DeepSeek-R1 adopts a pure reinforcement learning approach, successfully achieving performance comparable to top models like GPT-4o and Claude Sonnet 3.5.
Tencent Technology "AI Future Guide" special author: Hao Boyang
Less than a month later, DeepSeek once again shook the global AI community.
In December last year, DeepSeek launched DeepSeek-V3, which caused a huge stir in the global AI field. It achieved performance comparable to top models like GPT-4o and Claude Sonnet 3.5 at an extremely low training cost, shocking the industry. Tencent Technology conducted an in-depth analysis of this model, interpreting its technical background that allows it to achieve both low cost and high efficiency in the simplest and most straightforward way.
Unlike last time, the newly launched model DeepSeek-R1 not only has low costs but also has seen significant technical improvements, and it is an open-source model.
This new model continues to leverage its high cost-performance advantage, achieving GPT-o1 level performance at just one-tenth of the cost.
As a result, many industry insiders have even proclaimed the slogan "DeepSeek will succeed OpenAI," with more people focusing on its breakthroughs in training methods.
For instance, former Meta AI staff member and well-known AI paper Twitter author Elvis emphasized that the paper on DeepSeek-R1 is a gem because it explores various methods to enhance the reasoning capabilities of large language models and discovers clearer emergent properties among them.

Another prominent figure in the AI community, Yuchen Jin, believes that the discovery in the DeepSeek-R1 paper, where the model uses pure RL methods to guide its autonomous learning and reflective reasoning, is of great significance.
Jim Fan, head of the NVIDIA GEAR Lab project, also mentioned on Twitter that DeepSeek-R1 calculates real rewards through hard-coded rules, avoiding the use of any easily hackable RL learning reward models. This has led to the emergence of self-reflective and exploratory behaviors in the model.
Because these extremely important findings are fully open-sourced by DeepSeek-R1, Jim Fan even believes this is something OpenAI should have done.

So the question arises: what do they mean by training models using pure RL methods? How can the model's "Aha moment" prove that AI has emergent capabilities? What we want to know more is what this important innovation of DeepSeek-R1 means for the future development of the AI field.
Using the simplest formula, returning to the purest reinforcement learning
After the launch of o1, reasoning reinforcement became the most focused method in the industry.
Generally speaking, a model will try a fixed training method during the training process to enhance its reasoning capabilities.
However, the DeepSeek team directly experimented with three completely different technical paths during the training of R1: direct reinforcement learning training (R1-Zero), multi-stage progressive training (R1), and model distillation, all of which were successful. The multi-stage progressive training method and model distillation contain many innovative elements that have significant impacts on the industry.
The most exciting path is still direct reinforcement learning. DeepSeek-R1 is the first model to prove the effectiveness of this method.
Let's first understand what the traditional methods for training AI's reasoning capabilities usually are: typically, a large number of chain-of-thought (COT) examples are added during supervised fine-tuning (SFT), using case studies and complex neural network reward models like process reward models (PRM) to teach the model to think using chains of thought.
There may even be the addition of Monte Carlo tree search (MCTS) to allow the model to search for the best possibility among various options.
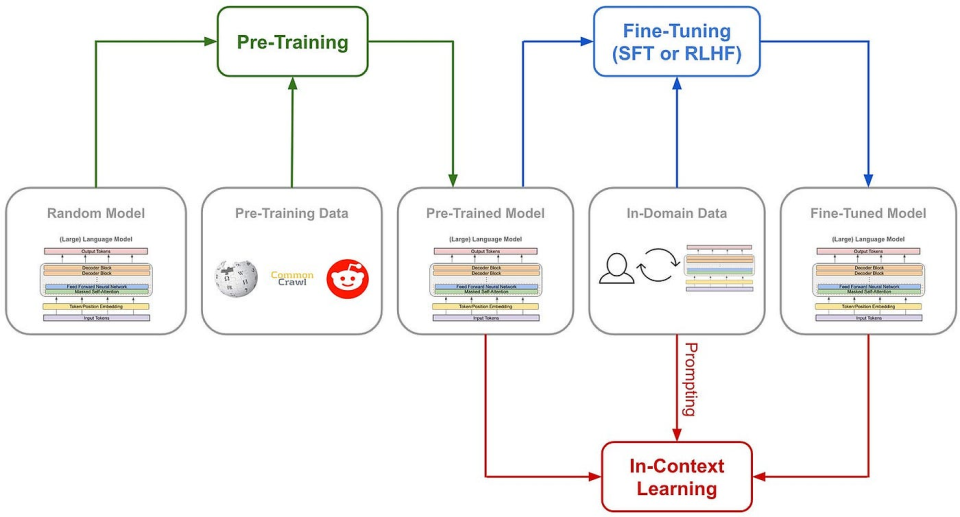
(Traditional model training path)
But DeepSeek-R1 Zero chose an unprecedented path of "pure" reinforcement learning, completely discarding preset chain of thought templates and supervised fine-tuning, relying solely on simple reward and punishment signals to optimize model behavior.
This is akin to allowing a genius child to learn problem-solving purely through continuous attempts and feedback without any examples or guidance.
DeepSeek-R1 Zero has only the simplest reward system to stimulate the AI's reasoning capabilities.
The rules are just two:
Accuracy Reward: The accuracy reward model evaluates whether the response is correct. Points are added for correct answers and deducted for incorrect ones. The evaluation method is also very simple: for example, in mathematical problems with deterministic results, the model needs to provide the final answer in a specified format (e.g., between answer> and /answer>); for programming problems, feedback can be generated using a compiler based on predefined test cases.
Format Reward: The format reward model requires the model to place its thought process between think> and /think> tags. Failure to do so results in point deductions, while doing so earns points.
To accurately observe the model's natural progress during the reinforcement learning (RL) process, DeepSeek even intentionally constrained the system prompts to this structural format to avoid any content-specific biases—such as forcing the model to engage in reflective reasoning or promote specific problem-solving strategies.

(System prompts for R1 Zero)
With such a simple rule, the AI self-samples and compares under the rules of GRPO (Group Relative Policy Optimization), improving itself.
The GRPO model is actually quite simple; it calculates policy gradients through relative comparisons of samples within a group, effectively reducing training instability while improving learning efficiency.
In simple terms, you can think of it as a teacher giving questions, allowing the model to answer multiple times for each question, and then scoring each answer using the above reward and punishment rules, updating the model based on the logic of pursuing high scores and avoiding low scores.
The process roughly goes like this:
Input question → Model generates multiple answers → Rule system scores → GRPO calculates relative advantages → Update model.
This direct training method brings several significant advantages. First is the improvement in training efficiency; the entire process can be completed in a shorter time. Second is the reduction in resource consumption, as the need for SFT and complex reward models is eliminated, significantly decreasing the demand for computational resources.
More importantly, this method truly allows the model to learn to think, and it does so in an "aha" moment.
Learning in "aha" moments with its own language
How do we know that the model has genuinely learned to "think" through this very "primitive" method?
The paper records a striking case: when dealing with a complex mathematical expression problem √a - √(a + x) = x, the model suddenly paused and said, "Wait, wait. Wait. That's an aha moment I can flag here," and then re-examined the entire problem-solving process. This behavior, akin to human insight, was entirely spontaneous and not pre-set.
Such moments of insight often mark the times when the model's reasoning ability leaps forward.
According to DeepSeek's research, the model's progress is not uniformly gradual. During the reinforcement learning process, the response length can suddenly increase significantly, and these "jump points" are often accompanied by qualitative changes in problem-solving strategies. This pattern resembles the sudden insights humans experience after long periods of contemplation, suggesting some deep cognitive breakthroughs.
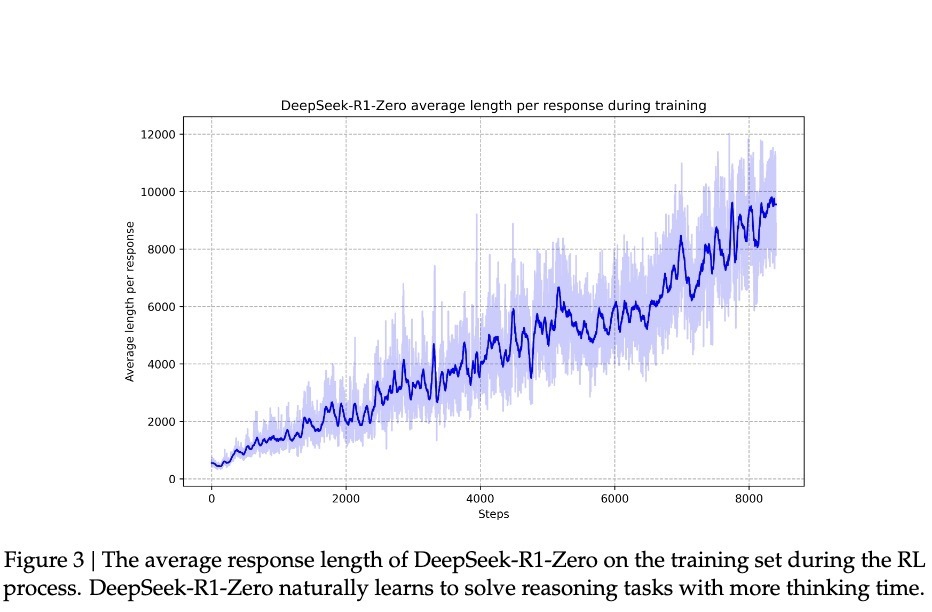
With this ability enhancement accompanied by insights, R1-Zero achieved a remarkable accuracy rate of 71.0% in the AIME competition, which is highly regarded in the mathematics community, up from an initial 15.6% accuracy. When the model attempted the same problem multiple times, the accuracy even reached 86.7%. This is not simply a matter of having seen the problems before—because AIME questions require deep mathematical intuition and creative thinking, rather than mechanical application of formulas. The model must be able to reason to achieve such improvements.
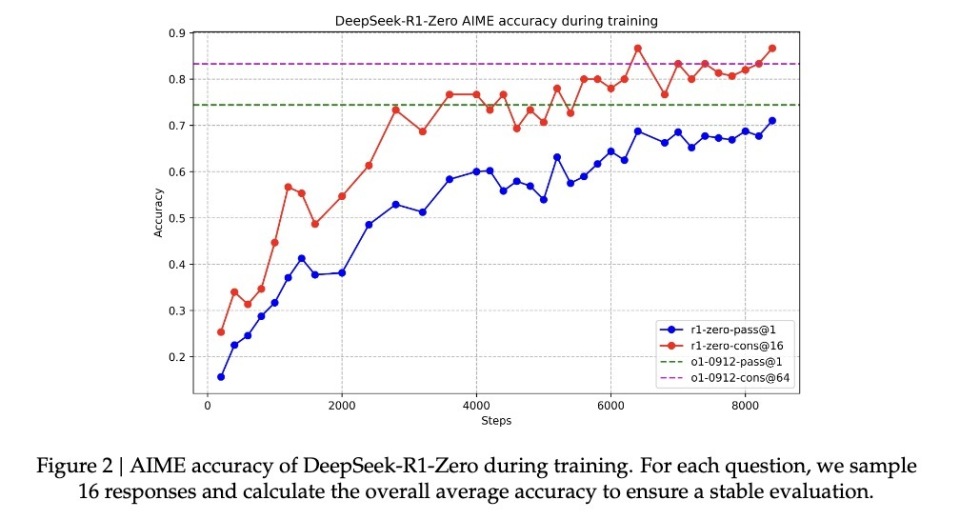
Another core piece of evidence that the model indeed learned reasoning through this method is that the model's response length naturally adjusts according to the complexity of the problem. This adaptive behavior indicates that it is not merely applying templates but truly understanding the difficulty of the problem and accordingly investing more "thinking time." Just as humans naturally adjust their thinking time when faced with simple addition versus complex integration, R1-Zero exhibits similar wisdom.
Perhaps the most convincing evidence is the model's demonstrated transfer learning ability. On the completely different programming competition platform Codeforces, R1-Zero reached a level surpassing over 96.3% of human competitors. This cross-domain performance indicates that the model is not merely memorizing specific domain problem-solving techniques but has mastered some universal reasoning capabilities.
A smart but inarticulate genius
Despite R1-Zero demonstrating astonishing reasoning abilities, researchers quickly discovered a serious problem: its thought processes are often difficult for humans to understand.
The paper candidly points out that this model trained through pure reinforcement learning suffers from "poor readability" and "language mixing."
This phenomenon is quite understandable: R1-Zero optimizes its behavior entirely through reward and punishment signals, without any "standard answers" from human demonstrations as a reference. It's like a genius child creating their own problem-solving method; while it works repeatedly, explaining it to others can be incoherent. It may simultaneously use multiple languages during the problem-solving process or develop some special way of expression, making its reasoning process difficult to trace and understand.
To address this issue, the research team developed the improved version DeepSeek-R1. By introducing more traditional "cold-start data" and a multi-stage training process, R1 not only maintained strong reasoning capabilities but also learned to express its thought processes in a way that is understandable to humans. It's like providing that genius child with a communication coach to teach him how to articulate his thoughts clearly.
Under this training, DeepSeek-R1 demonstrated performance comparable to OpenAI's o1, and even superior in some aspects. In the MATH benchmark test, R1 achieved an accuracy of 77.5%, close to o1's 77.3%; in the more challenging AIME 2024, R1's accuracy reached 71.3%, surpassing o1's 71.0%. In the coding domain, R1 scored 2441 points in the Codeforces evaluation, higher than 96.3% of human participants.
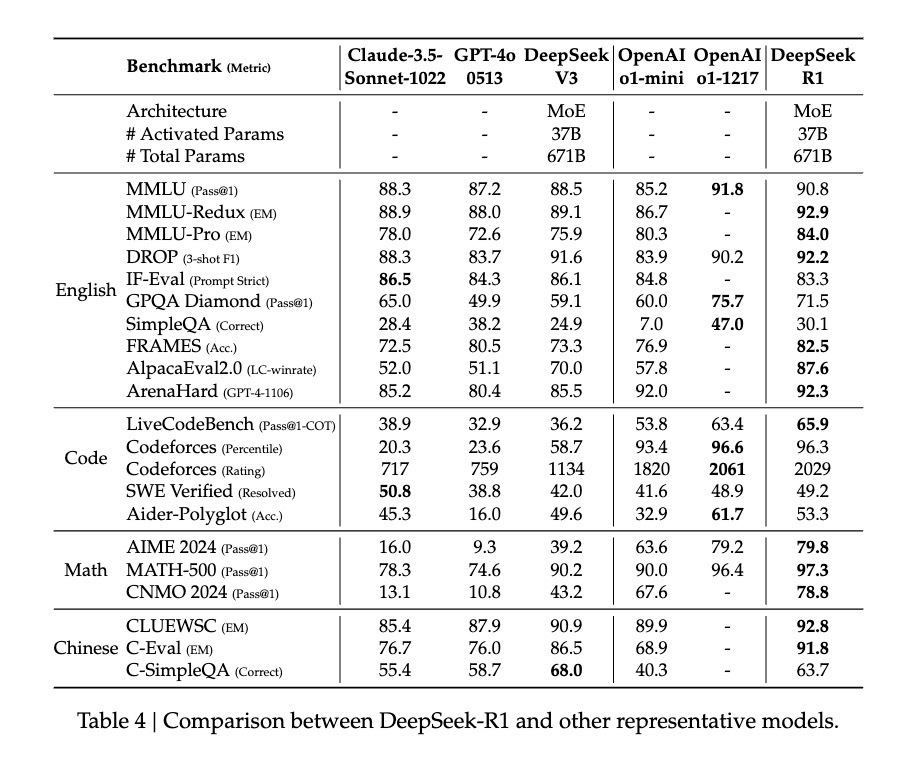
However, the potential of DeepSeek-R1 Zero seems even greater. It achieved an accuracy of 86.7% using a majority voting mechanism in the AIME 2024 test—this score even exceeded OpenAI's o1-0912. This characteristic of "multiple attempts leading to greater accuracy" suggests that R1-Zero may have mastered some foundational reasoning framework, rather than simply memorizing problem-solving patterns. Data from the paper shows that from MATH-500 to AIME, and then to GSM8K, the model exhibited stable cross-domain performance, especially on complex problems requiring creative thinking. This broad-spectrum performance hints that R1-Zero may indeed have developed some foundational reasoning abilities, contrasting sharply with traditional task-specific optimization models.
So, although it may be inarticulate, perhaps DeepSeek-R1 Zero is the true "genius" that understands reasoning.
Pure reinforcement learning may be an unexpected shortcut to AGI
The release of DeepSeek-R1 has shifted the focus of insiders toward pure reinforcement learning methods, as it can be said to have opened a new path for AI evolution.
R1-Zero—this AI model trained entirely through reinforcement learning—exhibits surprisingly general reasoning capabilities. It has not only achieved remarkable results in mathematical competitions.
More importantly, R1-Zero is not merely imitating thought; it has genuinely developed some form of reasoning ability.
This discovery could change our understanding of machine learning: traditional AI training methods may have been repeating a fundamental mistake, as we have been too focused on making AI mimic human thinking. The industry needs to rethink the role of supervised learning in AI development. Through pure reinforcement learning, AI systems seem to be able to develop more innate problem-solving abilities, rather than being confined to pre-set solution frameworks.
Although R1-Zero has significant deficiencies in output readability, this "defect" itself may actually validate the uniqueness of its thought process. Just like a genius child inventing his own problem-solving method but struggling to explain it in conventional language. This suggests to us that true general artificial intelligence may require a cognitive approach that is entirely different from that of humans.
This is true reinforcement learning. As the renowned educator Jean Piaget theorized: true understanding comes from active construction, not passive acceptance.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








