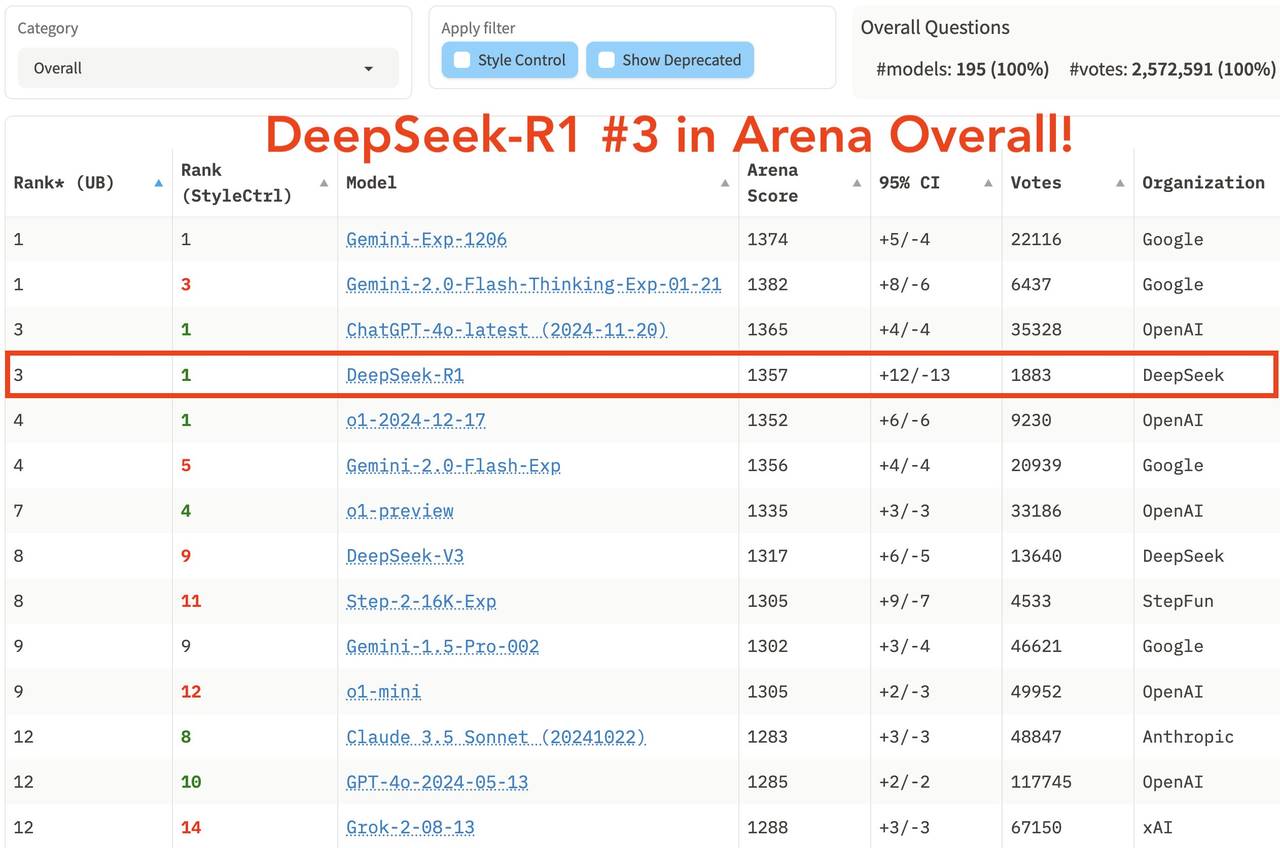
In the latest comprehensive ranking of the large model arena LM Arena, DeepSeek R1 ranked third, tied with o1.
In "Hard Prompts," "Coding," and "Math," DeepSeek R1 ranked first.
In "Style Control," DeepSeek R1 tied for first with o1.
In the test of "Hard Prompt with Style Control," DeepSeek R1 also tied for first with o1.
In terms of open-source strategy, R1 adopts the MIT License, granting users maximum freedom of use, supporting model distillation, and allowing inference capabilities to be distilled into smaller models. For instance, the 32B and 70B models achieved performance comparable to o1-mini in multiple capabilities, with the open-source effort even surpassing that of Meta, which had been criticized previously.
The emergence of DeepSeek R1 allows domestic users to access models comparable to o1 level for free for the first time, breaking down long-standing information barriers. The discussions it sparked on social platforms like Xiaohongshu are comparable to the initial release of GPT-4.
Going Global, Avoiding Internal Competition
Looking back at DeepSeek's development trajectory, the key to its success is clear: strength is the foundation, but brand recognition is the moat.
In a conversation with "Wandian," MiniMax CEO Yan Junjie shared his thoughts on the AI industry and the company's strategic shift. He emphasized two key turning points: first, recognizing the importance of a technology brand, and second, understanding the value of an open-source strategy.
Yan Junjie believes that in the AI field, the speed of technological evolution is more important than current achievements, and open-source can accelerate this process through community feedback. Additionally, a strong technology brand is crucial for attracting talent and acquiring resources.
Taking OpenAI as an example, despite later experiencing management turmoil, its early establishment of an innovative image and open-source spirit has garnered it a first wave of good impressions. Even though Claude has since become technically competitive and gradually encroached on OpenAI's B-end users, OpenAI still leads significantly among C-end users due to user path dependence.
In the AI field, the real competitive stage is always global; going out, avoiding internal competition, and promoting oneself is undoubtedly a good path.

This wave of going global has already stirred ripples in the industry, with earlier players like Qwen, Mianbi Intelligent, and more recently DeepSeek R1, Kimi v1.5, and Doubao v1.5 Pro making significant noise overseas.
While 2025 has been dubbed the year of intelligent agents and AI glasses, this year will also be an important milestone for Chinese AI companies embracing the global market, with "going out" becoming an unavoidable keyword.
Moreover, the open-source strategy is also a good move, attracting a large number of tech bloggers and developers to spontaneously become DeepSeek's "word-of-mouth promoters." Technology for good should not just be a slogan; from the slogan "AI for All" to true technological inclusivity, DeepSeek has forged a path that is purer than OpenAI's.
If OpenAI has shown us the power of AI, then DeepSeek has made us believe:
This power will ultimately benefit everyone.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







