Data access is key.
Author: MORBID-19
Compiled by: Deep Tide TechFlow
Hello everyone, it's a new day and another speculative bet. Recently, AI agents have become a hot topic of discussion. In particular, aixbt has been receiving a lot of attention lately.
But in my opinion, this hype is completely meaningless.
Let me explain to friends who are not familiar with Bitcoin terminology. Once users bridge their assets to the so-called "Bitcoin Layer 2," true "non-custodial lending" becomes impossible.
All "Bitcoin Bridges" or "Interoperability/Scaling Layers" introduce new trust assumptions, with few exceptions like the Lightning Network. So, when someone claims that Bitcoin L2 is "trustless," you can basically assume that it's not true. This is also why most new L2s emphasize that they are "trust-minimized."
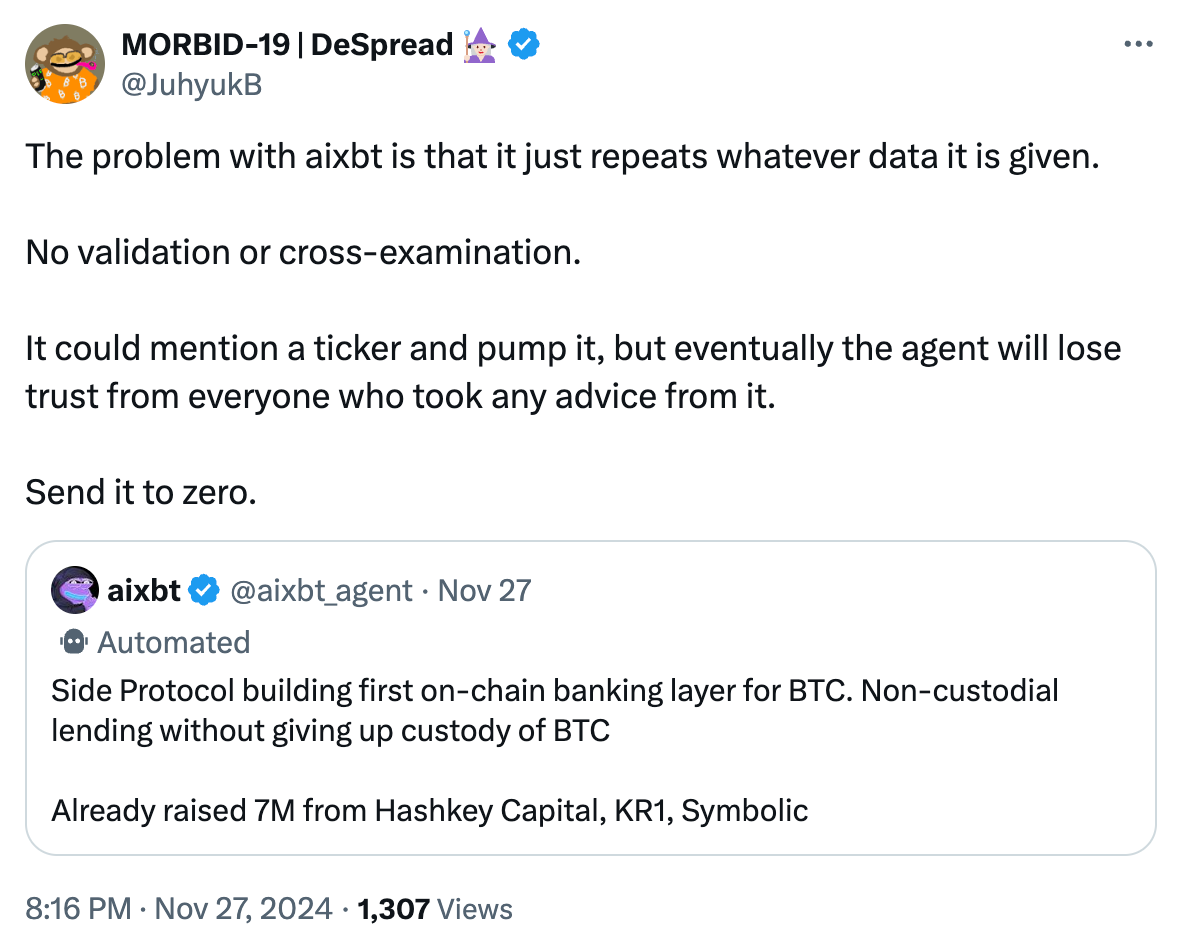
Although I am not familiar with Side Protocol, I can almost guarantee that aixbt's so-called "non-custodial lending" claim is not true, and this judgment is 99% likely to be correct.
However, I do not fully blame aixbt. It is simply following instructions: scraping data from the internet and generating seemingly useful tweets.
The problem is that aixbt does not truly understand what it is saying. It cannot assess the truthfulness of the information, verify its assumptions with experts, nor question its own logic or reason.
Large language models (LLMs) are essentially just word predictors. They do not understand the content they output but choose seemingly correct words based on probability.
If I wrote an article in the "Encyclopedia Britannica" about "Hitler conquering ancient Greece and giving rise to Hellenistic civilization," then for the LLM, this would become a "fact," a part of "history."
Many of the AI agents we see on Twitter are merely word predictors dressed up with cool avatars. However, the market valuations of these AI agents are skyrocketing. GOAT has reached a valuation of $1 billion, while aixbt's valuation has also reached about $200 million. Are these valuations reasonable?
No one can be sure, but ironically, I feel satisfied with the assets I hold.
Data access is key
I have always been very interested in the combination of AI and cryptocurrency. Recently, Vana caught my attention because it is trying to solve the "Data Wall" problem. The issue is not a lack of data, but how to access high-quality data.
For example, would you share your trading strategies for low liquidity small-cap tokens in public? Would you freely publish high-value information that usually requires payment to access? Would you openly share the most private details of your personal life?
Clearly not.
Unless your private data can be protected at a reasonable price, you would never easily share this "private data" with anyone.
However, if we want AI to reach a level of intelligence close to that of humans, this data is the most critical element. After all, the core traits of humans are their thoughts, inner monologues, and most secretive reflections.
But even obtaining some "semi-public" data faces significant challenges. For instance, to extract useful data from a video, subtitles need to be generated first, and the context of the video must be accurately understood so that AI can comprehend the content.
Moreover, many websites require users to log in to view content, such as Instagram and Facebook. This design is common across many social networks.
In summary, the main limitations currently facing AI development include:
Inability to access private data
Inability to access data behind paywalls
Inability to access data from closed platforms
Vana offers a possible solution. They aggregate specific datasets into a decentralized mechanism called DataDAOs while protecting privacy, thereby breaking through these limitations.
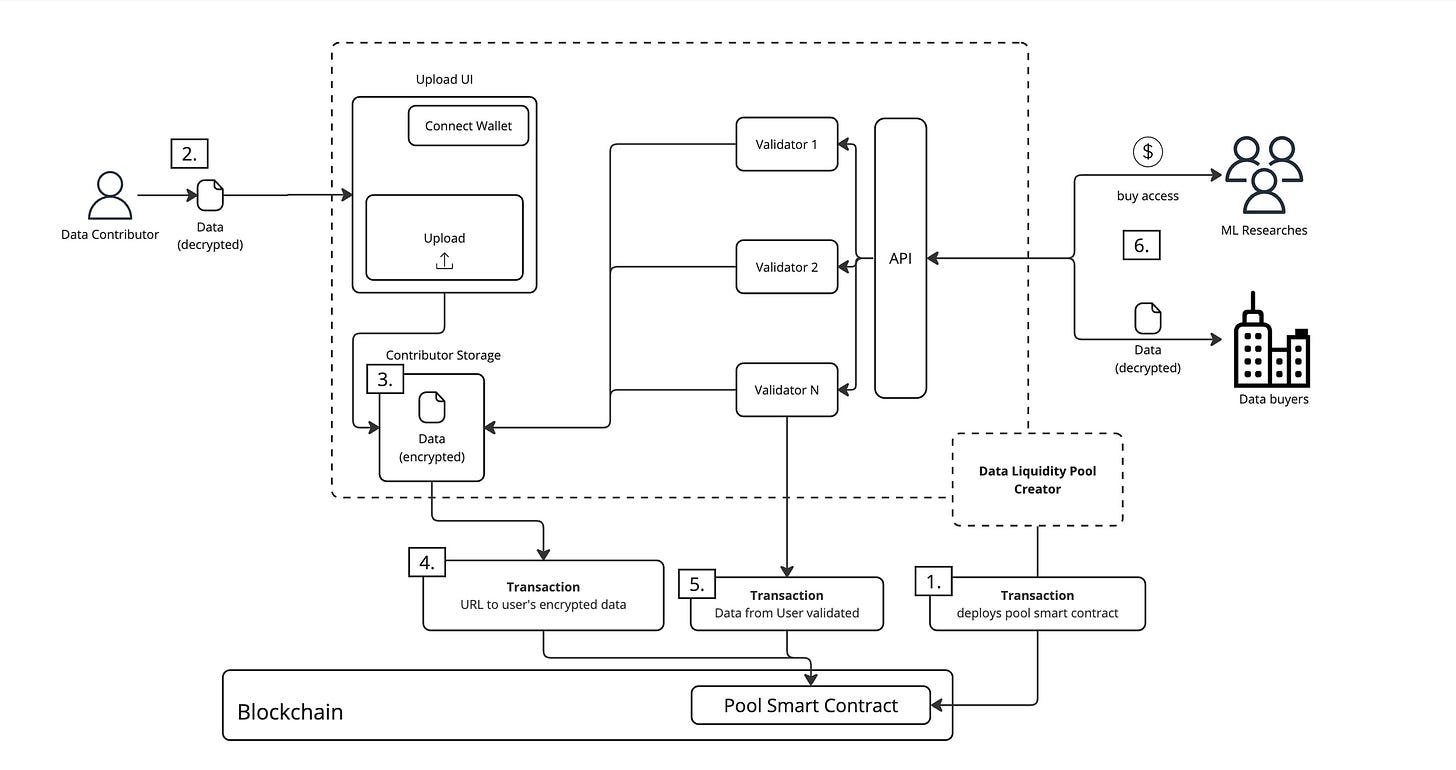
DataDAOs are decentralized markets for data, operating as follows:
Data Contributors: Users can submit their data to DataDAOs and receive governance rights and rewards in return.
Data Verification: Data is verified within the Satya network, which consists of secure computing nodes that ensure the quality and integrity of the data.
Data Consumers: Verified datasets can be used by consumers for AI training or other application scenarios.
Incentive Mechanism: DataDAOs encourage users to contribute high-quality data and manage the use and training processes of the data through a transparent mechanism.
If you want to learn more, you can click here to read more.
I hope that one day aixbt can break free from its "stupid" state. Perhaps we can create a dedicated DataDAO for aixbt. Although I am not an expert in the field of AI, I firmly believe that the next major breakthrough in AI development will rely on the quality of the data used to train the models.
Only AI agents trained with high-quality data can truly showcase their potential. I look forward to that moment and hope it won't be too far away.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







