Expectations are high for major model manufacturers to actively respond, proactively optimize product design and privacy policies, and adopt a more open and transparent stance to clearly explain the origins and uses of data to users, allowing them to use large model technology with peace of mind.
Author: Siyuan, Tech New Knowledge

Image source: Generated by Wujie AI
In the AI era, the information users input is no longer just personal privacy; it has become the "stepping stone" for the advancement of large models.
"Help me create a PPT," "Help me design a new spring festival poster," "Help me summarize the document content." Since the rise of large models, using AI tools to improve efficiency has become a daily routine for white-collar workers, and many have even started using AI to order takeout and book hotels.
However, this method of data collection and usage has also brought significant privacy risks. Many users overlook a major issue in the digital age: the lack of transparency in the use of digital technologies and tools. They are unclear about how the data from these AI tools is collected, processed, and stored, and uncertain whether their data is being misused or leaked.
In March of this year, OpenAI acknowledged vulnerabilities in ChatGPT that led to the leakage of some users' historical chat records. This incident raised public concerns about data security and personal privacy protection in large models. In addition to the ChatGPT data leak incident, Meta's AI model has also faced controversy for copyright infringement. In April of this year, organizations of American writers and artists accused Meta's AI model of using their works for training without permission, infringing on their copyrights.
Similarly, similar incidents have occurred domestically. Recently, iQIYI drew attention due to a copyright dispute with MiniMax, one of the "six little tigers" of large models. iQIYI accused Hai Luo AI of using its copyrighted materials to train its model without permission, marking the first case of a domestic video platform suing for infringement against an AI video large model.
These incidents have sparked external concerns about the sources of training data for large models and copyright issues, indicating that the development of AI technology needs to be built on the foundation of user privacy protection.
To understand the current transparency of information disclosure for domestic large models, "Tech New Knowledge" selected seven mainstream large model products on the market: Doubao, Wenxin Yiyan, Kimi, Tencent Yuanbao, Xinghuo Large Model, Tongyi Qianwen, and Kuaishou Keling. Through evaluations of privacy policies, user agreements, and product functionality design experiences, we conducted practical tests and found that many products do not perform well in this regard. We also clearly observed the sensitive relationship between user data and AI products.
01. The Right to Withdraw is Essentially Nonexistent
Firstly, "Tech New Knowledge" noted that on the login pages, all seven domestic large model products follow the "standard" usage agreements and privacy policies of internet apps, with different sections in the privacy policy text explaining how personal information is collected and used.
The statements from these products are also largely consistent: "To optimize and improve service experience, we may analyze user input data, commands issued, AI-generated responses, and user access and usage situations for model training, based on user feedback and issues encountered during use, under the premise of secure encryption and strict de-identification."
In fact, using user data to train products and then iterating better products for users seems like a positive cycle, but the concern for users is whether they have the right to refuse or withdraw the relevant data "fed" to AI training.
After reviewing and testing these seven AI products, "Tech New Knowledge" found that only Doubao, iFlytek, Tongyi Qianwen, and Keling mentioned in their privacy terms the ability to "change the scope of authorization for the product to continue collecting personal information or withdraw authorization."
Among them, Doubao mainly focuses on the withdrawal of authorization for voice information. The policy states, "If you do not wish for the voice information you input or provide to be used for model training and optimization, you can withdraw your authorization by turning off 'Settings' - 'Account Settings' - 'Improve Voice Services';" however, for other information, users need to contact the official through the disclosed contact information to request the withdrawal of data used for model training and optimization.

Image source/ (Doubao)
In practice, turning off the authorization for voice services is not difficult, but for the withdrawal of other information, "Tech New Knowledge" has not received a response after contacting Doubao's official support.
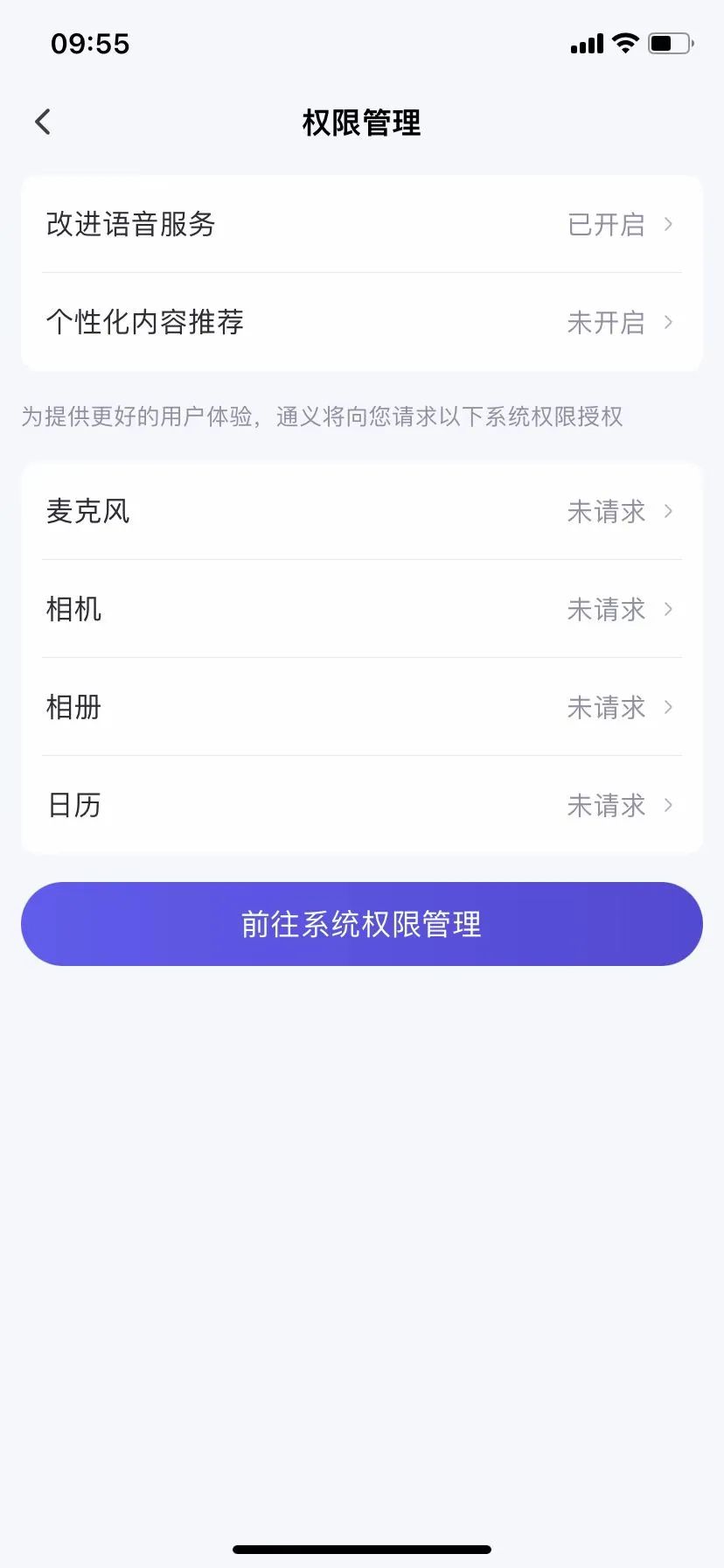
Image source/ (Doubao)
Tongyi Qianwen is similar to Doubao, where individuals can only withdraw authorization for voice services, and for other information, they also need to contact the official through the disclosed contact information to change or withdraw the authorization for collecting and processing personal information.

Image source/ (Tongyi Qianwen)
Keling, as a video and image generation platform, emphasizes that it will not use your facial pixel information for any other purposes or share it with third parties. However, to cancel authorization, users need to send an email to the official for cancellation.

Image source/ (Keling)
Compared to Doubao, Tongyi Qianwen, and Keling, iFlytek Xinghuo has stricter requirements. According to the terms, if users need to change or withdraw the scope of personal information collection, they must do so by canceling their account.

Image source/ (iFlytek Xinghuo)
It is worth mentioning that Tencent Yuanbao does not specify how to change information authorization in its terms, but in the app, we can see the switch for the "Voice Function Improvement Plan."
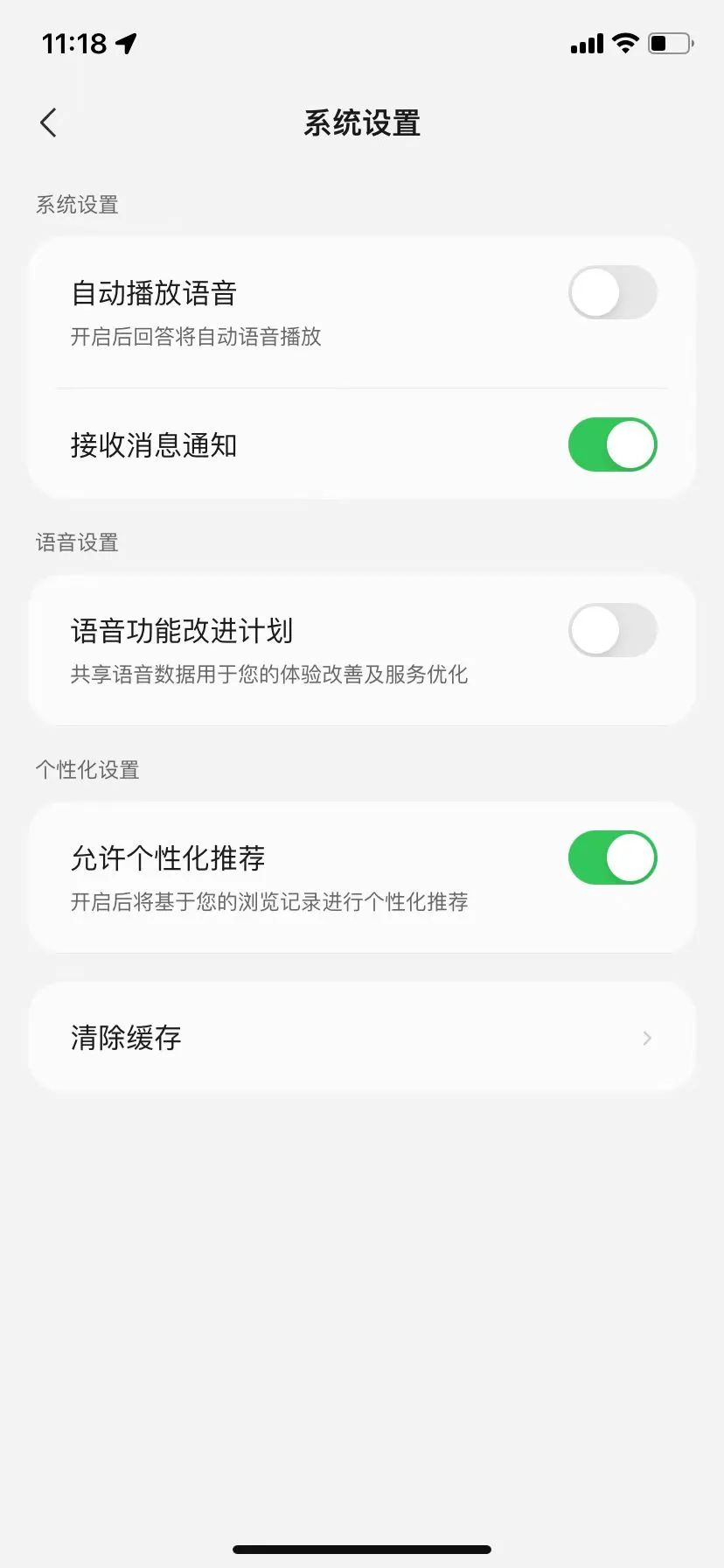
Image source/ (Tencent Yuanbao)
Although Kimi mentions in its privacy terms that users can revoke sharing voiceprint information with third parties and can perform corresponding operations in the app, "Tech New Knowledge" did not find the entry for changes after extensive searching. As for other text-based information, no corresponding terms were found.

Image source/ (Kimi Privacy Terms)
In fact, from several mainstream large model applications, it is not difficult to see that companies pay more attention to user voiceprint management. Doubao, Tongyi Qianwen, and others allow users to cancel authorization through self-service operations, while basic authorizations for specific interactions such as location, camera, and microphone can also be turned off independently. However, the withdrawal of "fed" data is not as smooth across the board.
It is worth noting that overseas large models have similar practices regarding "user data exit from AI training mechanisms." For example, Google's Gemini terms state, "If you do not want us to review future conversations or use related conversations to improve Google's machine learning technology, please turn off Gemini app activity logging."
Additionally, Gemini mentions that when deleting one's application activity records, the system will not delete conversation content that has been reviewed or annotated by human reviewers (as well as related data such as language, device type, location information, or feedback) because this content is stored separately and not associated with the Google account. This content will be retained for a maximum of three years.
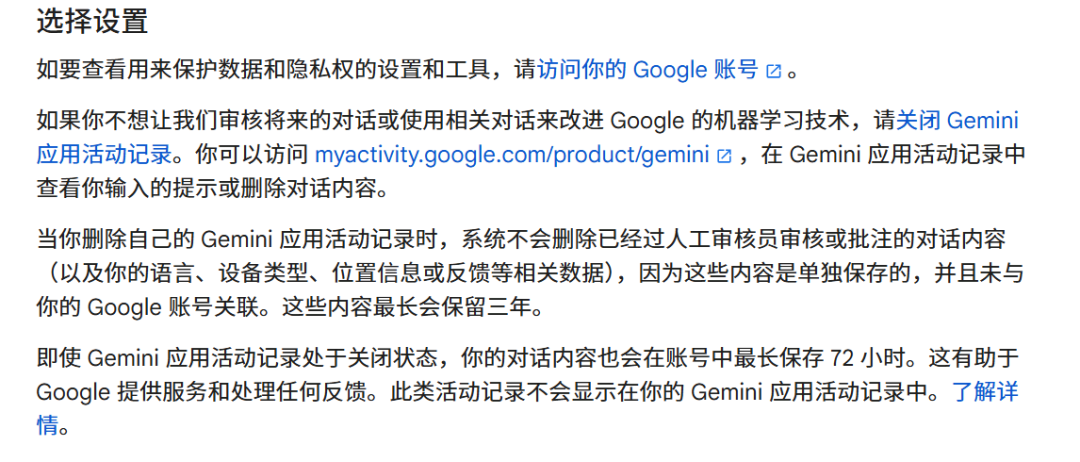
Image source/ (Gemini Terms)
ChatGPT's rules are somewhat ambiguous, stating that users may have the right to limit its processing of personal data, but in practice, it is found that Plus users can actively set to disable data for training, while free users' data is usually collected by default and used for training, and users wishing to opt out need to send a request to the official support.

From these large model products' terms, it is evident that collecting user input information seems to have become a consensus. However, for more private voiceprints, facial recognition, and other biometric information, only a few multimodal platforms show slight performance.
This is not due to a lack of experience, especially for major internet companies. For instance, WeChat's privacy terms detail every scenario, purpose, and scope of data collection, even explicitly promising "not to collect users' chat records." Douyin is similar, where the information users upload on Douyin is almost always detailed in the privacy terms regarding standard usage methods and purposes.

Image source/ (Douyin Privacy Terms)
The strictly regulated data acquisition behavior of the internet social era has now become a norm in the AI era. The information users input has been casually obtained by large model manufacturers under the banner of "training corpus," and user data is no longer regarded as personal privacy that needs to be treated with care, but rather as a "stepping stone" for model advancement.
In addition to user data, the transparency of training corpus is also crucial for large model attempts. Questions such as whether these corpora are reasonable and legal, whether they constitute infringement, and whether there are potential risks for users are all significant. We conducted in-depth exploration and evaluation of these seven large model products, and the results surprised us.
02. The Risks of "Feeding" Training Corpus
The training of large models requires not only computing power but also high-quality corpora. However, these corpora often include a variety of works such as copyrighted texts, images, and videos, and using them without authorization clearly constitutes infringement.
After practical testing, "Tech New Knowledge" found that none of the seven large model products mentioned the specific sources of their training data in their agreements, nor did they disclose copyright data.

The reason why everyone tacitly does not disclose training data is quite simple. On one hand, improper use of data can easily lead to copyright disputes, and whether AI companies are compliant and legal in using copyrighted products as training data currently lacks relevant regulations. On the other hand, it may relate to competition among enterprises; publicly disclosing training data is akin to a food company revealing its raw materials to competitors, who can quickly replicate and enhance their product quality.
It is worth mentioning that most model policy agreements state that the information obtained from user interactions with large models will be used for model and service optimization, related research, brand promotion and publicity, marketing, user research, and more.
Frankly speaking, due to the varying quality of user data, insufficient scene depth, and the existence of marginal effects, it is challenging for user data to enhance model capabilities and may even incur additional data cleaning costs. Nevertheless, the value of user data still exists. However, it is no longer the key to improving model capabilities but rather a new avenue for enterprises to gain commercial benefits. By analyzing user dialogues, companies can gain insights into user behavior, discover transformation scenarios, customize commercial functions, and even share information with advertisers. All of these align with the usage rules of large model products.
However, it is also important to note that data generated during real-time processing will be uploaded to the cloud for processing and will also be stored in the cloud. Although most large models mention in their privacy agreements that they use encryption technologies and anonymization methods that are no less than those of industry peers to protect personal information, there are still concerns about the actual effectiveness of these measures.
For example, if user input is used as a dataset, there may be a risk of information leakage when others later ask the large model related questions. Additionally, if the cloud or product is attacked, it raises the question of whether original information could still be recovered through association or analysis techniques, which poses a hidden danger.
Recently, the European Data Protection Board (EDPB) released data protection guidelines regarding AI models processing personal data. The guidelines clearly state that the anonymity of AI models cannot be established merely by declaration; it must undergo rigorous technical validation and continuous monitoring measures to ensure it. Furthermore, the guidelines emphasize that companies must not only demonstrate the necessity of data processing activities but also show that they have adopted methods that minimally intrude on personal privacy during processing.

Therefore, when large model companies collect data "to enhance model performance," we need to be more vigilant in considering whether this is a necessary condition for model advancement or whether it is a misuse of user data for commercial purposes.
03. The Gray Area of Data Security
In addition to conventional large model applications, the privacy leakage risks brought by agents and edge AI applications are more complex.
Compared to AI tools like chatbots, agents and edge AI require more detailed and valuable personal information during use. Previously, the information obtained by mobile phones mainly included user device and application information, log information, and underlying permission information; in edge AI scenarios and current technologies primarily based on screen reading and recording, in addition to the comprehensive information permissions mentioned above, terminal intelligent agents can often access the recorded files themselves and further analyze them through models to obtain various sensitive information such as identity, location, and payment.
For example, in a previous demonstration by Honor at a press conference regarding food delivery, information such as location, payment, and preferences could be quietly read and recorded by AI applications, increasing the risk of personal privacy leakage.

As analyzed by the "Tencent Research Institute," in the mobile internet ecosystem, apps that directly provide services to consumers are generally regarded as data controllers, bearing corresponding privacy protection and data security responsibilities in service scenarios such as e-commerce, social networking, and transportation. However, when edge AI agents complete specific tasks based on the service capabilities of apps, the boundaries of data security responsibilities between terminal manufacturers and app service providers become blurred.
Manufacturers often use the provision of better services as a justification. When viewed across the entire industry, this is not a "legitimate reason." Apple Intelligence has explicitly stated that its cloud does not store user data and employs various technical means to prevent any organization, including Apple itself, from accessing user data, thereby earning user trust.
Undoubtedly, there are many urgent issues regarding transparency in current mainstream large models. Whether it is the difficulty of user data withdrawal, the opacity of training data sources, or the complex privacy risks posed by agents and edge AI, all of these are continuously eroding the foundational trust users have in large models.

As a key force driving the digitalization process, the enhancement of transparency in large models is urgent. This not only concerns the security of users' personal information and privacy protection but is also a core factor determining whether the entire large model industry can develop healthily and sustainably.
In the future, we hope that major model manufacturers will actively respond, proactively optimize product design and privacy policies, and adopt a more open and transparent stance to clearly explain the origins and uses of data to users, allowing them to use large model technology with peace of mind. At the same time, regulatory authorities should accelerate the improvement of relevant laws and regulations, clarify data usage norms and responsibility boundaries, and create a development environment for the large model industry that is both innovative and secure, enabling large models to truly become powerful tools that benefit humanity.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






