The Autonomys network is a decentralized infrastructure stack designed to enable secure and autonomous human-machine collaboration, allowing anyone to join with just an SSD.
Written by: Feng Chen¹ ², Daria Boreichina³, Jeremiah Wagstaff¹ ³
1 Autonomys Labs
2 University of British Columbia
3 Subspace Foundation
Abstract
As artificial intelligence (AI) increasingly integrates into our daily lives, we find ourselves at a critical moment in redefining the roles of humans and machines in modern society. AI technologies pose significant challenges to current socio-economic structures and theories while also providing unprecedented opportunities to establish new paradigms. Autonomys presents a vision of an AI-enhanced world that enhances human autonomy rather than diminishes it. The Autonomys network is a decentralized infrastructure stack aimed at achieving secure and autonomous human-machine collaboration, allowing anyone to join with just an SSD. We built this network from the ground up to achieve security, scalability, and decentralization simultaneously, with the core being the Subspace protocol, a novel storage-based consensus protocol that separates consensus from execution. Through this proposer-builder separation, the Autonomys network can independently scale transaction processing and storage needs while maintaining a fully decentralized blockchain, with low barriers to entry—critical for achieving decentralized AI, or AI3.0.
Background
The rapid development of artificial intelligence (AI) technologies is ushering in a new era of socio-economic transformation. Recent breakthroughs in machine learning (ML), particularly in deep learning and natural language processing, have enabled AI systems to perform tasks once thought to be exclusive to human intelligence【1】. This progress has sparked discussions about the future of work, with some experts predicting large-scale job displacement【2】, while others envision new forms of human-machine collaboration【3】. Meanwhile, the rise of blockchain technology has introduced new paradigms for decentralized systems and digital identities【4】. The development of these technologies has been accompanied by concerns about data privacy, algorithmic bias, and the concentration of AI capabilities in a few large companies【5】.
As we approach the potential developments of artificial general intelligence (AGI) and artificial superintelligence (ASI)—where AI reaches and surpasses human intelligence levels【6】—it becomes crucial to establish frameworks that ensure AI systems align with human values and maintain human autonomy in an increasingly automated world【7】. The Autonomys network proposes and seeks to implement a new paradigm of "radical autonomy," which is absolute digital self-governance.
AI3.0
The development of artificial intelligence can be broadly divided into three stages, each presenting a unique relationship between humans and AI, as well as varying degrees of decentralization:
- AI1.0 — Centralized Machine Learning: The proliferation of deep learning, where developers can build models on cloud computing platforms provided by large tech companies using tools like TensorFlow and PyTorch. Humans primarily act as passive consumers of AI technologies, interacting with narrow, rule-driven systems designed for specific tasks.
- AI2.0 — Centralized Generative AI: The emergence of large language models (LLMs) such as ChatGPT, Gemini, and Claude, alongside other generative AI technologies built by large tech companies. Although humans gain more interactive AI experiences, these experiences are still delivered through platforms controlled and deployed by centralized entities.
- AI3.0 — Decentralized Human-Centric AI: The development and deployment of AI models, applications, and agents supported by an open, accessible, and collaborative web3. Decentralization ensures a transparent, composable, and secure ecosystem that fosters innovation. Humans not only interact with AI but can also customize, train, and deploy their own Autonomys agents, which can act on their behalf, blurring the lines between AI creators and consumers. The era of autonomy is the pinnacle of this paradigm.
The Era of Autonomy
Throughout the history of technological development, humans have consistently sought to meet three fundamental needs: security, encompassing the assurance of material and resources; connection, whether physical or emotional ties with others or cultural collectives; and prosperity, achieved through self-improvement and socio-economic development. Many experts have discussed the impact of AI on human security, connection, and prosperity【3】【7】【8】. Autonomys is proposing a human-centered vision for the future post-AI revolution, guided by these three fundamental human needs.
In today's world, an individual's security and prosperity largely depend on their access to economic resources. As the rise of high-level AI poses an increasing threat to job security【2】, we must improve existing economic systems while maintaining human relevance and autonomy. This can be achieved by expanding global access to permissionless incentive contribution networks and enhancing human capabilities to own personal AI agents that can interact and collaborate seamlessly in verifiable environments—completely free from centralized control.
As AI technology trends toward training and running smaller, specialized AI models on personal edge devices, these AIs can be integrated into every operation of personal devices【9】. These AIs will have access to all contextual information of the device owner, including past and present interaction records with others or services; personal preferences for entertainment, diet, clothing, and partners; health data; financial status; political inclinations; and all other information processed by the device. Combining comprehensive contextual data with intelligent agent capabilities transforms personal AIs into agents that can act online on behalf of users—booking medical services and vacations, ordering food, coordinating meetings, managing finances, and even participating in governance. These personal agents will also be able to analyze and filter the endless stream of information around us—an amount of information that is difficult for individuals to process—thus helping us make decisions.
It is foreseeable that the number of online agents will be at least comparable to the number of smartphones. In fact, we can expect that every individual and business will have multiple dedicated AI representatives. This global network of billions of agents will communicate online and authorize operations with service providers. Humans and agents will need to be able to verify whether the AIs interacting in this autonomous agent economy genuinely represent specific individuals or organizations (see the agent identity section).
In the agent economy supported by Autonomys, collaboration between humans and AI will form a rich ecosystem. The Autonomys development platform will provide individuals and organizations with cutting-edge tools for training and deploying agents, acquiring valuable technical skills, and enhancing their potential. Autonomys agents will be able to authorize each other through blockchain to provide real-world goods and services while humans maintain oversight and control. This dynamic offers new entrepreneurial and value-creation pathways for individuals and organizations to leverage AI capabilities to enhance their skills and services. Autonomys' vision maintains human economic relevance by emphasizing areas of unique human creativity, emotional intelligence, and complex problem-solving abilities that have yet to be replicated by AI.
In contrast to future predictions that rely on universal basic income (UBI), which would result in a loss of human autonomy and economic relevance【10】, Autonomys advocates for radical autonomy through incentivizing participation and contributions to a self-sustaining ecosystem, inspired by Ethereum's pioneering model. We recognize that human potential is a dynamic force that can be continuously expanded through education, technological integration, and innovation within socio-economic systems.
By empowering individuals with autonomy over their digital identities, control over their data assets, and secure AI collaboration tools, Autonomys is shaping a future where humans and AI can coexist productively and harmoniously. This new paradigm not only preserves human economic relevance but amplifies our collective potential, ushering in an unprecedented era of innovation, creativity, and shared prosperity.
Autonomys AI3.0 Technology Stack
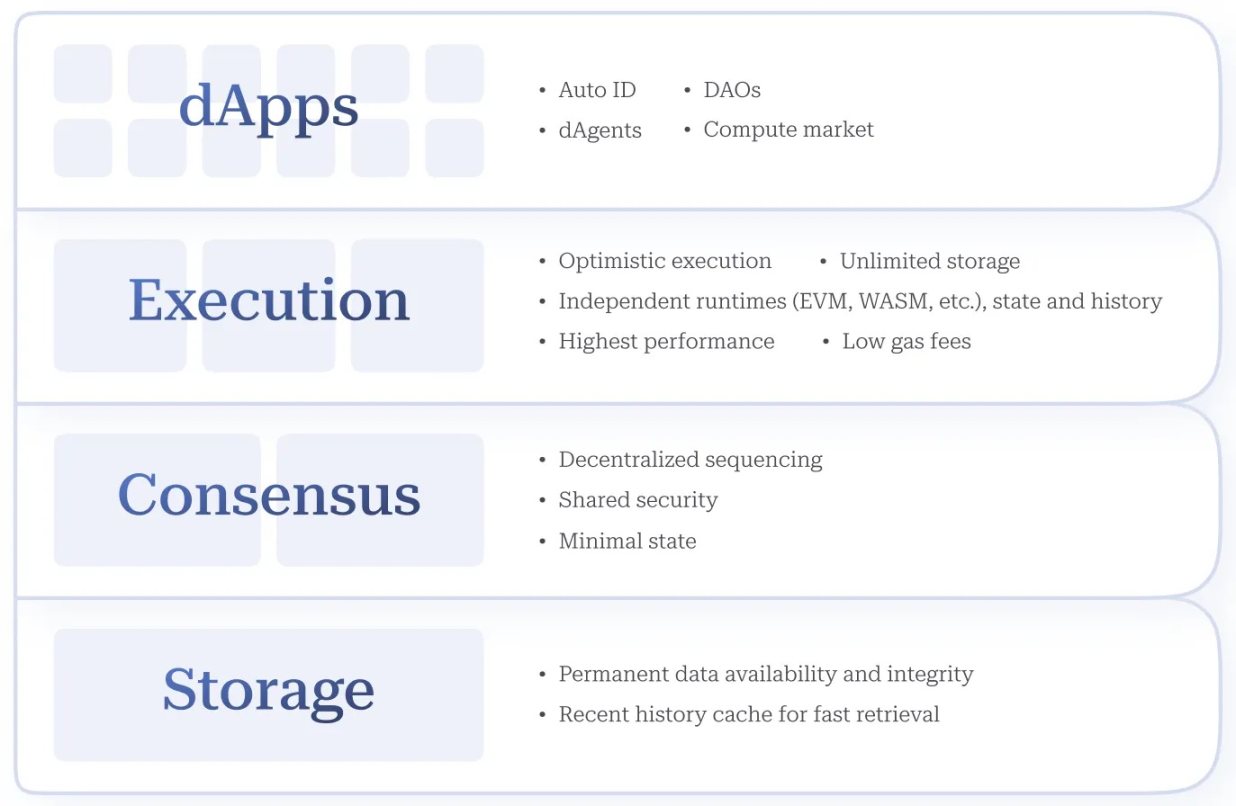
Figure 1. Autonomys Network Stack
The Autonomys network serves as the technological infrastructure for this paradigm shift, providing a vertically integrated decentralized AI technology stack that includes the following layers (see Figure 1):
- dApp/Agent Layer: Supports the development and deployment of super dApps (AI-driven dApps) and Autonomys agents (on-chain agents with Auto ID integration) for verifiable digital interactions.
- Execution/Domain Layer: Secure, scalable distributed computing for AI training, inference, and agent workflows.
- Consensus Layer: Verifiable decentralized ordering and transaction validation, ensuring shared security.
- Storage Layer: Distributed storage ensures data integrity and permanent availability, which is crucial for storing large amounts of AI data.
Utilizing the Subspace protocol【11】, with its innovative Proof-of-Archival-Storage (PoAS) consensus mechanism, our decentralized physical infrastructure network (DePIN) incentivizes active participation through permissionless contributions of storage space or computing resources and any amount of token staking, achieving unprecedented accessibility.
Building Future-Proof Storage for AI3.0
The emergence of AI3.0 brings an unprecedented demand for vast, permanent, decentralized storage that must possess rapid data retrieval capabilities. As AI systems become more complex and personalized, they require access to large datasets for training, fine-tuning, and real-time decision-making. Traditional centralized storage systems cannot meet the new paradigm's demands for scalability, security, and accessibility.
Decentralized storage solutions offer several key advantages: ensuring data integrity and availability through redundancy; avoiding single points of failure; and achieving fairer resource distribution. Additionally, the permanence of data storage is crucial for maintaining historical records, enabling long-term learning, and supporting accountability mechanisms in AI decision-making processes. Rapid data retrieval is equally important, as AI3.0 agents must be able to quickly access relevant information to provide real-time responses and make informed decisions. This combination of vast capacity, permanence, decentralization, and speed is foundational to fully realizing the potential of AI3.0—where personalized Autonomys agents can efficiently and verifiably operate at scale.
Autonomys addresses this growing demand through our ultra-fast, large-scale, permanent distributed storage network (DSN) and a content delivery network (CDN) supported by multiple layers of reliability. These networks are supported globally by thousands of easily set up nodes, secured by the PoAS consensus mechanism. The core concept of the Autonomys economy is data sovereignty, achieved through our vast decentralized storage and content contribution, provenance tracking, and compensation systems. This revolutionary approach to personal information and intellectual property management empowers individuals to control their data assets and choose to use them for AI training and optimization in exchange for compensation, rather than being exploited without remuneration as is currently the case.
Content Provenance and Data Sovereignty
In an era where sensitive data is often abused by criminals and centralized entities, data sovereignty—the control and management rights individuals have over their personal data and digital existence—becomes particularly important. To achieve data sovereignty, a mechanism must be established that can verifiably establish data ownership and provenance.
By cryptographically linking digital content to the verified identity of its creator, an immutable record of content provenance and subsequent modifications can be established【13】. Such a system grants users fine-grained control over their data sharing preferences and provides a robust framework for verifying the authenticity of digital assets. This system may also offer solutions to the challenges posed by synthetic media, enabling recipients to distinguish between genuine content and artificially generated content【14】. Furthermore, as AI systems continue to evolve and generate increasingly complex outputs, the ability to trace the provenance of training data and generated content becomes ever more critical【15】.
Digital Identity
The decentralized digital identity protocol provided by Autonomys—Autonomys Identity (Auto ID)—not only allows for the authentication of AI-generated content but also supports permission management for agent behavior. Utilizing advanced cryptographic techniques, our self-sovereign identity (SSI) framework operates as a registered runtime deployment on the Autonomys domain layer, enabling individuals to verify their identity without relying on invasive biometric programs. This digital trust foundation is crucial for facilitating economic collaboration between humans and AI.
Key attributes of the Auto ID system include:
- Autonomy: Users maintain complete control over their digital identity, autonomously deciding on information sharing through encryption, zero-knowledge proofs, and verifiable credentials.
- Verifiability: Cryptographic proofs ensure the authenticity of claims without disclosing personal information.
- Universality: Auto ID can be assigned to any entity, whether human or AI, supporting universal identity standards within the digital ecosystem.
- Versatility: The Auto ID framework supports self-issuance, third-party issuance, and multi-party co-issuance of identities.
- Interoperability: Auto ID is designed to seamlessly integrate with existing identity systems, such as X.509【16】 and decentralized identifiers【17】.
Auto ID plays a critical role in establishing content provenance and ensuring data sovereignty. Once an entity obtains an Auto ID, it can digitally sign the content it generates, establishing a verifiable and tamper-proof authenticity and provenance record associated with its Auto ID. This is particularly important as the lines between human-created content and machine-generated content become increasingly blurred.
By cryptographically linking digital content to the verified identity of its creator, an immutable record of origin and subsequent modifications is established. This system enables users to exert fine-grained control over their data sharing preferences and provides a powerful framework for verifying the authenticity of digital assets. It also offers potential solutions to the challenges posed by synthetic media, allowing recipients to distinguish between genuine content and artificially generated content. Additionally, as AI systems continue to evolve and generate increasingly complex outputs, the ability to trace the lineage of training data and generated content becomes increasingly important.
Autonomys also provides the capability to attach cryptographic identity claims to Auto ID through verifiable credentials. For example, individuals can attach a verifiable credential showing they hold a valid diploma to their Auto ID and use that claim when a diploma is required. The Auto ID framework supports self-issuance of identities, issuance by other entities, and co-issuance by multiple entities.
Personhood Verification
As we enter a world integrated with agents, the ability to distinguish between human and artificial entities becomes increasingly important. Auto ID achieves personhood verification (PoP) through our composable probabilistic personhood verification protocol, Auto Score. This system is designed to meet the growing demand for verifiable human identities in the digital space, particularly in scenarios where AI agents and humans interact seamlessly.
In the era of AI3.0, a robust PoP system is crucial for several reasons:
- Preventing AI Impersonation: As AI becomes more intelligent, the risk of AI systems impersonating humans increases. A strong PoP system helps maintain the authenticity of interpersonal interactions in the digital space.
- Ensuring Fair Resource Distribution: In a world where AI agents could overwhelm systems, PoP ensures that resources and opportunities are fairly distributed among real human users.
- Maintaining Democratic Processes: PoP is essential for online voting or governance systems to prevent manipulation by automated systems or masquerading accounts.
- Preserving a Human-Centric Economy: As AI agents proliferate in economic systems, PoP helps retain space for human economic activity, preventing AI from dominating the market.
- Promoting Ethical AI Development: PoP systems help ensure that AI training data comes from verified human sources, fostering more ethical and representative AI development.
Auto Score provides probabilistic personhood verification scores by combining existing personhood verification evidence with zero-knowledge proofs (ZKP) to generate privacy-preserving, verifiable credentials. By using ZKP passport verification as the primary personhood verification factor, users can simply scan the NFC chip in their passport and obtain a high Auto Score by proving correctness through ZK. Combined with liveness detection, ZK passport technology provides the strongest evidence for unique identity verification, contributing to the highest possible Auto Score.
For applications that do not require government-level identity verification, as well as for users who do not hold or wish to associate their passport, Auto Score accepts alternative personhood verification factors. These factors include credit cards, social media accounts, and participation in decentralized networks. As a probabilistic PoP protocol, Auto Score generates a probability score representing the entity as an independent human by aggregating and evaluating various supporting evidence for personhood verification. As users add or remove credentials or as their digital interactions evolve, Autonomys dynamically updates this score, providing a flexible measurement standard for digital personhood verification.
Auto Score has the following characteristics:
- Probabilistic: Provides a refined measurement of identity rather than a simple binary judgment, reflecting the complexity of identity in the digital age.
- Privacy-Preserving: Utilizes ZKP and advanced cryptographic techniques to allow users to prove their identity without disclosing sensitive personal information, which is particularly important in an era of increasing data breaches and privacy concerns.
- Dynamic: The personhood verification probability score updates as users interact with the Autonomys ecosystem, reflecting their ongoing participation and contributions and adapting to the evolution of digital identity.
- Composable: Users can gradually build their digital identity by combining various evidence, allowing for a more comprehensive and nuanced representation of personhood verification.
- Flexible: Users have complete control over the verification components they wish to include, managing their digital identity to meet personalized needs.
- Interoperable: Seamlessly integrates with current and future identity systems and existing identity evidence from web2 or web3 accounts, utilizing TLS ZK proofs【18】【19】【20】 for rapid verification, improving user experience and bridging gaps across different digital ecosystems.
A composable, privacy-protecting personhood verification protocol is crucial for establishing a novel digital identity system in an AI-integrated world. This approach aims to provide a familiar user experience while maintaining absolute privacy and anonymity. By leveraging various existing personhood verification factors, Auto Score overcomes accessibility and centralization issues present in current biometric PoP protocols, ensuring that everyone can autonomously prove their human identity without geographic and institutional constraints. By viewing personhood verification as a composable and probabilistic measurement, Autonomys offers a more detailed and flexible solution to the challenge of verifying human identity in the digital space. The system builds trust for human-machine interaction and decentralized governance processes while protecting individual privacy.
Auto ID and Auto Score make a significant contribution to the development of the automated economy by providing an accessible, standardized framework for digital identity and data provenance. This will help achieve verifiable human-machine interactions, support privacy-focused verification, establish trust metrics, and ensure traceability, promoting digital security and inclusivity in an increasingly AI-driven world.
Decentralized Reputation System
As part of the Autonomys network, Auto ID and Auto Score lay a solid foundation for building a robust decentralized reputation system (DRS) that will allow participants to anonymously yet verifiably declare their reputation【22】. The DRS based on Auto ID will empower users to selectively share reputation claims, such as credit scores or developer reputations, in a manner that cannot be traced back to their primary ID while maintaining resistance to Sybil attacks and security. Such a powerful DRS will enable the construction of new types of applications on Autonomys, from peer-to-peer commerce and gig economy platforms to decentralized lending, crowdfunding, and collaborative research protocols.
Decentralized Learning and Training Proof
Decentralized learning approaches aim to train machine learning models across multiple devices or nodes without relying on centralized data aggregation, thereby protecting privacy and data ownership. The underlying Subspace protocol of the Autonomys network is particularly well-suited to support decentralized learning, as it addresses several challenges that hinder the practical application of decentralized AI storage/computing sharing DePIN.
Li (2023)【23】 points out that the significant state storage and bandwidth requirements of machine learning are major barriers to the mainstream availability of existing systems. We address the issues of state bloat and historical growth exceeding the capacity of individual nodes through our novel Proof-of-Archival-Storage (PoAS) consensus mechanism and distributed storage network (DSN) design, supporting the distributed storage of partial states and histories. Without compromising decentralization, as the scalability roadmap is implemented, the Autonomys network will possess the bandwidth to support the massive transfer demands of AI training data and models.
Li also proposed that the ability to dynamically adjust workloads based on AI task requirements, independent of transaction validation and consistent block time requirements, is an important feature for decentralized AI practical networks. Autonomys achieves this through its Decoupled Execution (DecEx) framework, which allows domains—independent execution environments—to set specific hardware requirements for nodes executing within that domain, submitting state transitions only when needed. This architecture enables effective allocation of computational resources for decentralized learning tasks while maintaining the normal operation of the blockchain and other network activities.
The training proof (AI-PoT, to distinguish it from proof of time PoT) protocol described by Li can adapt to become a dedicated domain on the Autonomys network. The AI-PoT domain will manage the training process, including task allocation, model validation, and reward distribution, benefiting from the underlying security and scalability of the Autonomys network. Operators of this domain will act as service providers, validators, and auditors, with roles and responsibilities defined by the training proof protocol. This workflow operates on the Autonomys domain framework as follows:
- Client Submission: Clients submit orders containing model specifications, training data, and payment information to the AI-PoT domain via transactions.
- Order Processing: Order transactions are placed in the domain's memory pool and eventually added to a bundle, which is then submitted to the consensus chain and included in a block by farmers. Once in a block, service providers (a selected subset of staked domain operators) can access the order.
- Model Training: Service providers compete to train the best model according to the order specifications.
- Claim Submission: As service providers generate improved models, they submit claims containing model signatures to the network.
- Model Disclosure: At the end of the training period, operators disclose the complete model corresponding to the submitted signature.
- Verification Phase: Other operators in the AI-PoT domain evaluate the disclosed model using specified verification functions and test data, broadcasting verification messages.
- Verification: Any honest operator within the domain can challenge suspicious verifications, adding an extra layer of security.
- Challenge Period: A time window allows for the resolution of potential challenges.
- Finalization: The network determines the best model and corresponding rewards during the challenge period.
- Payment Distribution: After the challenge period ends, payments are distributed to the winning service providers and validators.
- Result Retrieval: Clients can retrieve the best model from the network.
The native token of the Autonomys network can be used for staking and rewards within the AI-PoT domain, forming a reliable economic incentive structure to ensure honest participation. By integrating AI-PoT as a domain, the Autonomys network will be able to provide a forward-looking distributed AI training solution that adapts to new AI models and training methods without changing the core protocol.
The flexible domain framework of Autonomys also allows for the implementation of other common decentralized learning paradigms, including federated learning and collective learning, which can be adjusted according to the specific needs of applications. To enhance the security and privacy of the federated learning process, Autonomys plans to introduce secure multi-party computation (MPC), differential privacy, and other advanced cryptographic techniques【24】 into the network. These methods allow for the aggregation of model updates without exposing users' personal data, thereby protecting user privacy while providing valuable contributions to AI development.
The integrated decentralized learning system with Auto ID will benefit from a persistent Decentralized Reputation System (DRS), allowing computing providers, ML engineers, and agent developers to record their previous contributions, training models, and quality proofs of application building.
Data Contribution and Compensation
Consumer devices, industrial hardware, and other electronic devices generate and record vast amounts of information about the world, which is often discarded once it becomes useless to the device owners. In some cases, data is retained by device manufacturers, with device owners being completely unaware. As AI models have nearly exhausted the existing internet-accessible data sources globally, real-time data provided by Internet of Things (IoT) hardware becomes the next step for machine learning data acquisition.
The Auto ID framework can be used to allow users to participate in decentralized learning programs (such as federated learning and collective learning), supporting machine learning models through data contributions while maintaining privacy and control over personal information. Decentralized learning avoids the need for centralized data storage by training models on distributed datasets, thereby reducing the risks of data breaches and unauthorized access. Combining decentralized learning with blockchain-based identity and compensation mechanisms marks a significant step toward a fairer and more decentralized AI ecosystem.
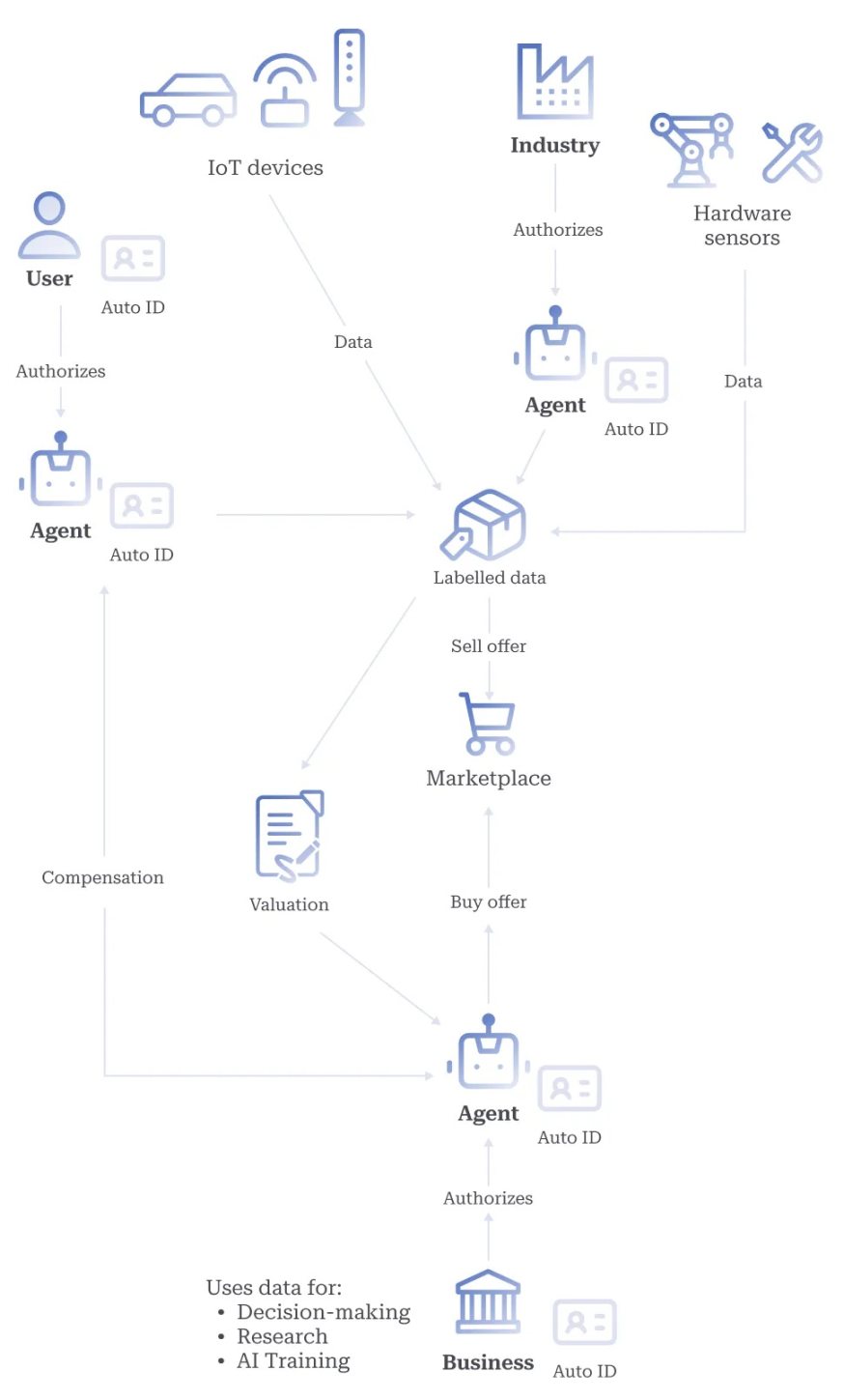
Figure 2. Data Contribution and Compensation
Additionally, this creates a new paradigm for data ownership and monetization, enabling individuals to directly benefit from the value of their data in AI systems (see Figure 2). This approach aligns with the principles of data sovereignty and decentralized AI (deAI) and addresses the growing concerns over data privacy and the centralization of AI development【25】【26】.
To incentivize the contribution of high-quality data and ensure fair compensation, the Autonomys network will adopt a Shapley value-based approach【27】【28】 to build a data valuation framework that quantifies individual contributions to the decentralized learning process. The algorithm will consider multiple factors, including data quality, uniqueness, relevance to specific models, and impact on model performance improvement. This method aims to accurately reflect the true value of each user's data contribution, rather than relying solely on the volume of data.
The valuation process will be supplemented by a compensation mechanism using the native tokens of the Autonomys network. This dedicated mechanism naturally fits into the domain layer of Autonomys's Decoupled Execution environment (DecEx), supporting independent development and scalability without burdening the core protocol. The domain will automatically compensate users each time data is accessed or utilized in model training or inference. Given that the system needs to handle a large number of users and data points during each training and inference request and generate multiple payments accordingly, we will implement several optimizations, including accumulating compensation in smart contracts that users can claim. All accumulated and claimed records will be anchored and stored in the global history of the blockchain, ensuring transparency and immutability of data usage and corresponding compensation.
The system may also implement a dynamic pricing model that adjusts compensation based on market demand for specific types of data, thereby creating a more efficient data market. An additional benefit is that this approach may help form more diverse and representative datasets, addressing bias issues in AI systems caused by limited or homogenized training data.
Agent Infrastructure and Multi-Agent Systems
AI models (agents) that can autonomously interact with their environment can collaborate in distributed environments to accomplish complex tasks and achieve common goals, becoming part of multi-agent systems (MAS). The emergence of agent technology ecosystems, such as BabyAGI【29】, AutoGPT【30】, and GPT-Engineer【31】, demonstrates the immense potential of autonomous AI systems. These projects showcase the ability of AI agents to execute complex tasks, achieve goal-oriented behaviors, and even recursively improve their own capabilities. At their core are simple yet powerful technologies—task and response chains—that decompose large tasks into independent subtasks, autonomously executing and self-validating outputs in a multi-step process. Frameworks like LangChain【32】 extend these agent capabilities by providing API calls that enable local agents to interact with the "external" world. Chainlink Functions【33】 combine web2 APIs with blockchain tracks and web3 smart contracts. The success of such projects has ignited widespread interest in "agentology," showcasing a future where AI agents play increasingly important roles across various applications. If everyone and every business has multiple agents representing their actions, we must build the economic infrastructure to support billions of such agents.
The infrastructure for agent deployment varies in its hosting structure and location, as well as in how it interacts with external service providers and other agents. At the hosting layer, agents can be classified into dedicated agents—capable of running independently on edge devices using smaller models—and general agents—requiring high-density GPUs and substantial memory. General agents utilize large models for task decomposition, prioritization, and result validation, possessing higher reasoning capabilities compared to dedicated agents, while dedicated agents have the advantage of low latency, low power consumption, and privacy protection when running on local devices. Therefore, it is assumed that significant heterogeneity in model scale, hardware requirements, and capabilities will exist in the future. With the inter-domain universal composable interfaces and networks of the Autonomys network, agents can achieve interoperability with various platforms. For agents that require hardware beyond the self-hosting capabilities of a single user or organization, they can be programmed to run on-demand or continuously through dedicated Autonomys computing-sharing domains. On-chain agents (Autonomys agents) that are in a state of continuous high demand on the network can choose to deploy on independent domains with specific hardware requirements.
Additionally, agents need digital storage to integrate their memory and knowledge bases. The decentralized storage layer of the Autonomys network can provide this data availability. The most efficient agent decision-making occurs when agents can access data beyond their training sets, such as event information occurring after training completion, domain expertise, or users' personal data. For example, financial trading agents heavily rely on global real-time news, as do many other applications. By extracting data from the sovereign data economy described in "Data Contribution and Compensation" (stored in archival storage) and compensating data creators in the market, Autonomys agents can perform retrieval-augmented generation (RAG), thereby accessing data that enhances the reliability of AI-generated outputs.
At higher levels of the stack, Autonomys agents execute tasks on behalf of users according to user intent. This involves user authorization for agents to perform certain permitted activities, including managing user authentication when interacting with external services and accessing users' financial resources to pay for goods and services. Each Autonomys agent interacting in the network is granted an identity upon deployment, registered through Auto ID, providing a verifiable and tamper-proof agent identity. These IDs can be issued by individuals or organizations and come with metadata about the agent's purpose and capabilities. On Autonomys, humans, organizations, and agents can use Auto ID to define hyper-specific agent interaction permissions, enhancing security and privacy. Once agents obtain Auto ID, they can access the economic system of the network, manage balances, spend funds, and receive payments. All identity claims, authorization events, and agent interactions can be verified on-chain, providing a transparent and immutable audit trail for post-analysis. As a unified system for all on-chain entities, Auto ID simplifies the process for users and other agents to call registered agents. This agent calling mechanism is enhanced by a decentralized reputation system to achieve optimized reliability and performance.
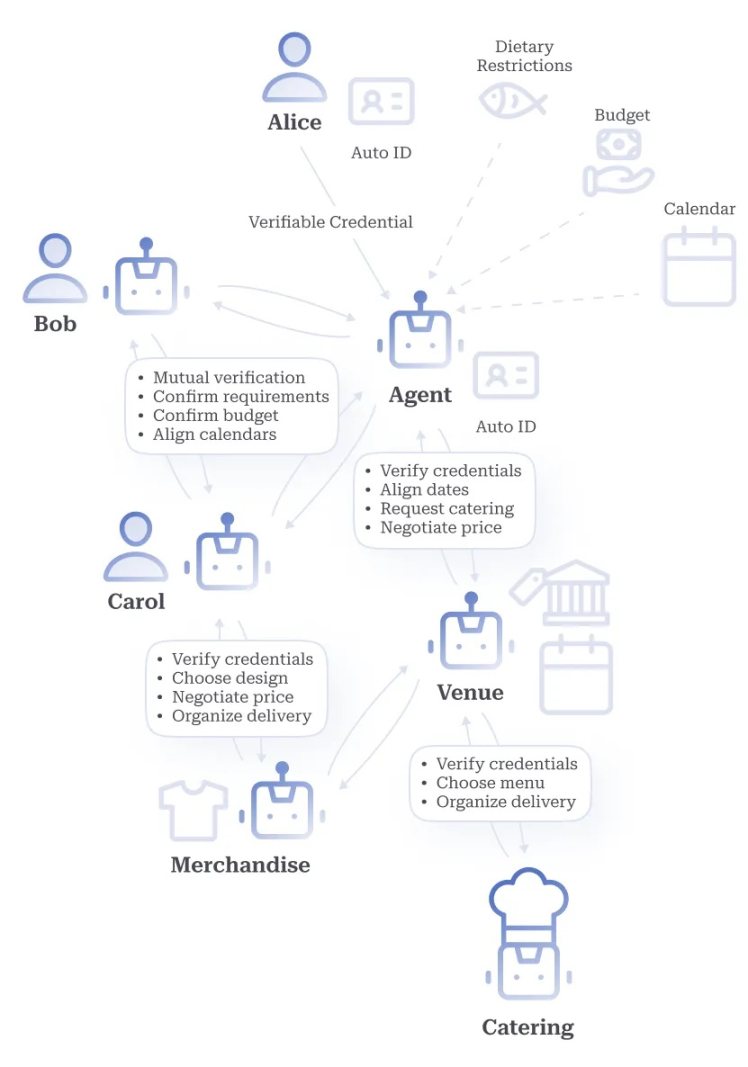
Figure 3. Example of MAS
Communication between agents requires a universal interface to facilitate seamless interaction and collaboration on complex tasks, such as organizing meetings, as shown in Figure 3. The unified identity framework of Autonomys unlocks the composability of agents and enables collaboration through multi-agent systems to effectively accomplish tasks. Each agent can expose endpoints in a shared interface, allowing other entities to discover the list of services it offers and the operations it is authorized to perform.
Agent Identity
Autonomous agents will operate independently and act on behalf of human entities. This paradigm shift necessitates robust accountability mechanisms. Public Key Infrastructure (PKI) is a natural solution as it fundamentally establishes a trust chain that can verify and transparently trace trust relationships, ensuring that each entity in the chain is accountable for its actions and that any violations can be easily traced. We propose the development of an enhanced PKI system that combines additional identity mechanisms to facilitate the transition to a secure era of human-machine collaboration.
The proposed Autonomys PKI derives the Auto ID of any Autonomys agent built by users from the Auto ID of the individuals and/or organizations that construct them. This system achieves secure and transparent authorization of agent behavior permissions within the Autonomys ecosystem, enabling the granting and revocation of permissions. Permissioned delegation is crucial in a world where digital employees and personal assistant agents make significant decisions and execute critical tasks for organizations and individuals.
Key features of agent Auto ID include:
- Traceability: Blockchain technology supports the tracking of agent behavior and decisions, aiding in auditing and security during AI development, deployment, and alignment.
- Delegation: Users can securely delegate permissions to AI agents, defining their roles and authorities.
- Accountability: The system maintains a clear chain of responsibility from agents to their human or organizational creators.
In summary, by allowing users to delegate permissions to AI agents; tracking the behavior and provenance of agent systems to ensure security and compliance; maintaining accountability in digital interactions; and certifying AI-generated content, Auto ID provides essential safeguards for secure and fair interactions between humans and AI, laying the trust foundation for an autonomous machine economy.
Open Collective Intelligence and Global DAO Grid
Recent developments in Decentralized Autonomous Organization (DAO) technology demonstrate its potential in resource allocation and collaborative decision-making【34】. Building on these foundations, we propose a new framework that harnesses the power of collective intelligence through a global DAO grid composed of Auto DAOs.
Collective intelligence—a form of intelligence generated through the collaboration of multiple individuals—has been utilized in DAOs for effective decision-making and governance. Auto DAOs are smaller, specialized DAOs deployed on the Autonomys network, consisting of both human and AI members, which will demonstrate the effectiveness of their collective intelligence by managing decentralized projects. Examples include web3 projects, investment funds, and research and development of open-source software. As these Auto DAOs integrate into a larger, interconnected network—the global DAO grid—a more efficient collective intelligence system will emerge.
Autonomys envisions the global DAO grid as a decentralized framework for Open Collective Intelligence (OCI), a more human-centric yet AI-enhanced alternative to artificial general intelligence (AGI). The operation of OCI involves distributed problem-solving, breaking down complex large-scale problems into smaller, manageable tasks. These subtasks are then assigned to different Auto DAOs based on their domain expertise and interest in the relevant issues. The collective problem-solving process of OCI through the global DAO grid is as follows:
- Problem Decomposition: Breaking down complex problems into independent components.
- Task Allocation: Assigning subtasks to relevant Auto DAOs within the grid.
- Parallel Processing: Members of each Auto DAO (including humans and AI) collaboratively work on their assigned components.
- Solution Aggregation: The global DAO grid aggregates solutions from each Auto DAO (potentially reaching consensus through a weighted function representing each DAO's relative expertise).
- Recombination and Synthesis: The aggregated solutions are recombined to form a holistic solution to the original complex problem.
Inspired by the Expert Mixture Network (MoE)【35】, all steps can be mediated by an AI system of agents that understand the necessary context of existing DAOs, including the expertise of their public members and previous participation records. This approach creates a distributed and scalable intelligent network capable of addressing challenges that individual persons or DAO entities cannot solve. The OCI of the global DAO grid emphasizes the synergy between humans and AI intelligence, providing a decentralized governance structure. The global DAO grid of Autonomys has the following key advantages in collective problem-solving capabilities:
- Hybrid Intelligence: Combining the strengths of human intuition and AI computational power.
- Specialization: Utilizing the unique expertise of different Auto DAOs for optimal problem-solving.
- Decentralization: Ensuring no single point of failure and promoting a truly distributed decision-making process.
- Scalability: Addressing increasingly complex problems by distributing workloads across multiple Auto DAOs.
Research directions to ensure that this global decision-making system adheres to ethical standards include optimizing task allocation algorithms to ensure fair representation, developing robust consensus mechanisms for solution aggregation, and exploring potential emergent behaviors within the global DAO grid.
Verifiable AI 3.0 Infrastructure
In our rapidly evolving technological environment, providing public infrastructure for accessible and verifiable AI is of utmost importance. Korinek and Stiglitz (2019) point out that advancements in AI technology have significant impacts on income distribution and employment【37】. Equal access to AI is crucial if we wish to maintain economic relevance and reduce the risks of inequality triggered by AI. Democratizing AI means ensuring that the benefits of these technological advancements are distributed more equitably across society. To achieve this goal, Autonomys is committed to establishing a public infrastructure that allows equal access to verifiable AI agents, tools, and resources.
A key component of this digital public infrastructure is Autonomys's dedicated distributed storage, indexing, and open-source AI data distribution directory. The primary goal of our decentralized open-source AI directory is to securely store and permanently provide a variety of valuable AI resources, including:
- Open-source AI models
- Publicly available training datasets
- Fine-tuning datasets
While providing a robust, permissionless decentralized AI model and agent building and deployment solution, the Autonomys network also protects these critical AI assets, ensuring they remain continuously accessible and permanently free from censorship or removal risks.
Subspace Protocol
The core of the Autonomys network implements the Subspace protocol【11】, a new type of storage-based consensus protocol that separates transaction ordering from execution. The Subspace protocol is designed from the ground up to achieve an open and inclusive internet by:
- Providing an energy-efficient and environmentally friendly alternative to proof of work (PoW), while allowing ordinary users to participate widely.
- Creating an incentive-compatible permissionless network that remains decentralized over the long term.
- Scaling the network's storage and computing capabilities as the number of node operators increases, without sacrificing decentralization or security.
- Connecting and enabling interoperability between existing networks.
Achieving this vision requires an alternative to resource-intensive PoW mining and permissioned proof of stake (PoS)—namely, a cryptographic proof system based on already widely distributed underlying resources that are unsuitable for dedicated hardware. Thus, we adopt Proof of Capacity (PoC), replacing computation-intensive mining with storage-intensive "farming," following the principle of "one plot, one vote." Disk-based consensus is an obvious solution, as the power consumption of storage hardware is negligible, is widely present in end-user devices, and has long been commoditized.
Subspace employs a longest-chain PoC consensus mechanism based on solid-state drive (SSD) storage. Following Nakamoto's vision, this blockchain is permissionless but has guarantees of security and liveness when the collective contribution of honest farmers' storage exceeds that of any group of attacking nodes. Essentially, Subspace follows Ethereum's fully programmable account model blockchain, periodically submitting the state of all accounts to the block header.
Unlike many existing PoC protocol designs, Subspace addresses a critical mechanism design challenge—the Farmer’s Dilemma—which poses a significant threat to the decentralization and security of PoC blockchains【11】. Rational farmers are incentivized to put all available storage into consensus while neglecting the maintenance of chain state and history【40】. This behavior leads farmers to effectively become light clients, reducing the network's security and decentralization. Ultimately, this trend could result in concentration in large farming pools, with control centralized in pool operators, diminishing the network's resistance to malicious actors. The Farmer’s Dilemma also exacerbates the Validator’s Dilemma by increasing the opportunity cost of validation【41】. If full nodes do not store chain history, new nodes must rely on altruistic archive nodes or third-party data storage for initial synchronization, leading to further centralization of the network.
Figure 4. Blockchain Data Flow
Subspace circumvents the Farmer’s Dilemma in the following ways, without sacrificing the security or decentralization of the network (see Figure 4):
- Preventing farmers from discarding chain history: We have constructed a novel Proof-of-Capacity (PoC) consensus protocol based on Proof-of-Archival-Storage (PoAS) for blockchain history. In this protocol, each farmer stores as many verifiable unique partial copies of the chain history as possible based on their disk space.
- Ensuring fairness of "one disk, one vote" in consensus: By making the drawing process computationally denser than Hellman's time-memory trade-off, we economically prevent farmers from attempting to enhance or replace storage with computation, thus blocking such behavior.
- Ensuring the availability of chain history: Farmers form a decentralized storage network that ensures the chain history can be fully restored, load-balanced, and efficiently retrieved.
- Reducing the burden on farmers to maintain the entire state and perform redundant computations: We apply classical distributed system techniques to decouple consensus from computation. Farmers are only responsible for ordering transactions, while another category of operator nodes maintains the state and computes the state transitions for each new block.
- Ensuring that executors (operators) are accountable for their actions: We adopt staking deposits, verifiable computation, and non-interactive fraud proof systems.
Archival Storage Proof
To participate in Proof-of-Archival-Storage (PoAS), farmers first create and store a provably unique partial copy of the blockchain history, then respond to random, publicly verifiable storage audits to gain the opportunity to mint new blocks. This contrasts with PoC protocols like Spacemint【41】, Chia【42】, and SpaceMesh【43】, which propose nodes storing randomly generated data rather than useful files. PoAS is inspired by Sergio Lerner's unique blockchain storage proof【38】 mechanism but is directly applied to consensus.
The PoAS protocol of Subspace aims to provide an excellent user experience (UX) while maintaining the highest consensus security. Its most relevant UX and performance metrics include:
- Setup time: Hours to days (depending on allocated disk space)
- Proof generation time: Less than 1 second
- Proof size: Less than 1 KB
- Verification time: 0.001–0.01 seconds
The latest iteration of the Subspace protocol【12】 uniquely combines KZG polynomial commitments【44】, erasure coding【45】, and function inversion【40】, addressing outstanding design challenges and significantly improving previous versions of the protocol【11】. Below is an overview of the consensus mechanism (see【12】).
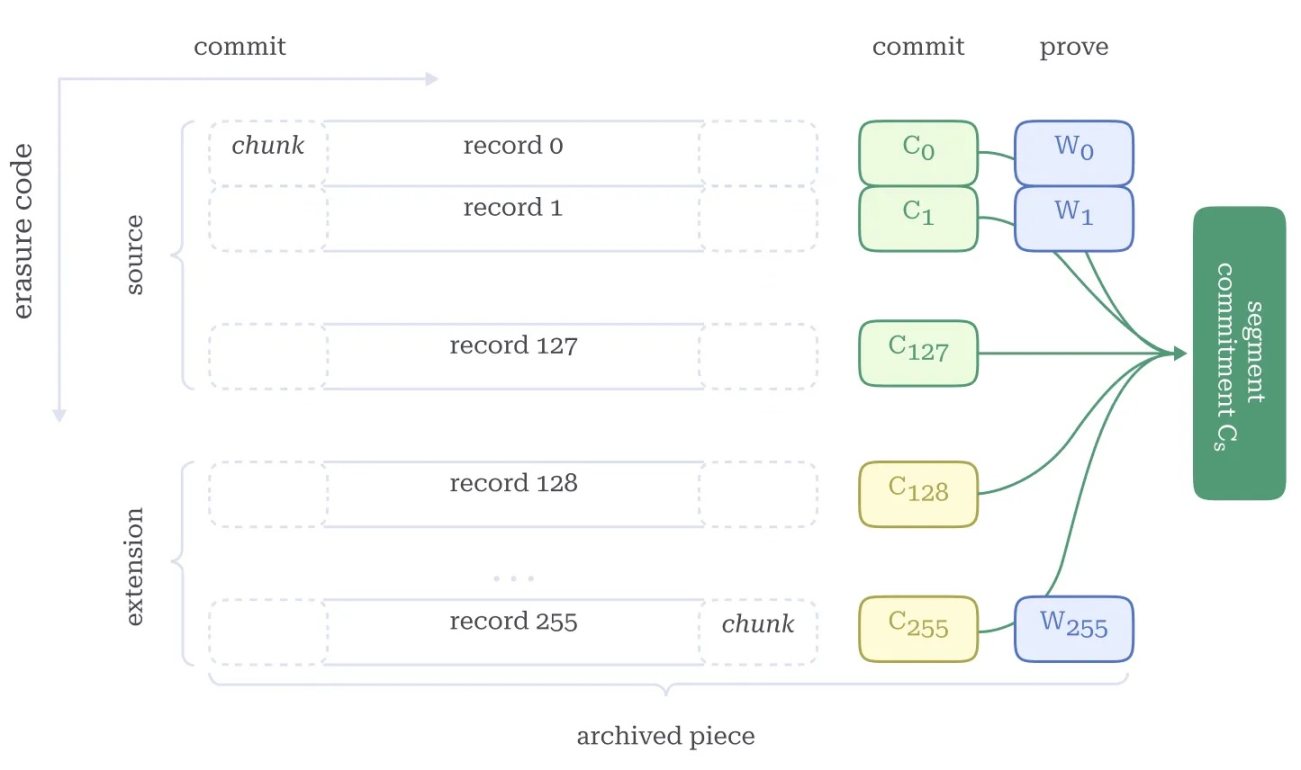
Figure 5. Archived Segments

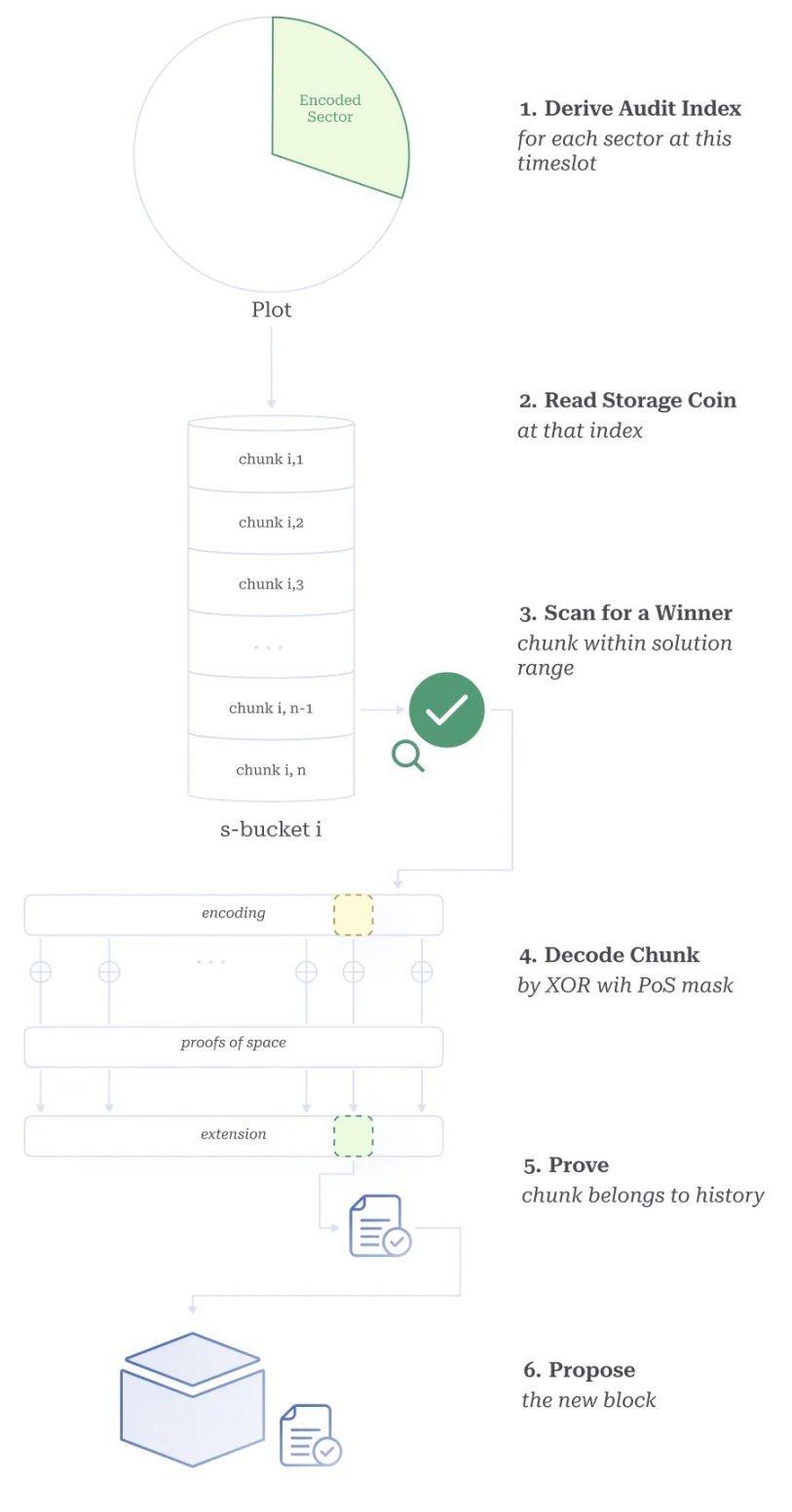
Figure 6. Farming
This process is called "farming," as shown in Figure 6. The design of farming allows for thousands of random reads of small data chunks to be executed per second, making it only operable on solid-state drives (SSDs), further enhancing energy efficiency【48】 and decentralization.
The above structure provides a leader election mechanism, combined with the longest chain protocol, forming a consensus algorithm.
Proof of Time
A vulnerability of pure PoS (and extended PoC) systems is their susceptibility to long-range attacks【48】. Unlike PoW systems, where block generation is physically limited by computational power, PoS/PoC systems lack this inherent limitation. In PoW, resources are directly consumed to generate blocks and used only once, while in PoC, the "resource" of disk space is not bound to specific blocks and can be reused across multiple blocks. Therefore, an attacker with sufficient resources could rewrite a significant portion of the blockchain history at any point in time, jeopardizing its immutability and security. This vulnerability arises from the manipulability of historical stake distribution without incurring the massive energy costs associated with PoW systems.
Moreover, PoS/PoC systems often struggle to achieve the dynamic availability and unpredictability inherent in PoW systems【49】. The key is to create a system that can adapt to fluctuating participation rates while ensuring that block proposers are unpredictable, thus preventing targeted attacks or manipulation. These characteristics are crucial for maintaining the robustness of network operations and defending against various attack vectors.
The Autonomys network addresses these challenges by implementing an independent Proof-of-Time (PoT) chain that interlinks with the PoAS chain. This design enforces a verifiable time constraint between block proposals, similar to the time arrow in PoW systems【49】, preventing long-range attacks. PoT ensures that a certain amount of physical time must elapse between each block proposal, thus preventing attackers from "rewriting history" by "backtracking time." PoT is physically constrained, similar to PoW, but its process cannot be parallelized (technically referred to as sequential work proof), meaning that even with faster hardware, attackers cannot immediately generate a successful cross-year backtrack fork.
By iteratively evaluating an inherent sequential delay function, the passage of time is guaranteed. The choice of delay function is critical to the security and efficiency of the PoT system. After extensive analysis of existing verifiable delay functions (VDFs), we chose to use repeated AES-128 encryption. This decision strikes a balance between security, efficiency, and resistance to hardware acceleration. The use of the Advanced Encryption Standard (AES) draws on its extensive history of cryptographic research and leverages hardware acceleration capabilities in modern CPUs, making it the best choice for this application. According to joint research with the hardware-accelerated cryptography lab Supranational, we do not expect significant acceleration of AES implementations even with dedicated integrated circuits (ASICs).
To maintain the PoT chain, the network introduces a new node role called timekeepers. These nodes are responsible for evaluating the delay function and propagating the output results. To provide PoT evaluations, timekeepers require high-end CPUs—most farmer nodes cannot access this. This delegation of timekeeping tasks to a separate class of nodes ensures decentralization at the consensus level while maintaining the security of the protocol, with the minimum honest participation required being at least one honest timekeeper.
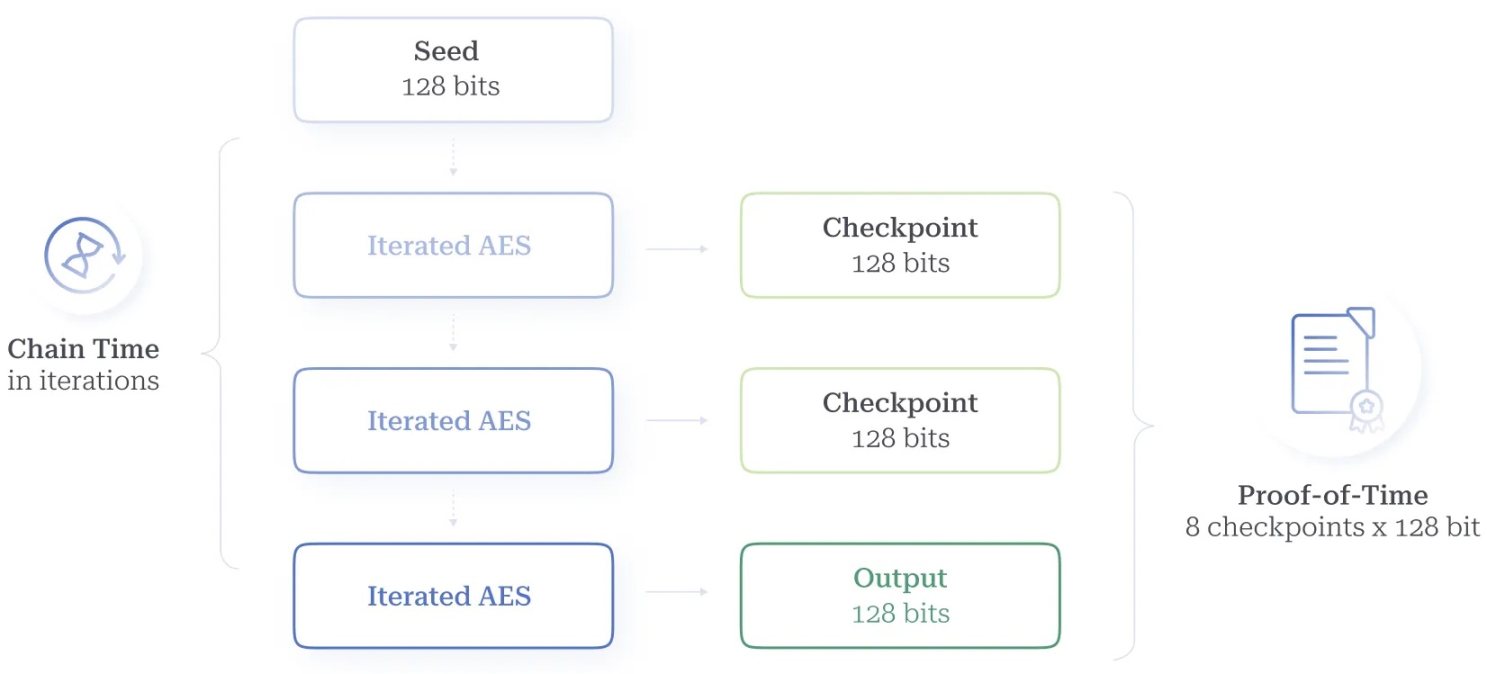
Figure 7. Proof of Time Checkpoints
To achieve asymmetric verification time based on the AES delay function, timekeepers publish a set of intermediate checkpoints—currently eight, evenly distributed—along with the output results (as shown in Figure 7). Farmers can independently and in parallel verify each checkpoint, thereby reducing the overall verification time. Including these checkpoints allows other nodes to verify approximately seven times faster than directly evaluating using instruction-level parallelism, while reducing energy consumption by about four times.
The Subspace consensus protocol utilizes a farming mechanism that mimics the dynamics of Bitcoin mining while consuming only a small amount of power. It achieves block proposal lotteries based on PoT【50】. The PoT chain serves as a random beacon, providing unpredictable and verifiable input for block challenges, thus addressing the common long-term predictability window issues in protocols using general verifiable random functions. Its unpredictability is on par with PoW protocols and even stronger than those using verifiable random functions.
The security of the PoT system is further enhanced by several key mechanisms. Sequentiality is achieved by linking the output chain between slots, ensuring that each new output depends on the previous output. To compensate for network latency, the system implements an adjustable delay parameter, allowing sufficient time for the propagation and verification of PoT outputs before block proposals. The Autonomys network also introduces measures to mitigate potential advantages from faster timekeepers, including periodic entropy injection. To prevent manipulation of randomness, the network employs an injection mechanism similar to that used in Ouroboros Praos【52】. This method prevents attackers from controlling slot challenges by strategically publishing or withholding blocks, further enhancing the system's unpredictability and security.
Distributed Storage
Subspace introduces a Distributed Storage Network (DSN) to ensure consistency of storage in the face of heterogeneous farmer storage capacities. Our DSN design ensures the following properties:
- Permissionlessness: The system operates without central coordination, taking into account the dynamic availability of farmers and the non-uniform growth of historical data over time.
- Retrievability: Supports retrieval of both complete and individual data fragments, with requests evenly distributed among all farmers, ensuring that the overhead of providing historical data is negligible.
- Verifiability: The system can efficiently verify even if farmers do not need to synchronize or retain complete history.
- Persistence: The likelihood of any single data fragment being lost, whether accidentally or maliciously, is minimized.
- Uniformity: On average, each data fragment is stored an equal number of times across the network.
These features allow historical data to exceed the storage capacity of any single farmer while enabling farmers to allocate storage resources according to their own capabilities.
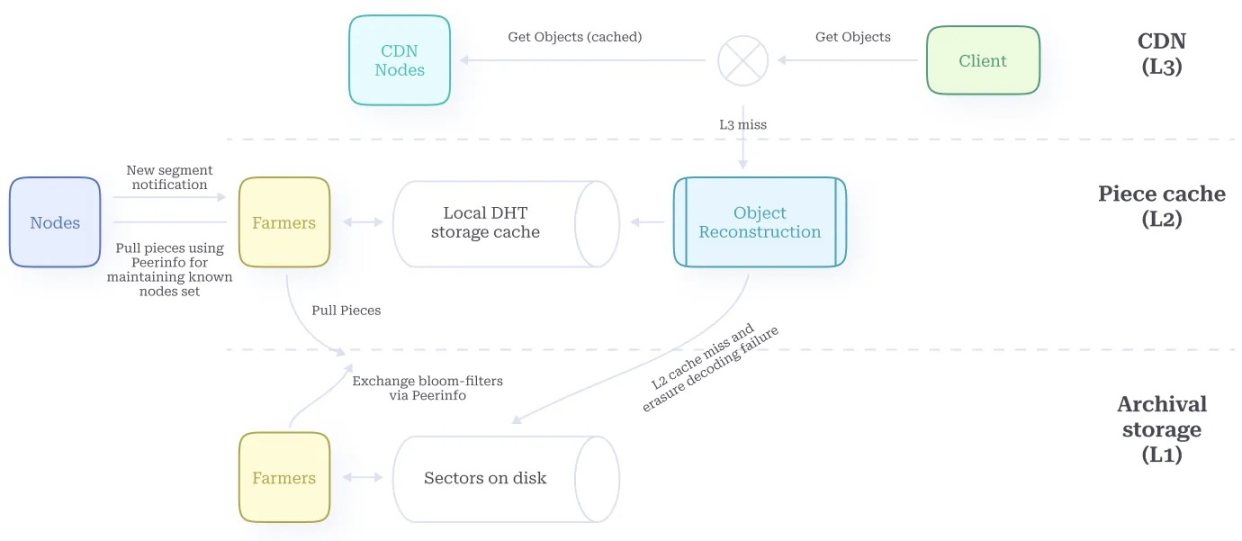
Figure 8. Distributed Storage Network
The DSN of the Autonomys network (see Figure 8) consists of multiple unique layers that collectively provide historical data fragments to requesting nodes, with each layer contributing different data availability, persistence, and efficient retrievability. This multi-layered approach aims to balance security and performance, interestingly resembling other recently independently developed data availability solutions like Tiramisu【51】.
Content Delivery Network (L3)
The top layer of the DSN is the Content Delivery Network (CDN), designed to achieve optimal performance under optimistic network conditions. The CDN layer (operated by a large network of permissioned nodes) significantly enhances retrieval speed and provides robust performance under normal network conditions. This layer offers a fast data retrieval experience similar to web2.
- Farmers upload newly created data fragments to the CDN.
- Nodes can retrieve fragments from the CDN as quickly as downloading from web2 streaming services.
- The CDN acts as a super-fast channel, passing messages between nodes to facilitate the rapid collection of data fragments.
Fragment Caching Layer (L2)
The fragment caching layer is designed to facilitate efficient retrieval of data fragments for data reconstruction and farming. Its primary function is to minimize retrieval latency. While retrieving from archival storage requires farmers to perform time-consuming computational operations—taking about 1 second on consumer hardware—retrieval from the L2 cache is almost instantaneous, as uncoded fragments are stored in disk cache.
The L2 cache uses a Distributed Hash Table (DHT) to store fragments based on the proximity of the fragment index hash values to peer IDs. Farmers are best suited to store the L2 cache, so they allocate a small portion of their assigned storage space for this purpose. The replication factor of the entire storage network determines how many times each fragment is stored.
The filling process of the fragment caching layer is as follows:
- During the archiving process, nodes generate new fragment segments.
- These new fragments are temporarily stored in the node's cache.
- Farmers receive the archived fragment index from the latest block header.
- Farmers compute the fragment index hash in the fragment segment and determine which fragments to pull into their L2 cache based on their proximity to their peer ID hash.
- The relevant fragments are then pulled into the farmer's local L2 cache.
In rare cases, if a specific fragment cannot be retrieved to the L2 cache, farmers will attempt to index request adjacent fragments and use erasure coding to reconstruct the required fragment. If this method also fails, farmers will perform L1 layer retrieval.
Archival Storage Layer (L1)
The archival storage layer is the foundational layer responsible for the permanent storage and persistence of all on-chain data. This layer consists of masked fragments committed by farmers for storing blockchain history, also known as tiles. This layer provides the highest security against powerful adversaries, but at the cost of reduced performance.
The archival storage layer ensures that historical fragments remain available in the absence of L2 cache. However, retrieving resources from archival storage is resource-intensive and time-consuming, so it is only used when L2 retrieval fails. Typically, a farmer's L1 layer is populated with fragments received from L2.
The population process of the archival storage layer is as follows:
- Farmers decide how much storage space to allocate to the network.
- Based on the committed storage amount, farmers select enough historical fragments to fill that space in a pseudo-random and verifiable manner.
- Farmers pull the selected fragments from other farmers' L2 or L1 layers.
- Farmers mask the fragments according to the drawing protocol.
- Each time a new fragment is archived, farmers check whether certain fragments need to be replaced.
The last step is necessary to ensure that new historical data is evenly replicated among many farmers in the network, regardless of how long they have participated in the network or how long ago they initially initialized the drawing. This drawing expiration mechanism is set to allow farmers to gradually replace parts of the drawing as the chain history grows. On average, when the size of historical data doubles, farmers have replaced half of the fragments in the drawing; when the size of historical data increases to four times, farmers have completely replaced the drawing once. Choosing gradual expiration instead of re-drawing the entire farm ensures maximum uptime of farmers' archival storage layers while serving the Distributed Storage Network (DSN).
Cache Types
In addition to the aforementioned caching layers, we also distinguish the following types of caches:
- Node Cache: Contains newly created fragments from the most recently archived segments. It is limited to storing the most recent segments and gradually replaces older fragments with new data.
- Farmer Cache: Contains fragments in the L2 cache, automatically filled after receiving announcements of new archived segments. Fragments are cached based on their proximity to the farmer's peer ID.
- Object Cache: Contains recently and popularly uploaded user objects and their mappings to fragments.
To incentivize the farmer network to maintain the required replication factor of historical data, Subspace implements a new algorithm that dynamically adjusts the cost of on-chain storage or block space based on fluctuations in supply and demand.
Decoupled Execution
It can be safely assumed that rational farmers will seek to invest all available disk space into consensus while minimizing computational overhead, all while maintaining the longest valid chain. This means they must compute all intermediate state transitions and maintain state. As the burden of maintaining state and computing transitions increases, the dilemma for farmers and validators arises, leading economically rational farmers to sacrifice security for lower-cost high returns, such as becoming light clients or joining trusted farming pools. To address these dilemmas, we have implemented a method that alleviates the burden on farmers while still allowing them to determine which longest valid chain is being extended. The key is that this method does not compromise the liveness, fairness, or security of block production. Our solution employs classical distributed system techniques to separate consensus from computation.
In this system, farmers are only responsible for providing subjective and probabilistic consensus on transaction ordering. Another class of execution nodes—operators—computes the objective and deterministic results of these ordered transactions. Operators are selected through a stake-based election process, separate from block production, similar to the block finalization techniques proposed by Casper FFG【52】. Operators share incentives with farmers through transaction fees and ensure accountability through non-interactive fraud proofs【53】 and slashing【54】 systems.
This approach is inspired by Flow【55】–【57】 but is simpler (using only two types of nodes instead of four) and is compatible with Nakamoto consensus, maintaining the security assumptions of "honest majority farmers" and "honest minority operators." The method is also inspired by Truebit【58】, recognizing that adopting optimistic off-chain computation with on-chain verification fallback can achieve trustless decentralized mining pools. Unlike protocols like ChainSpace【59】 and LazyLedger【60】 that achieve decoupling by delegating computation to clients, our system retains global state, allowing for cross-contract calls and application composability.
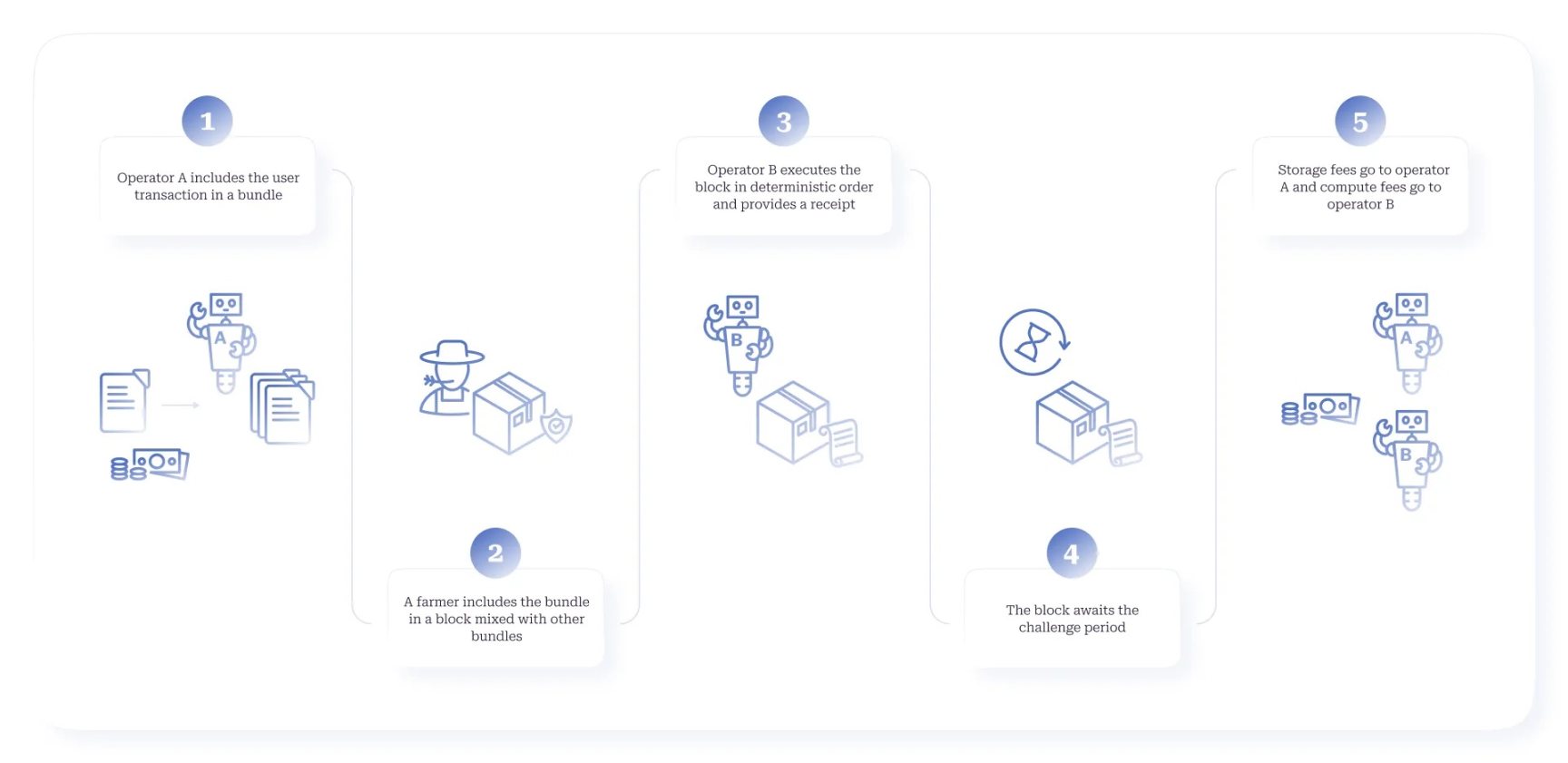
Figure 9. Domain Transaction Flow: From Submission to Fee Distribution
Under the Decoupled Execution (DecEx) framework, farmers only confirm the availability of transactions and provide ordering, while a secondary network composed of staked operator nodes executes transactions and maintains the resulting chain state. DecEx separates the probabilistic process of reaching consensus on transaction ordering from the deterministic process of executing ordered transactions, as shown in Figure 9. Decoupling these roles allows for hardware requirements tailored to different node types, keeping farming lightweight and open to participation from anyone, while providing a foundation for vertical scaling of execution (based on operator hardware capabilities) and horizontal scaling (partitioning operators into different namespace execution domains).
While conceptually similar to layer two solutions on Ethereum (like Optimism), DecEx differs significantly in protocol implementation. Unlike Ethereum, the core protocol of the Autonomys network does not have a global smart contract execution environment. Instead, DecEx (Decoupled Execution) is embedded in the semantics of the core protocol. Despite being implemented at the protocol level, DecEx can still provide a flexible system for rollup protocol designers, supporting any state transition integrity framework for verifying the receiving chain, including optimistic fraud proofs and zero-knowledge validity proofs. DecEx also supports any smart contract execution environment that can be implemented within the Substrate framework, such as the Ethereum Virtual Machine (EVM) or WebAssembly (WASM).
Domains
Domains are a logical extension of the foundational DecEx framework, expanding it from a single, monolithic execution environment to a modular, interoperable network of namespace execution environments. Each domain is its own programmable second-layer rollup or application-specific blockchain (app-chain), relying on the consensus chain for consensus, decentralized ordering, data availability, and settlement. However, a smart contract, super dApp, or agent can utilize multiple domains to accomplish complex tasks, thanks to our unique cross-domain communication.
Farmer Role
In our DecEx model, users directly submit execution transactions to operators, who pre-validate these transactions and batch them into bundles through a (probabilistic) stake-based election process. These bundles are then submitted to farmers, who treat them as base layer transactions. Farmers only need to verify the election proof and ensure data availability, then package the bundles into blocks in the usual manner. When farmers find a valid transaction ordering that meets the storage audit PoAS solution, they propose a new block with the last observed valid state root. Unlike Ethereum and most other L1s, farmers do not need to maintain the contract's code, state, or account balances; they only need to maintain a small set of balances for externally owned accounts (EOAs) and random numbers, along with minimal information about each domain's runtime, staked operators, and execution receipt (ER) chains. The farmer network effectively provides decentralized service for each domain.
Decentralized Ordering
Once the bundled transactions are included in consensus blocks by farmers, domain operators must execute them in a determined order based on a verifiable random seed from the consensus chain. This eliminates the operators' responsibility for ordering user transactions while preventing them from maximizing extractable value (MEV), thus avoiding economic harm to users. For farmer block proposers, the transactions bundled in the domain are invisible, as they do not have domain state, so farmers cannot participate in MEV extraction. The order of transactions batched by operators into bundles and the order of bundles in the consensus block do not affect the final execution order.
Operator Role
Operator nodes maintain the complete state of their respective domains and execute transactions, returning new proposed state roots. A small number of operators are elected for each new block through a stake-based election process. The executed transactions in the block are then ordered deterministically based on a unique random number generated by PoAS. Operators execute transactions in this order and generate deterministic state commitments in the form of execution receipts, gradually submitting intermediate state roots. These state commitments are then included in the next bundle, forming a deterministic receipt chain tracked by all farmers within the consensus chain protocol. The initial default implementation of DecEx adopts an optimistic fraud proof verification scheme.
Liveness
To maintain liveness in the presence of asynchronous or Byzantine roles in the network, operator elections are re-conducted in each new time slot. This allows newly elected operators to include past execution receipts (ERs) to catch up. The election threshold is dynamically adjusted based on observed operator availability. Each domain can specify the frequency of re-elections based on its needs and demand frequency without interfering with the liveness of other domains or the consensus chain.
Fairness
Fairness is maintained through a fair compensation mechanism between farmers and operators. Farmers receive block space rewards based on current storage prices and are rewarded by operators for including domain bundles in blocks. If the operator's ER is valid, the operator also receives compensation while earning their rewards through transaction fees.
Validity
Validity is ensured through a fraud proof system. During the challenge period, any honest node operating in the domain can compile fraud proofs for invalid state transitions executed by other operators in that domain. This fraud proof can be verified by any consensus node without requiring the complete domain state. If the fraud proof is valid, the operator proposing the invalid ER will have their entire deposit forfeited. Any operator extending an invalid ER will also face slashing penalties for dishonest or lazy behavior.
Finality
Transactions in the optimistic domain must wait for a challenge period before being settled on the consensus chain. During this period, nodes can question the correctness of the state transitions provided by operators. Any node that has the latest state of the domain can submit a fraud proof without needing to be a staked operator. Whether honest behavior is exhibited in this specific instance depends on the validity of the fraud proof. Currently, the challenge period for the domain is 14,400 blocks, approximately one day. For services running their own honest operator nodes, fast finality can be achieved. Since operator nodes execute all state transitions, they can determine the correctness of the domain state at any time.
Security
Security is maintained by distinguishing between illegal transactions and invalid transactions. Farmers ensure the legitimacy of transactions by ensuring they have valid signatures and can pay the specified fees, while operators guarantee validity by deterministically executing transactions in the order specified by farmers.
Network Dynamics
Our system can cope with network latency and random block production. Operators are incentivized to locally generate fraud proofs to publish their ERs as quickly as possible, thereby accelerating the propagation of fraud proofs and enhancing security. Farmers prioritize fraud proofs based on urgency and deduplicate them in their memory pool to ensure timely inclusion.
Adversarial Scenarios
The system is designed to handle various adversarial scenarios, including attacks on execution liveness or attempts to obfuscate the legitimacy of farmers' transactions. The system remains secure even when most operators are dishonest, as long as at least one honest operator exists among the peers. Operators are incentivized to reveal fraud to protect their own interests and claim their share of rewards, while they are penalized for extending invalid ERs without first demonstrating fraud.
DecEx Summary
Our decoupled execution system allows for significant scalability improvements over monolithic execution environments (like Ethereum) by independently scaling transaction throughput and storage capacity. It maintains the security properties of Nakamoto consensus even when most operators are dishonest, as long as the majority of farmers on the consensus layer are honest.
Our approach provides a unique solution to the challenges faced by storage-based blockchains, balancing between permissionless farming mechanisms and permissioned staking mechanisms. Unlike the hybrid PoC/PoS consensus mechanisms adopted by other storage-based blockchains, the Autonomys system clearly distinguishes between permissionless farming mechanisms in block production and permissioned staking mechanisms in block finalization.
By simultaneously addressing the farmer dilemma, validator dilemma, and blockchain bloat issues, the Autonomys network offers a comprehensive solution to several key challenges in the web3 industry, making blockchains more energy-efficient, fair, decentralized, and maintaining the security and functionality required for complex smart contract and application development.
Scalability
Over the past decade, blockchain scalability has received widespread attention. Numerous scalability protocols have been proposed in the literature, including Prism【61】 and OmniLedger【62】. Autonomys builds on these existing studies using a first-principles approach to scale the Subspace protocol. The following sections outline this scalability approach and its implementation.
Limitations of Blockchain TPS Scaling
For any blockchain system, there are at least three physical scaling limitations:
- Communication limitations—upload bandwidth of individual participating nodes.
- Computational limitations—the number of transactions a node can execute per second.
- Storage limitations—the number of transactions stored by each node.
The goal of blockchain scaling is to achieve the maximum possible throughput under physical constraints, measured in TPS (transactions per second).
In traditional blockchain design, a participating node (often referred to as a full node or miner) is required to download, store, and execute all transactions. This requirement imposes several upper limits. For example, throughput cannot exceed the average upload bandwidth divided by the average transaction size. Therefore, if the average bandwidth is 10 Mbit/s and the average transaction size is 250 bytes, the throughput cannot exceed 5,000 TPS, which is too small for some applications. With the massive transaction volume generated by future internet agents【63】 and the proliferation of decentralized finance (DeFi), decentralized science (DeSci), and on-chain gaming (GameFi) ecosystems, the demand for greater scalability will accelerate significantly. How do we scale the throughput of the Autonomys network to 100 times, handling 500,000 TPS?
Scaling the Autonomys Network
To achieve the target throughput of 500,000 TPS, we can increase the upload bandwidth to at least 1 Gbit/s. However, this would sacrifice decentralization, as nodes with lower bandwidth would be unable to participate. Instead, after already separating the requirements for storing and executing all transactions through the DSN and DecEx framework, we now further separate the bandwidth requirements.
Inspired by the similarities in rollup and sharding designs【64】, we propose a novel sharding method based on cryptographic sorting. Our system consists of a beacon chain and multiple data shards. The beacon chain is maintained by all farmers through the PoAS consensus algorithm. Each data shard is maintained by a portion of dynamically selected farmers through cryptographic sorting. For example, if a farmer's lottery ticket is sufficiently close to the current challenge value Ct (i.e., the distance between the ticket and Ct is less than the threshold Tb), they can be elected as the leader of the beacon chain; if the distance is not less than Tb but less than Tb+Ts, they can be elected as a member of data shard 1; if the distance is not less than Tb+Ts but less than Tb+2Ts, they can be elected as a member of data shard 2, and so on. In general, if the distance of the ticket is not less than Tb+(i-1)Ts but less than Tb+iTs, the farmer is selected as a member of data shard i. Farmers are only assigned to shards when elected, and at any time, they can be a member of at most one shard. This dynamic shard membership is recorded on-chain after farmers prove their winning tickets.
When a new domain joins, it will be assigned to a data shard. A farmer elected as the leader of that shard will download the latest block and transaction bundles, then generate a new shard block on the longest available chain. This block is shared with domain operators, the DSN, and future leaders, and its block header is broadcast among all farmers to be included in the beacon chain. This process is a variant of Nakamoto's longest chain protocol, where the majority of leaders in any shard are honest, making the security and liveness of the shard highly credible.
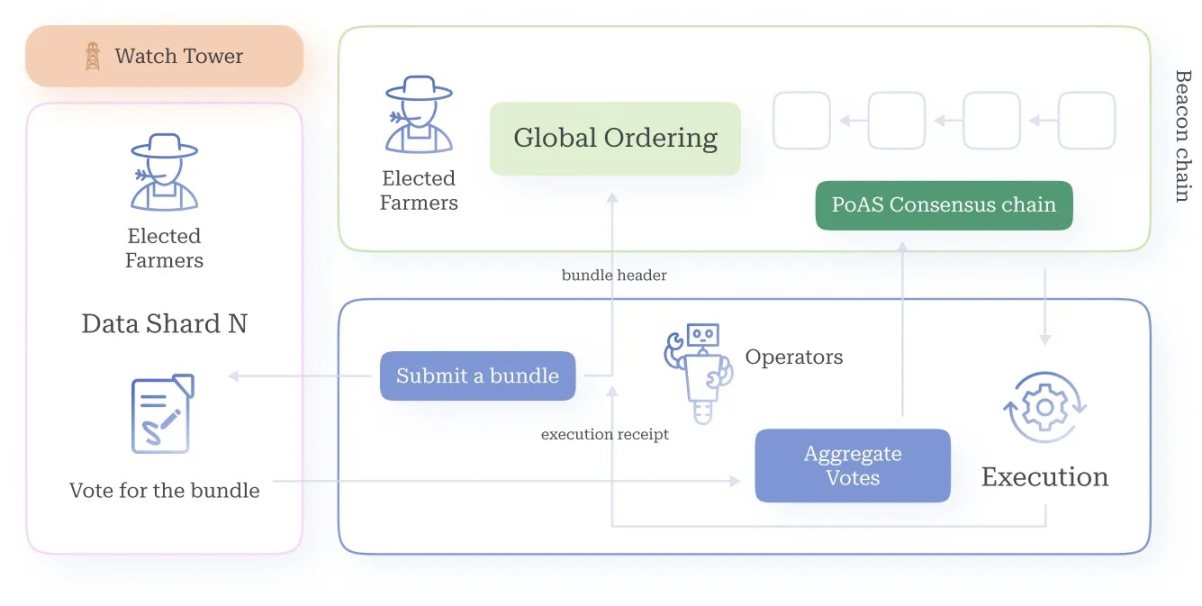
Figure 10. Domain Transaction Flow: From Submission to Fee Distribution
To address data concealment attacks, where malicious shard leaders collude with malicious domain operators, the system allows future shard leaders to detect such attacks. For rare undetected attacks, we propose an on-chain complaint mechanism similar to【66】. This workflow is illustrated in Figure 10 for a domain and shard.
Next, we propose an alternative design using cryptographic sorting and erasure coding. In this design, explicit sharding is no longer necessary. When domain operators create transaction bundles, they broadcast the block header to all farmers (to be included in the beacon chain) and propagate the erasure-coded shards. Farmers receiving the shards can vote through cryptographic sorting, with the voting data recorded on the beacon chain for data availability consensus. This design is conceptually similar to recently proposed scalability designs【67】.
Conclusion
The Autonomys network provides a dual solution addressing the following two aspects:
- The challenges of security, decentralization, verifiability, and scalability faced by web3 infrastructure—manifested as the farmer dilemma, validator dilemma, and blockchain trilemma.
- The risks and opportunities brought by the upcoming AI-enhanced world.
By implementing our state-of-the-art blockchain technology, we have built a robust decentralized system that addresses urgent issues such as permanent storage, sourcing and tracking of AI training data, and compensation, while also laying the groundwork for human and Autonomys agents to interact in a transparent, secure, and trustworthy environment through our verifiable AI3.0 infrastructure and Auto ID.
The Autonomys network stack consists of the dApp/agent layer, domain layer (DecEx), consensus layer (PoAS), and storage layer (DSN), forming a complete ecosystem that provides unprecedented scalability, security, and flexibility for AI and dApp developers. Our permissionless peer-to-peer network allows for broad participation, while the archival storage proof consensus mechanism of the Subspace protocol ensures efficient and environmentally friendly operation. The modular architecture of the Autonomys network, through distributed storage networks and decoupled execution domains, offers unparalleled scalability and adaptability. Our design allows for seamless integration of various state transition frameworks and execution environments, promoting interoperability and innovation across different blockchains.
Key innovations Auto ID and Auto Score provide a secure, verifiable identity system for humans and AI entities, helping to address the fundamental challenge of building trust in an increasingly integrated AI world while allowing for content verification and permission delegation.
While driving innovation and growth in the fields of AI and blockchain, we aim to empower individuals with autonomy over their digital identities and economic relevance, ensuring that the benefits of technological advancement are accessible to all, regardless of their resources or backgrounds. We envision the Autonomys network as a fair, open-source, and collaborative foundational layer for AI3.0—a system that supports accessible, verifiable, and secure dApp and decentralized AI (deAI) development, deployment, and interaction.
Acknowledgments
The authors thank Tianyu Shi and Saeid Yazdinejad (University of British Columbia) for their contributions to the scalability roadmap; Barak Shani for contributions to the security of the Subspace protocol; Jianming Liu for coining the term "AI3.0"; the Autonomys Lab team, especially Jeremy Frank for contributions to Auto ID, and Chris Sotraidis and Charlie McCombie for their valuable feedback.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








