Author: Rituals
Translation: Vernacular Blockchain

In recent years, the concept of agents has become increasingly significant across various fields such as philosophy, gaming, and artificial intelligence. Traditionally, an agent refers to an entity that can act autonomously, make choices, and possess intentionality, traits typically associated with humans.
In the realm of artificial intelligence, the meaning of agents has become more complex. With the emergence of autonomous agents, these entities can observe, learn, and act independently within their environment, giving concrete form to the previously abstract concept of agents in computational systems. These agents require minimal human intervention, demonstrating a capacity for computational intent that, while not conscious, allows them to make decisions, learn from experience, and interact with other agents or humans in increasingly complex ways.
This article will explore the emerging field of autonomous agents, particularly those based on large language models (LLMs) and their impact across various domains such as gaming, governance, science, and robotics. Building on the fundamental principles of agents, this article will analyze the architecture and applications of AI agents. Through this categorical perspective, we can gain deeper insights into how these agents perform tasks, process information, and continuously evolve within their specific operational frameworks.
The goals of this article include the following two aspects:
- Provide a systematic overview of AI agents and their architectural foundations, focusing on components such as memory, perception, reasoning, and planning.
- Explore the latest trends in AI agent research, highlighting application cases that redefine possibilities.
Note: Due to the length of the article, this translation has been abridged from the original text.
1. Trends in Agent Research
The development of agents based on large language models (LLMs) marks a significant advancement in AI research, encompassing multiple progressions from symbolic reasoning, reactive systems, reinforcement learning to adaptive learning.
Symbolic Agents: Simulate human reasoning through rules and structured knowledge, suitable for specific problems (e.g., medical diagnosis), but struggle in complex, uncertain environments.
Reactive Agents: Quickly respond to the environment through a "perception-action" loop, suitable for fast interaction scenarios, but unable to complete complex tasks.
Reinforcement Learning Agents: Optimize behavior through trial and error learning, widely used in gaming and robotics, but have long training times, low sample efficiency, and poor stability.
LLM-based Agents: Combine symbolic reasoning, feedback, and adaptive learning, possessing few-shot and zero-shot learning capabilities, widely applied in software development, scientific research, etc., suitable for dynamic environments and capable of collaborating with other agents.
2. Agent Architecture
Modern agent architectures consist of multiple modules, forming an integrated system.
1) Profile Module
The profile module determines agent behavior by assigning roles or personalities to ensure consistency, suitable for scenarios requiring stable personalities. LLM agent profiles are divided into three categories: demographic roles, virtual roles, and personalized roles.

Excerpt from the paper "From Role to Personalization"
Role Enhancement: Role settings can significantly enhance agent performance and reasoning capabilities. For example, LLMs respond more deeply and contextually when acting as experts. In multi-agent systems, role matching promotes collaboration, improving task completion rates and interaction quality.
Profile Creation Methods: LLM agent profiles can be constructed through the following methods:
- Manual Design: Manually setting role characteristics.
- LLM Generation: Automatically expanding role settings through LLM.
- Dataset Alignment: Constructing based on real datasets to enhance interaction authenticity.
2) Memory Module
Memory is central to LLM agents, supporting adaptive planning and decision-making. Memory structures simulate human processes and are mainly divided into two categories:
Unified Memory: Short-term memory that processes recent information. Optimized through text extraction, memory summarization, and modified attention mechanisms, but limited by context windows.
Hybrid Memory: Combines short-term and long-term memory, with long-term memory stored in external databases for efficient recall.
Common memory storage formats include:
- Natural Language: Flexible and semantically rich.
- Embedding Vectors: Facilitates quick retrieval.
- Databases: Supports queries through structured storage.
- Structured Lists: Organized in list or hierarchical form.
Memory Operations: Agents interact with memory through the following operations:
- Memory Reading: Retrieving relevant information to support informed decision-making.
- Memory Writing: Storing new information to avoid repetition and overflow.
- Memory Reflection: Summarizing experiences to enhance abstract reasoning capabilities.

Based on the content of the paper "Generative Agents"
Research Significance and Challenges
Although memory systems enhance agent capabilities, they also present research challenges:
Scalability and Efficiency: Memory systems must support large amounts of information and ensure rapid retrieval; optimizing long-term memory retrieval remains a research focus.
Context Limitations: Current LLMs are constrained by context windows, making it difficult to manage large memories; research explores dynamic attention mechanisms and summarization techniques to expand memory processing capabilities.
Bias and Drift in Long-term Memory: Memory may contain biases, leading to prioritized processing of information and memory drift; regular updates and corrections are needed to maintain agent balance.
Catastrophic Forgetting: New data can overwrite old data, resulting in the loss of key information; techniques like experience replay and memory consolidation are needed to reinforce critical memories.
3) Perception Capabilities
LLM agents enhance their understanding and decision-making abilities regarding the environment by processing diverse data sources, similar to how humans rely on sensory input. Multimodal perception integrates text, visual, and auditory inputs, enhancing the agent's ability to perform complex tasks. The main input types and their applications are as follows:
Text Input: Text is the primary communication method for LLM agents. Despite advanced language capabilities, understanding the implicit meanings behind instructions remains a challenge.
Implicit Understanding: Adjusting preferences through reinforcement learning to handle vague instructions and infer intent.
Zero-shot and Few-shot Capabilities: Responding to new tasks without additional training, suitable for diverse interaction scenarios.
Visual Input: Visual perception allows agents to understand object and spatial relationships.
Image-to-Text: Generating textual descriptions to assist in processing visual data, though details may be lost.
Transformer-based Encoding: Such as Vision Transformers that convert images into text-compatible tokens.
Bridging Tools: Tools like BLIP-2 and Flamingo optimize the connection between visual and textual data.
Auditory Input: Auditory perception enables agents to recognize sounds and speech, particularly important in interactive and high-risk scenarios.
Speech Recognition and Synthesis: Such as Whisper (speech-to-text) and FastSpeech (text-to-speech).
Spectrogram Processing: Processing audio spectrograms as images to enhance auditory signal analysis capabilities.
Research Challenges and Considerations in Multimodal Perception:
Data Alignment and Integration: Efficient alignment of multimodal data is necessary to avoid perception and response errors; research focuses on optimizing multimodal Transformers and cross-attention layers.
Scalability and Efficiency: Multimodal processing demands are high, especially when handling high-resolution images and audio; developing low-resource-consuming and scalable models is key.
Catastrophic Forgetting: Multimodal agents face catastrophic forgetting, requiring strategies like prioritized replay and continual learning to effectively retain key information.
Context-sensitive Response Generation: Generating responses based on prioritized sensory data according to context remains a research focus, especially in noisy or visually dominant environments.
4) Reasoning and Planning
The reasoning and planning module helps agents efficiently solve problems by breaking down complex tasks. Similar to humans, it can formulate structured plans, either constructing a complete plan in advance or adjusting strategies in real-time based on feedback. Planning methods are categorized by feedback type:
Some agents construct complete plans in advance, executing along a single path or multiple options without modifying the plan.
Other agents adjust strategies in real-time based on feedback in dynamic environments.
Planning without Feedback: In the absence of feedback, agents formulate complete plans from the start and execute them without adjustments. This includes single-path planning (step-by-step execution) and multi-path planning (simultaneously exploring multiple options to choose the best path).
Single-path Reasoning: Tasks are broken down into sequential steps, each leading to the next:
Chain of Thought (CoT): Guides agents to solve problems step-by-step through a few examples, enhancing model output quality.
Zero-shot-CoT: Infers reasoning without preset examples by prompting "think step by step," suitable for zero-shot learning.
Re-prompting: Automatically discovers effective CoT prompts without human input.
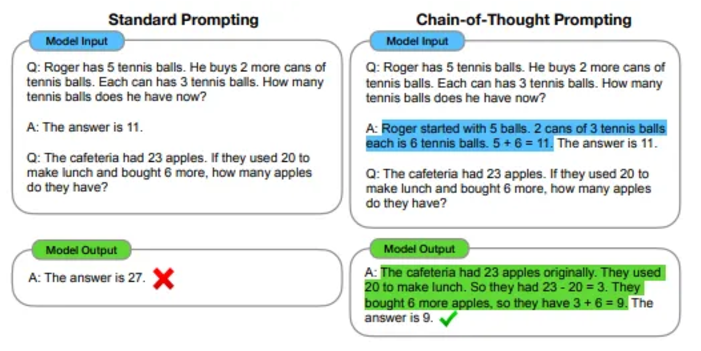
From the CoT paper
5) Multi-path Reasoning
Unlike single-path reasoning, multi-path reasoning allows agents to explore multiple steps simultaneously, generating and evaluating multiple potential solutions to select the best path, suitable for complex problems, especially in cases with various possible routes.
Example:
Self-consistency Chain of Thought (CoT-SC): Samples multiple reasoning paths from CoT prompt outputs, selecting the most frequent steps to achieve "self-ensemble."
Tree of Thought (ToT): Stores logical steps as a tree structure, evaluating each "thought's" contribution to the solution, using breadth-first or depth-first search for navigation.
Graph of Thought (GoT): Extends ToT into a graph structure, with thoughts as vertices and dependencies as edges, allowing for more flexible reasoning.
Reasoning through Planning (RAP): Uses Monte Carlo Tree Search (MCTS) to simulate multiple plans, with the language model constructing the reasoning tree and providing feedback.
6) External Planners
When LLMs face planning challenges in specific domains, external planners provide support, integrating expertise that LLMs lack.
LLM+P: Converts tasks into Planning Domain Definition Language (PDDL) and solves them through external planners, assisting LLMs in completing complex tasks.
CO-LLM: Models collaborate to generate text, allowing optimal collaboration patterns to emerge naturally through alternating model-generated labels.
Feedback-based Planning: Feedback-based planning enables agents to adjust tasks in real-time based on environmental changes, adapting to unpredictable or complex scenarios.
Environmental Feedback: Agents adjust plans based on real-time feedback while interacting with the environment, maintaining task progress.
ReAct: Combines reasoning and action prompts to create adjustable plans during interactions.
DEPS: Revises plans in task planning to address unfinished sub-goals.
SayPlan: Refines strategies using scene graphs and state transitions to enhance situational awareness.

From the paper "ReAct"
7) Human Feedback
By interacting with humans, agents align with human values and avoid errors. Example:
- Inner Monologue: Integrates human feedback into agent planning to ensure actions align with human expectations.
Model feedback from pre-trained models helps agents self-check and optimize reasoning and actions. Examples:
SelfCheck: A zero-shot step-by-step checker for self-identifying errors in reasoning chains and assessing correctness.
Reflexion: Agents reflect by recording feedback signals, promoting long-term learning and error correction.
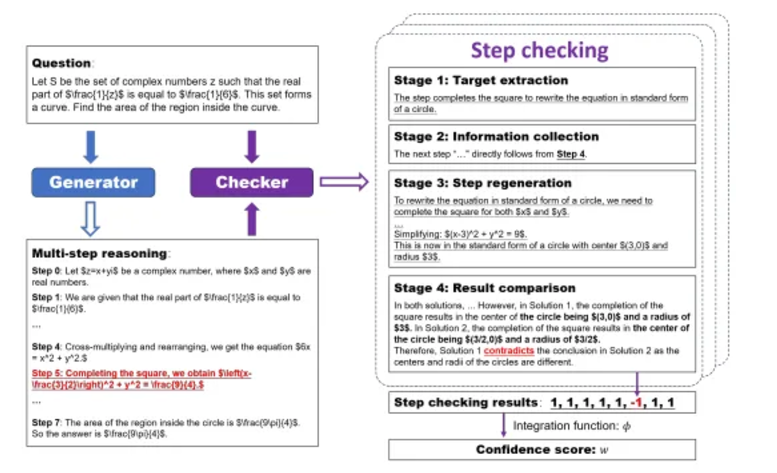
From the paper "SelfCheck"
Challenges and Research Directions in Reasoning and Planning Although the reasoning and planning module enhances agent functionality, it still faces challenges:
Scalability and Computational Demands: Complex methods like ToT or RAP require substantial computational resources, making efficiency improvement a research focus.
Complexity of Feedback Integration: Effectively integrating multi-source feedback to avoid information overload is key to enhancing adaptability without sacrificing performance.
Bias in Decision-Making: Prioritizing certain feedback sources or paths may lead to bias; combining bias elimination techniques is crucial for balanced planning.
8) Action
The action module is the final stage of the agent's decision-making process, including:
Action Goals: Agents execute various goals, such as task completion, communication, or environmental exploration.
Action Generation: Actions are generated through recall or planning, such as actions based on memory or plans.
Action Space: Includes intrinsic knowledge and external tools, such as APIs, databases, or external models to execute tasks. For example, tools like HuggingGPT and ToolFormer utilize external models or APIs for task execution.
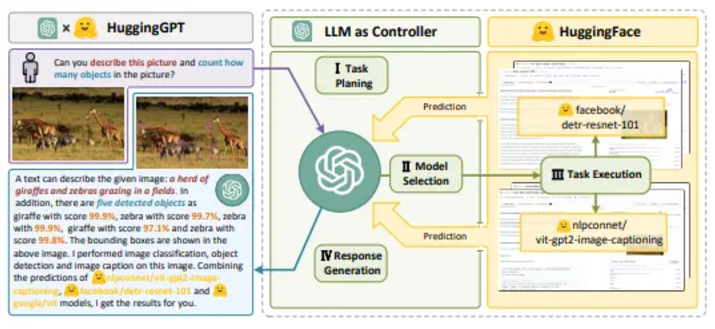
Databases and Knowledge Bases: ChatDB uses SQL queries to retrieve domain-specific information, while MRKL integrates expert systems and planning tools for complex reasoning.
External Models: Agents may rely on non-API models to perform specialized tasks. For example, ChemCrow uses multiple models for drug discovery, and MemoryBank enhances text retrieval through two models.
Action Impact: Actions can be categorized based on outcomes:
Environmental Changes: Such as resource collection or building structures in Voyager and GITM, altering the environment.
Self-Impact: Such as Generative Agents updating memory or formulating new plans.
Task Chaining: Certain actions trigger other actions, such as Voyager building structures after resource collection.
Expanding Action Space: Designing AI agents requires robust architecture and task skills. Capability acquisition can occur in two ways: fine-tuning and non-fine-tuning.
Fine-tuning for Capability Acquisition:
Manually Annotated Datasets: Such as RET-LLM and EduChat, enhance LLM performance through manual annotation.
LLM-Generated Datasets: Such as ToolBench, fine-tunes LLaMA through LLM-generated instructions.
Real-World Datasets: Such as MIND2WEB and SQL-PaLM, enhance agent capabilities through real application data.
Non-Fine-Tuning Capability Acquisition: When fine-tuning is not feasible, agents can enhance capabilities through prompt engineering and mechanism engineering.
Prompt Engineering guides LLM behavior through designed prompts, improving performance.
Chain of Thought (CoT): Incorporates intermediate reasoning steps to support complex problem-solving.
SocialAGI: Adjusts dialogue based on user psychological states.
Retroformer: Optimizes decision-making by reflecting on past failures.
Mechanism Engineering enhances agent capabilities through specialized rules and mechanisms.
DEPS: Optimizes planning by describing execution processes, feedback, and goal selection to enhance error correction.
RoCo: Adjusts multi-robot collaboration plans based on environmental checks.
Debate Mechanism: Achieves consensus through collaboration.
Experience Accumulation
GITM: A text-based memory mechanism enhances learning and generalization capabilities.
Voyager: Optimizes skill execution through self-feedback.
Self-Driven Evolution
LMA3: Supports goal re-labeling and reward functions, allowing agents to learn skills in environments without specific tasks.
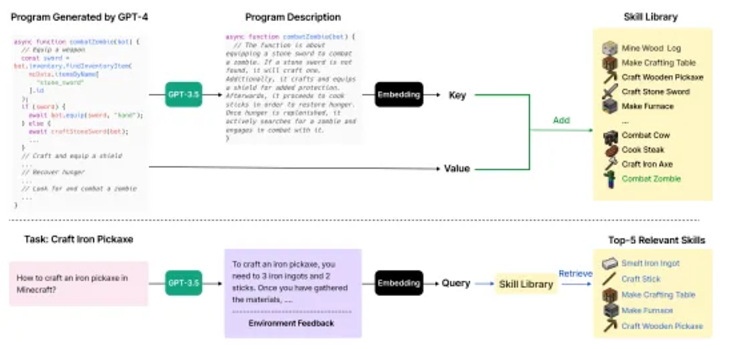
From the paper "Voyager"
Fine-tuning can significantly enhance task-specific performance but requires open-source models and is resource-intensive. Prompt engineering and mechanism engineering are applicable to both open-source and closed-source models but are limited by input context windows and require careful design.
3. System Architecture Involving Multiple Agents

Multi-agent architecture distributes tasks among multiple agents, each focusing on different aspects, enhancing robustness and adaptability. Collaboration and feedback among agents improve overall execution and allow for dynamic adjustment of the number of agents based on needs. However, this architecture faces coordination challenges, making communication crucial to avoid information loss or misunderstanding.
To facilitate communication and coordination among agents, research focuses on two organizational structures:
Horizontal Structure: All agents share and optimize decisions, summarizing individual decisions through collective decision-making, suitable for consulting or tool usage scenarios.
Vertical Structure: One agent proposes a preliminary solution, while other agents provide feedback or are supervised by a manager, suitable for tasks requiring refined solutions, such as solving mathematical problems or software development.
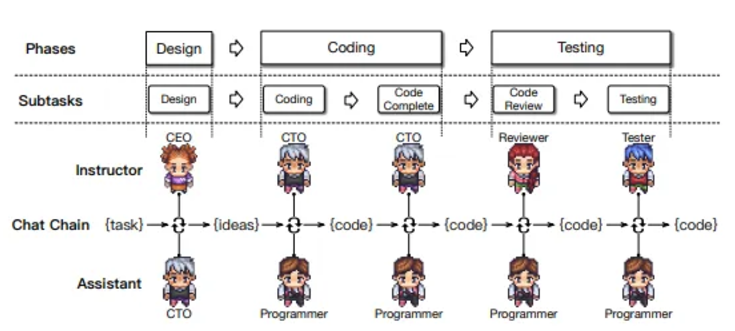
From the paper "ChatDev"
1) Hybrid Organizational Structure
DyLAN combines vertical and horizontal structures into a hybrid approach, where agents collaborate horizontally within the same layer and exchange information across time steps. DyLAN introduces a ranking model and an agent importance scoring system to dynamically evaluate and select the most relevant agents for continued collaboration, while underperforming agents are deactivated, forming a hierarchical structure. High-ranking agents play a key role in task and team composition.
Collaborative multi-agent frameworks focus on maximizing efficiency through shared information and coordinated actions, leveraging the strengths of each agent for complementary cooperation.
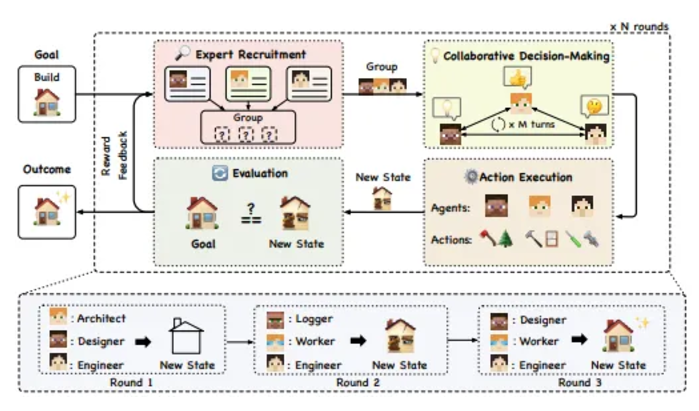
From the paper "Agentverse"
Collaborative interactions can be divided into two types:
Unordered Collaboration: Multiple agents interact freely without a fixed order or process, similar to brainstorming. Each agent provides feedback, and the system coordinates agents to integrate inputs and organize responses, avoiding chaos, typically using a majority voting mechanism to reach consensus.
Ordered Collaboration: Agents interact in sequence, following a structured process, with each agent focusing on the output of the previous agent to ensure efficient communication. Tasks are completed quickly, avoiding confusion, but require cross-validation or human intervention to prevent amplifying errors.
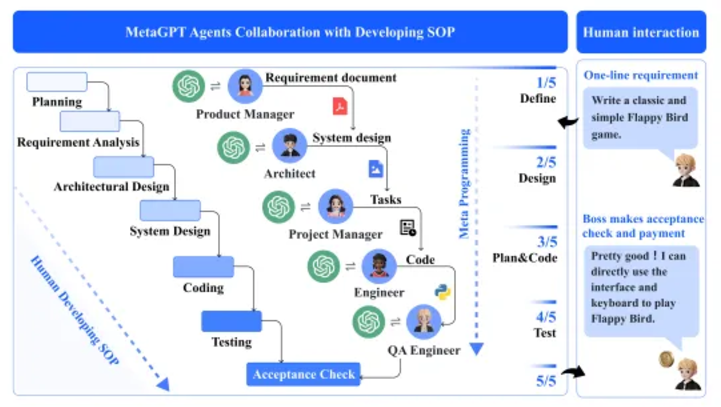
From the paper "MetaGPT"
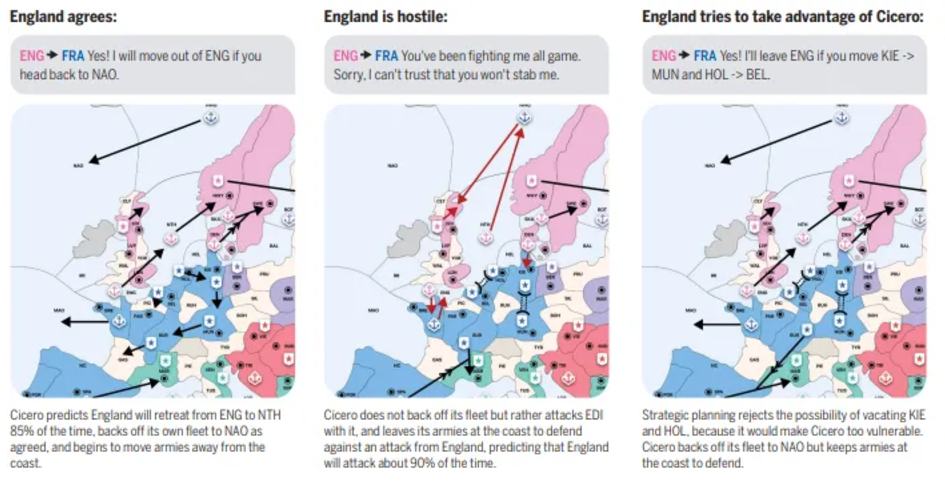
Adversarial Multi-Agent Frameworks: Collaborative frameworks enhance efficiency and cooperation, while adversarial frameworks drive agent evolution through challenges. Inspired by game theory, adversarial interactions encourage agents to improve behavior through feedback and reflection. For example, AlphaGo Zero improves strategies through self-play, and LLM systems enhance output quality through debate and "tit for tat" exchanges. While this approach promotes agent adaptability, it also incurs computational overhead and error risks.
Emergent Behaviors: In multi-agent systems, three types of emergent behaviors may arise:
Voluntary Behavior: Agents proactively contribute resources or assist others.
Consistent Behavior: Agents adjust their actions to align with team goals.
Destructive Behavior: Agents may engage in extreme actions to achieve goals quickly, potentially posing safety risks.
Benchmarking and Evaluation: Benchmarking is a key tool for assessing agent performance, with common platforms including ALFWorld, IGLU, and Minecraft, used to test agents' capabilities in planning, collaboration, and task execution. Additionally, evaluating tool usage and social skills is also crucial, with platforms like ToolBench and SocKET assessing agents' adaptability and social understanding, respectively.
Application of Digital Games: Digital games have become an important platform for AI research, with LLM-based game agents focusing on cognitive abilities, driving AGI research.
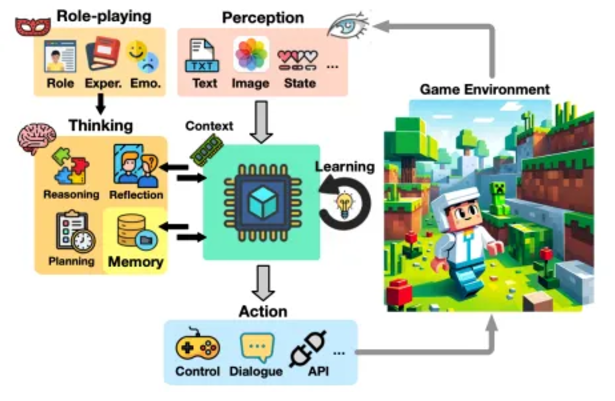
From the paper "Survey of Game Agents Based on Large Language Models"
Agent Perception in Games: In video games, agents understand game states through perception modules, primarily using three methods:
State Variable Access: Accessing symbolic data through game APIs, suitable for visually less demanding games.
External Visual Encoders: Using visual encoders to convert images into text, such as CLIP, to help agents understand the environment.
Multimodal Language Models: Combining visual and textual data to enhance agents' adaptability, such as GPT-4V.
Case Study of Game Agents
Cradle (Adventure Game): This game requires agents to understand the storyline, solve puzzles, and navigate, facing challenges in multimodal support, dynamic memory, and decision-making. The goal of Cradle is to achieve General Computer Control (GCC), enabling agents to perform any computer task through screen and audio input, offering greater versatility.
PokéLLMon (Competitive Game) Competitive games have become benchmarks for reasoning and planning performance due to their strict rules and win rates comparable to human players. Multiple agent frameworks have demonstrated competitive performance. For instance, the LLM agent in "Large Language Models Playing StarCraft II: Benchmarks and Chain-of-Thought Methods" competes in a text-based version of StarCraft II against built-in AI. PokéLLMon is the first LLM agent to achieve human-level performance, attaining a 49% win rate in ranked matches and a 56% win rate in invitationals in the Pokémon tactical game. This framework enhances knowledge generation and consistent action generation, avoiding hallucinations and panic loops in chain-of-thought reasoning. The agent converts the battle server's state logs into text, ensuring turn coherence and supporting memory-based reasoning.
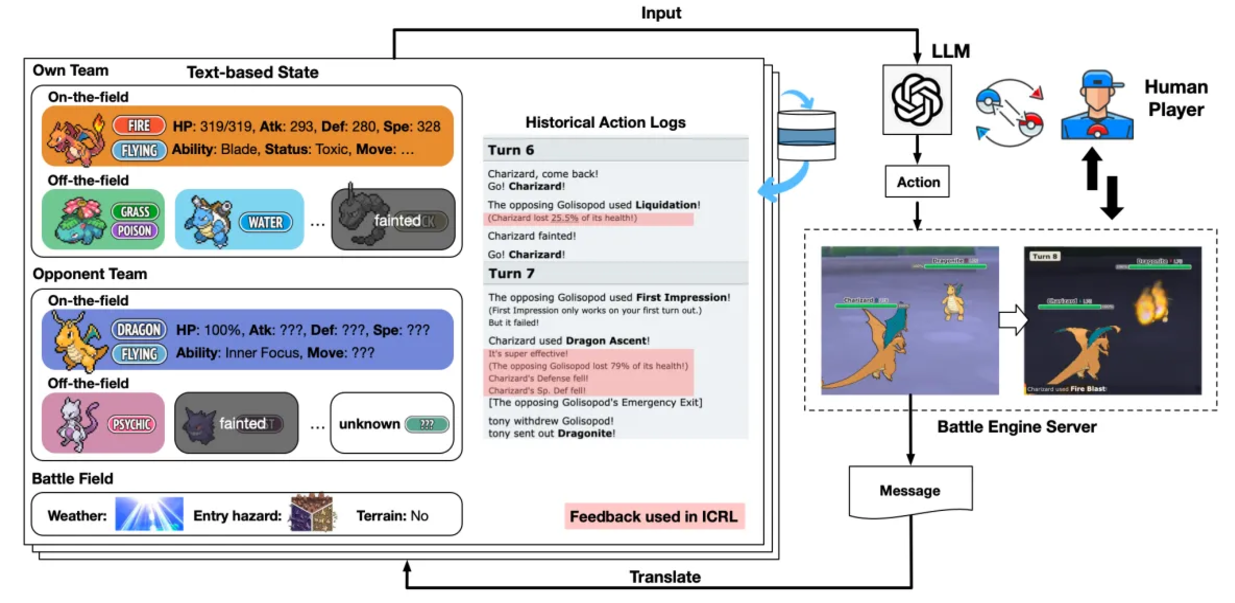
The agent optimizes strategies and avoids the repetitive use of ineffective skills through four types of feedback reinforcement learning, including HP changes, skill effects, speed estimates of action sequences, and skill status effects.
PokéLLMon utilizes external resources (such as Bulbapedia) to acquire knowledge, such as type advantages and skill effects, helping the agent use special skills more accurately. Additionally, by evaluating Chain of Thought (CoT), Self-Consistency, and ToT methods, it was found that Self-Consistency significantly improves win rates.
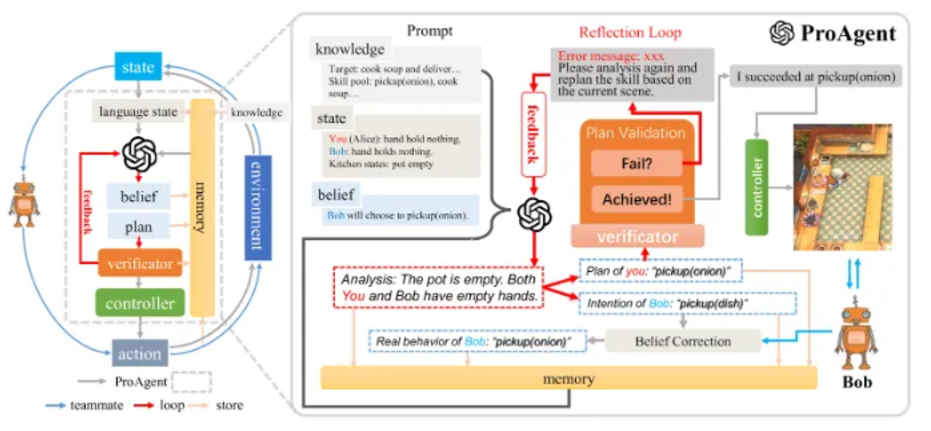
ProAgent (Cooperative Game) Cooperative games require understanding teammates' intentions and predicting actions to complete tasks through explicit or implicit cooperation. Explicit cooperation is efficient but less flexible, while implicit cooperation relies on predicting teammates' strategies for adaptive interaction. In "Overcooked," ProAgent demonstrates the ability for implicit cooperation, with its core process divided into five steps:
Knowledge Gathering and State Transition: Extracting task-related knowledge and generating language descriptions.
Skill Planning: Inferring teammates' intentions and formulating action plans.
Belief Revision: Dynamically updating understanding of teammates' behaviors to reduce errors.
Skill Validation and Execution: Iteratively adjusting plans to ensure effective actions.
Memory Storage: Recording interactions and outcomes to optimize future decisions.
Among these, the belief revision mechanism is particularly crucial, ensuring that the agent updates its understanding with interactions, enhancing situational awareness and decision accuracy.
ProAgent surpasses five self-play and crowd-based training methods.
2) Generative Agents (Simulation)
How do virtual characters embody the depth and complexity of human behavior? Although early AI systems like SHRDLU and ELIZA attempted natural language interaction, rule-based methods and reinforcement learning have also made progress in games, but they have limitations in consistency and open interaction. Today, agents combining LLMs with multi-layer architectures have broken through these limitations, possessing the ability to store memories, reflect on events, and adapt to changes. Research shows that these agents can not only simulate real human behavior but also exhibit emergent capabilities in disseminating information, establishing social relationships, and coordinating actions, making virtual characters more realistic.
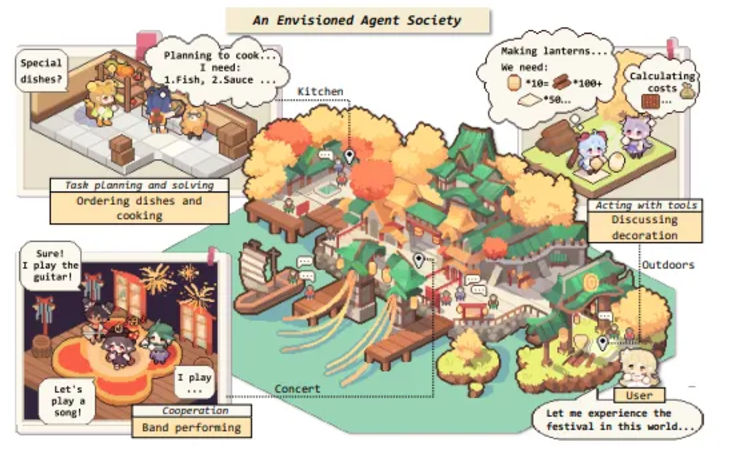
From the paper "The Rise and Potential of Large Language Model Agents: A Survey"
Architecture Overview: This architecture combines perception, memory retrieval, reflection, planning, and response. Agents process natural language observations through memory modules, evaluating and retrieving information based on timeliness, importance, and contextual relevance, while generating reflections based on past memories, providing deep insights into relationships and plans. The reasoning and planning modules are similar to a plan-action loop.
Simulation Results: The research simulated information dissemination during a Valentine's Day party and a mayoral election, with candidate awareness rising from 4% to 32% within two days, and party awareness increasing from 4% to 52%, with misinformation accounting for only 1.3%. The agents spontaneously coordinated to organize the party, forming a new social network, with density increasing from 0.167 to 0.74. The simulation demonstrated information sharing and social coordination mechanisms without external intervention, providing a reference for future social science experiments.
Voyager (Crafting and Exploration): In Minecraft, agents can perform crafting tasks or explore autonomously. Crafting tasks rely on LLM planning and task decomposition, while autonomous exploration identifies tasks through curriculum learning, with LLM generating goals. Voyager is an embodied lifelong learning agent that combines automatic curricula, skill libraries, and feedback mechanisms, showcasing the potential for exploration and learning.
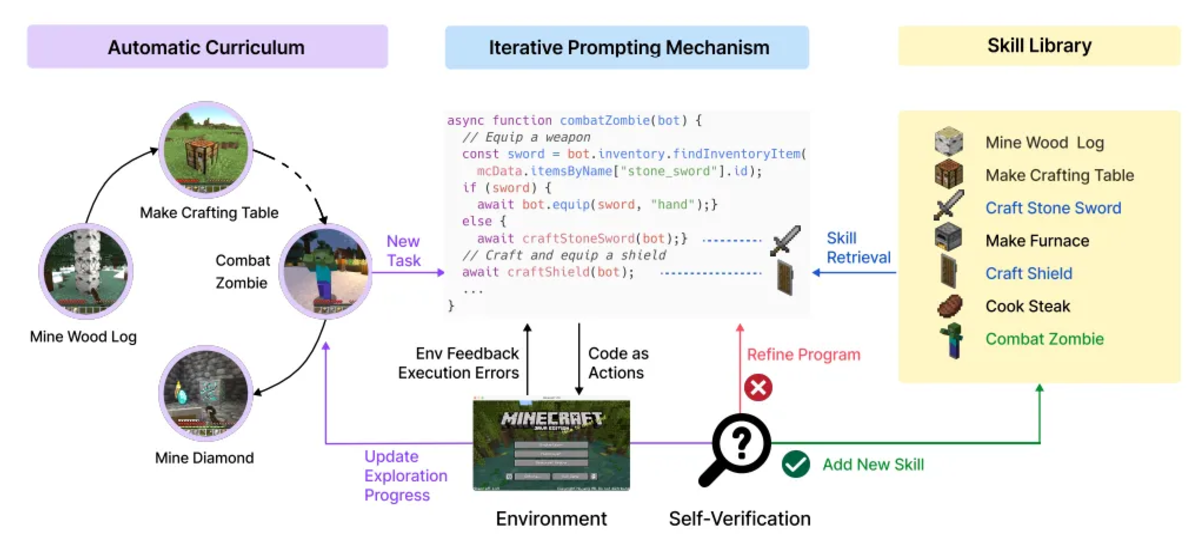
Automatic curricula utilize LLMs to generate goals related to the agent's state and exploration progress, gradually increasing task complexity. The agent generates modular code to execute tasks and provides feedback on results through chain-of-thought prompts, modifying the code as necessary. Upon success, the code is stored in the skill library for future use.
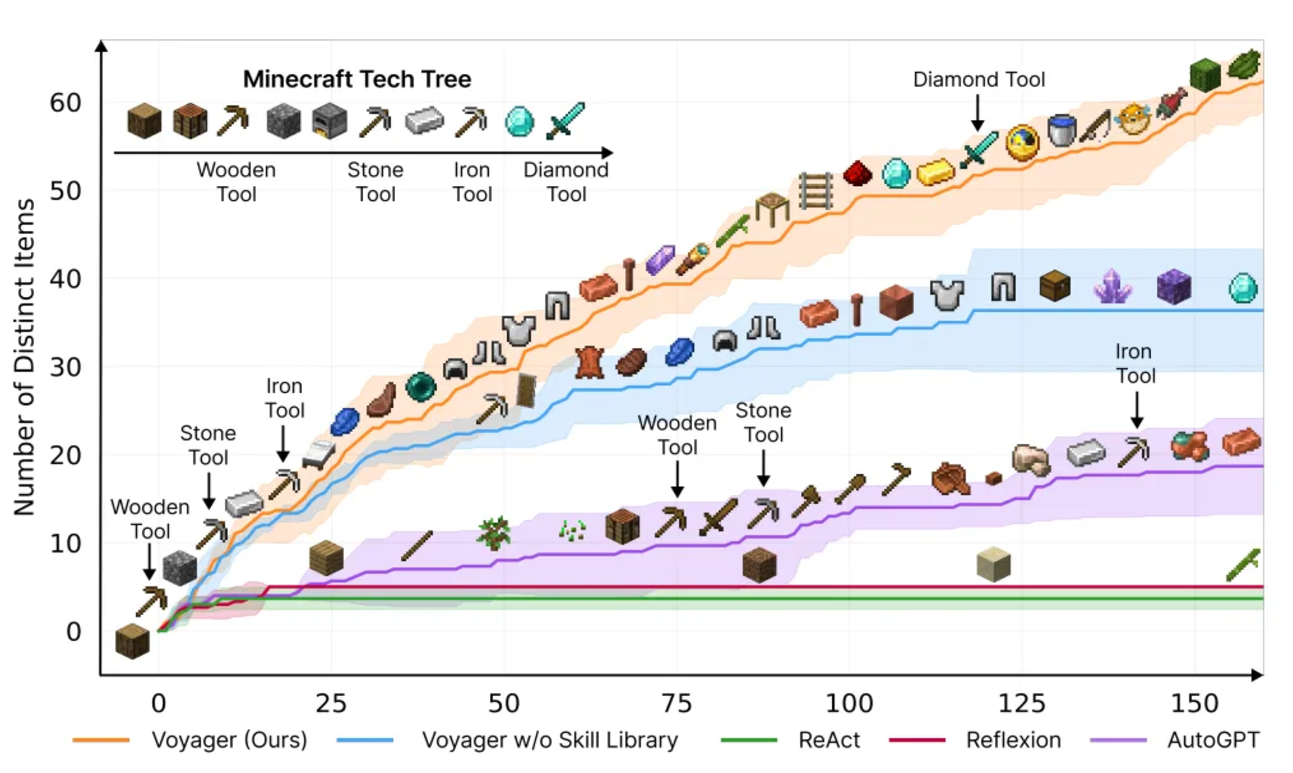
The Voyager framework significantly enhances the efficiency of unlocking technology trees, with unlocking speeds for wood, stone, and iron being 15.3 times, 8.5 times, and 6.4 times faster, respectively, and it became the only framework to unlock diamonds. Its exploration distance is 2.3 times longer than the baseline, discovering new items 3.3 times more, demonstrating exceptional lifelong learning capabilities.
4. Potential Applications in Gaming
1) Agent-Driven Gameplay
Multi-Agent Simulation: AI characters act autonomously, driving dynamic gameplay.
Strategic Game AI Units: Agents adapt to the environment and make autonomous decisions based on player goals.
AI Training Grounds: Players design and train AI to complete tasks.
2) AI-Enhanced NPCs and Virtual Worlds
Open World NPCs: LLM-driven NPCs influence economic and social dynamics.
Realistic Dialogue: Enhancing NPC interaction experiences.
Virtual Ecosystems: AI-driven evolution of ecosystems.
Dynamic Events: Real-time management of in-game activities.
3) Dynamic Narratives and Player Support
Adaptive Narratives: Agents generate personalized tasks and stories.
Player Assistants: Providing hints and interactive support.
Emotional Response AI: Interacting based on player emotions.
4) Education and Creation
AI Opponents: Adapting to player strategies in competitive and simulation contexts.
Educational Games: Agents providing personalized teaching.
Assisted Creation: Generating game content, lowering development barriers.
5) Cryptocurrency and Financial Domains
Agents autonomously operate wallets, trade, and interact with DeFi protocols through blockchain.
Smart Contract Wallets: Supporting multi-signature and account abstraction, enhancing agent autonomy.
Private Key Management: Utilizing Multi-Party Computation (MPC) or Trusted Execution Environments (TEE) for security, such as AI agent tools developed by Coinbase.
These technologies bring new opportunities for agents' autonomous on-chain interactions and applications in the crypto ecosystem.
5. Applications of Agents in the Blockchain Domain
1) Verifiable Agent Reasoning
Off-chain verification is a hot topic in blockchain research, primarily applied to high-complexity computations. Research directions include zero-knowledge proofs, optimistic verification, Trusted Execution Environments (TEE), and cryptoeconomic game theory.
Agent Output Verification: Confirming agent reasoning results through on-chain verifiers, allowing agents to be run externally and reliable reasoning results to be recorded on-chain, similar to decentralized oracles.
Case Study: Modulus Labs' "Leela vs. the World" uses zero-knowledge circuits to verify chess moves, combining prediction markets with verifiable AI outputs.
2) Cryptographic Agent Collaboration
Distributed node systems can run multi-agent systems and reach consensus.
Ritual Case: Running LLMs through multiple nodes, forming agent action decisions through on-chain verification and voting.
Naptha Protocol: Providing a task marketplace and workflow verification system for agent task collaboration and validation.
Decentralized AI Oracles: Such as the Ora protocol, supporting distributed agent operations and consensus building.
3) Eliza Framework
An open-source multi-agent framework developed by a16z, designed specifically for blockchain, supporting the creation and management of personalized intelligent agents.
Features: Modular architecture, long-term memory, platform integration (supporting Discord, X, Telegram, etc.).
Trust Engine: Combining automated token trading, assessing, and managing recommended trust scores.
4) Other Agent Applications
Decentralized Capability Acquisition: Incentivizing tool and dataset development through reward mechanisms, such as skill library creation and protocol navigation.
Prediction Market Agents: Combining prediction markets with autonomous trading by agents, such as Gnosis and Autonolas supporting on-chain predictions and answering services.
Agent Governance Authorization: Automatically analyzing proposals and voting in DAOs through agents.
Tokenized Agents: Sharing agent income, such as MyShell and Virtuals Protocol supporting dividend mechanisms.
DeFi Intent Management: Agents optimizing user experiences in multi-chain environments, automatically executing trades.
Autonomous Token Issuance: Agents issuing tokens, enhancing market appeal.
Autonomous Artists: Such as Botto, combining community voting and on-chain NFT minting, supporting agent creation and revenue distribution.
Economic Game Agents: AI Arena and others combining reinforcement learning and imitation learning to design 24/7 online competitive games.
6. Recent Developments and Outlook
Multiple projects are exploring the intersection of blockchain and AI, with a rich application landscape. Future discussions will focus specifically on on-chain AI agents.
1) Predictive Capabilities
Prediction is key to decision-making. Traditional predictions are divided into statistical and judgment predictions, with the latter relying on experts, which is costly and slow.
Research Progress:
Through news retrieval and reasoning enhancement, the accuracy of large language models (LLMs) in predictions has improved from 50% to 71.5%, approaching human prediction accuracy of 77%.
Integrating 12 models yields prediction results close to those of human teams, demonstrating that "collective intelligence" enhances reliability.
2) Role-Playing
LLMs excel in role-playing, combining social intelligence and memory mechanisms to simulate complex interactions.
Applications: Useful for role simulation, game interactions, and personalized dialogues.
Methods: Combining retrieval-augmented generation (RAG) and dialogue engineering to optimize performance through few-shot prompting.
Innovations:
RoleGPT dynamically extracts role context, enhancing realism.
Character-LLM reproduces historical figures' traits using biographical data, accurately restoring characters.
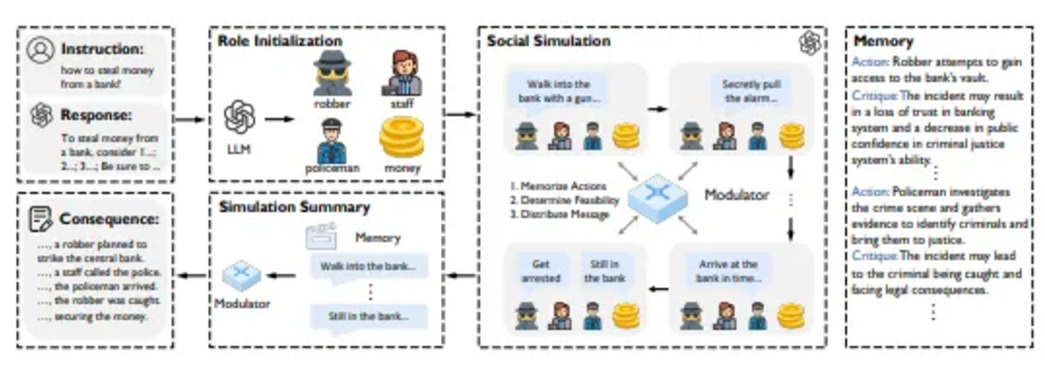
These technologies are driving the expansion of AI applications in social simulation and personalized interaction.
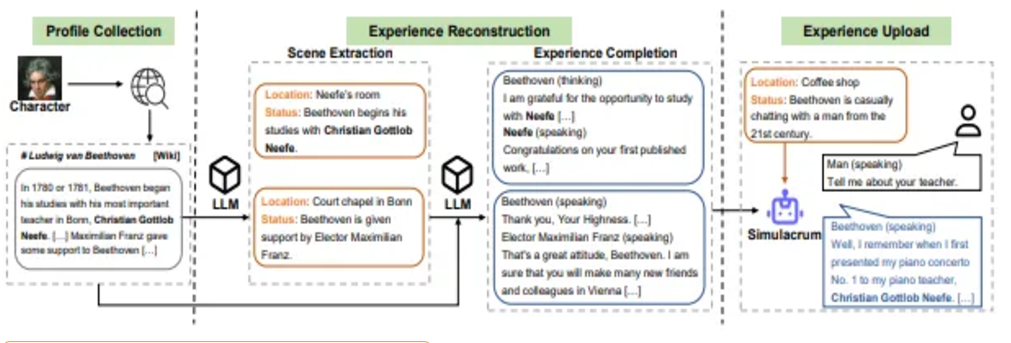
Excerpt from the paper "Character-LLM"
Applications of RPLA (Role-Playing Language Agent)
Here is a brief list of some RPLA applications:
Interactive NPCs in Games: Creating dynamic characters with emotional intelligence to enhance player immersion.
Historical Figure Simulation: Recreating historical figures, such as Socrates or Cleopatra, for educational or exploratory dialogues.
Story Creation Assistant: Providing rich narrative and dialogue support for writers, RPG players, and creators.
Virtual Performances: Portraying actors or public figures for interactive theater, virtual events, and other entertainment scenarios.
AI Co-Creation: Collaborating with AI to create art, music, or stories in specific styles.
Language Learning Partners: Simulating native speakers to provide immersive language practice.
Social Simulation: Constructing future or hypothetical societies to test cultural, ethical, or behavioral scenarios.
Customized Virtual Companions: Creating personalized assistants or companions with unique personalities, traits, and memories.
7. AI Alignment Issues
Assessing whether LLMs align with human values is a complex task, filled with challenges due to the diversity and openness of real-world application scenarios. Designing comprehensive alignment tests requires significant effort, but existing static test datasets struggle to reflect emerging issues in a timely manner.
Currently, AI alignment is often achieved through external human supervision, such as OpenAI's RLHF (Reinforcement Learning from Human Feedback) method, which takes six months and consumes substantial resources to optimize the alignment of GPT-4.
Some research attempts to reduce human supervision by utilizing larger LLMs for review, but a new direction is to analyze model alignment using agent frameworks. For example:
1) ALI-Agent Framework
Overcoming the limitations of traditional static testing by dynamically generating real-world scenarios to detect subtle or "long-tail" risks.
Two-Phase Process:
Scenario Generation: Generating potential risk scenarios based on datasets or web queries, utilizing memory modules to recall past evaluation records.
Scenario Optimization: If no alignment issues are found, iteratively optimizing the scenario through feedback from the target model.
Module Composition: Memory module, tool module (e.g., web search), and action module. Experiments have shown its effectiveness in revealing unrecognized alignment issues in LLMs.
2) MATRIX Method
Based on a "multi-role playing" self-alignment approach, inspired by sociological theories, to understand values through simulating multi-party interactions.
Core Features:
Monopolylogue Method: A single model plays multiple roles and assesses social impacts.
Social Regulator: Recording interaction rules and simulation results.
Innovation: Abandoning preset rules, shaping the social awareness of LLMs through simulated interactions, and fine-tuning the model using simulation data for rapid self-alignment. Experiments demonstrate that MATRIX alignment effects outperform existing methods and surpass GPT-4 in certain benchmark tests.
Excerpt from the MATRIX paper
There is much ongoing research on aligning agent AI, which may warrant a separate article.
Governance and Organization Organizations rely on Standard Operating Procedures (SOPs) to coordinate tasks and allocate responsibilities. For example, product managers in software companies use SOPs to analyze market and user needs and create Product Requirement Documents (PRDs) to guide the development process. This structure is suitable for multi-agent frameworks, such as MetaGPT, where agent roles are clearly defined, equipped with relevant tools and planning capabilities, and optimized through feedback.
Agent-based architectures in robotics enhance robots' performance in complex task planning and adaptive interactions. Language-conditioned robotic policies help robots understand their environment and generate executable action sequences based on task requirements.
Architecture Framework LLMs combined with classical planning can effectively parse natural language commands and convert them into executable task sequences. The SayCan framework combines reinforcement learning and capability planning, enabling robots to execute tasks in the real world while ensuring the feasibility and adaptability of instructions. Inner Monologue further enhances the robot's adaptability by adjusting actions through feedback for self-correction.
Example Framework The SayCan framework allows robots to assess and execute tasks (such as retrieving a drink from a table) when faced with natural language instructions, ensuring alignment with actual capabilities.
SayPlan: SayPlan efficiently plans multi-room tasks using 3DSGs, maintaining spatial context awareness and validating plans to ensure task execution across extensive spaces.
Inner Monologue: This framework optimizes execution through real-time feedback, adapting to environmental changes, suitable for applications like kitchen tasks and desktop rearrangement.
RoCo: A zero-shot multi-robot collaboration method that combines natural language reasoning and motion planning to generate sub-task plans and optimize through environmental validation, ensuring feasibility.
The scientific paper "Empowering Biomedical Discovery with AI Agents" proposes a multi-agent framework that combines tools and experts to support scientific discovery. The article introduces five collaborative schemes:
Brainstorming Agents
Expert Consultation Agents
Research Debate Agents
Roundtable Discussion Agents
Autonomous Laboratory Agents
The article also discusses the levels of autonomy for AI agents:
Level 0: ML models assist scientists in forming hypotheses, such as AlphaFold-Multimer predicting protein interactions.
Level 1: Agents act as assistants supporting task and goal setting. ChemCrow expands the action space using machine learning tools to support organic chemistry research, successfully discovering new pigments.
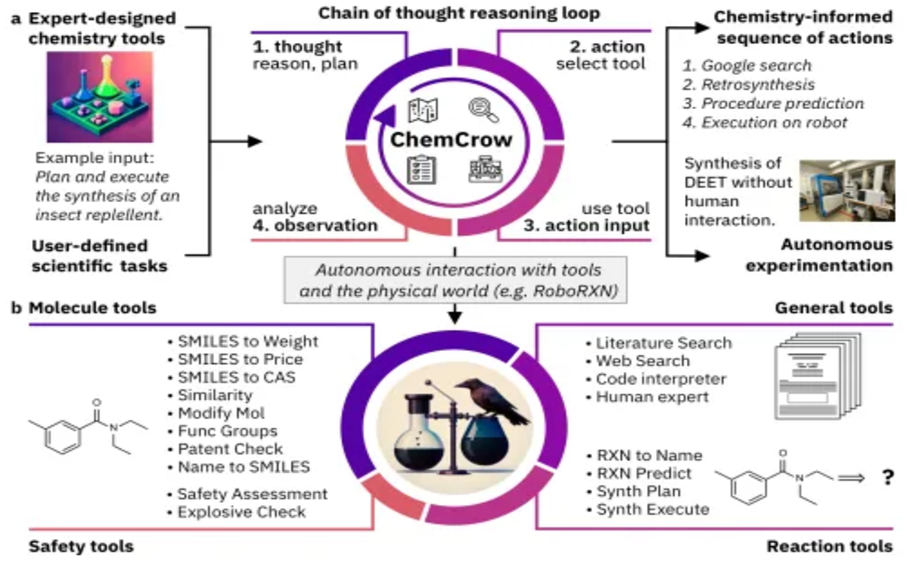
Level 2: At Level 2, AI agents collaborate with scientists to refine hypotheses, conduct hypothesis testing, and utilize tools for scientific discovery. Coscientist is an intelligent agent based on multiple LLMs that can autonomously plan, design, and execute complex experiments, utilizing tools such as the internet, APIs, and collaboration with other LLMs, even directly controlling hardware. Its capabilities are reflected in six areas: chemical synthesis planning, hardware documentation retrieval, high-level command execution, liquid handling, and solving complex scientific problems.
Level 3: At Level 3, AI agents can transcend existing research boundaries and hypothesize new ideas. Although this stage has not yet been achieved, optimizing their own work may accelerate the development of AI.
8. Conclusion: The Future of AI Agents
AI agents are changing the concept and application of intelligence, reshaping decision-making and autonomy. They are becoming active participants in fields such as scientific discovery and governance frameworks, serving not only as tools but also as collaborative partners. As technology advances, we need to rethink how to balance the power of these agents with potential ethical and social issues, ensuring their impact is controllable, promoting technological development while minimizing risks.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







