Original Author: Fu Shaoqing, SatoshiLab, Bihelix, Wanwudao BTC Studio
Reading Notes:
(1) This article is somewhat obscure because it involves some underlying principles of the system, and the author himself has limited theoretical and practical experience in distributed systems. General readers can directly read the conclusion, which is the architecture of the large-scale application of web3.0 in section 3.3.
(2) For the classification of second-layer construction, refer to the article "A Comprehensive Understanding of the Basic Knowledge System of Bitcoin Second-Layer (Layer2) Construction". According to the system structure classification in the reference article, Bitcoin Layer2 is divided into three types: blockchain-like structure, distributed system structure, and centralized system structure.
(3) Observing Bitcoin's second-layer construction from the perspective of a state machine will reveal that the principles of the state machine apply to all three system structures (blockchain system, distributed system, centralized system), but the implementation is limited by the structure of the system.
(4) Three observation perspectives: distributed ledger, state machine, block + chain structure
Introduction to Multilevel and Multidimensional Analysis
Observing things from multiple levels and perspectives belongs to the methodology of comprehensive analysis. Its advantages are reflected in several aspects: comprehensiveness, in-depth understanding, comprehensiveness, accuracy, and facilitation of execution. The advantages of the methodology of comprehensive analysis make it have strong application value in complex and changeable problems, providing more comprehensive, in-depth, and accurate analysis results, and providing strong support for problem solving and development.
(1) Multilevel
Multilevel analysis generally can adopt macro, meso, micro, or can be observed from the perspective of time periods, using short-term, medium-term, and long-term levels. In the development of the Bitcoin ecosystem, by observing from the short-term, medium-term, and long-term perspectives, we can gain a more comprehensive, in-depth, and accurate understanding of the Bitcoin ecosystem.
Here, borrowing from the summary of Mr. Dashan: "The Bitcoin ecosystem is divided into short-term, medium-term, and long-term opportunities: the short-term opportunity of the Bitcoin ecosystem is represented by BRC-20; the medium-term opportunity is the Bitcoin Layer2 track and Nostr plus the Lightning Network track; the long-term opportunity is the off-chain solution track represented by the RGB protocol and BitVM. This includes four tracks, the inscription track; the Layer2 track; the Nostr plus the Lightning Network track; the off-chain track (represented by RGB and BitVM)."
In section 3.4 of this article, the preliminary stage of the Layer-based chain-based second-layer construction is also included in the short-term opportunity, the reason for which is introduced in section 3.4.
(2) Multidimensional
At the same time, for the Bitcoin ecosystem, observing from multiple perspectives can bring comprehensive, objective, in-depth, flexible, and innovative advantages. This multidimensional observation helps us to better understand and comprehend things, and is conducive to innovation.
From a business perspective—distributed ledger (beneficial for understanding business), abstract computing perspective—state machine (beneficial for understanding the implementation of blockchain + distributed systems), technical implementation perspective—block + chain structure (beneficial for understanding the blockchain part in the ecosystem).
1. Three Observation Perspectives
In the Ethereum document "EthereumEVMillustrated", three observation perspectives for the block structure of Ethereum are introduced (distributed ledger, state machine, blockchain). This kind of observation is also applicable to Bitcoin, and is more suitable for observing the architectural structure of the Bitcoin ecosystem. In the following introduction, we will have different gains from understanding from these three perspectives.
From the perspective of a state machine, not only is it easy to understand the state and state processing on the blockchain, but we will also more easily understand the state, state channels, state transitions in the distributed system, and combined with the structure of the distributed system, it will be easier to understand the routing problem and the requirements of the directed acyclic graph for state transitions. The state machine is based on the underlying abstract computing principles of graph theory, based on these principles and specific implementation structures (blockchain, distributed, centralized), we will understand the specific problems that need to be solved and the train of thought for the solutions.
Secondly, from a business perspective, we will easily understand why blockchain can process trusted data, why data on the blockchain can be used as digital currency, making the blockchain system more like a ledger. We will understand why distributed systems are not ledgers and need to cooperate with ledgers. At the same time, we will understand how distributed systems handle data and circulation on the ledger in cooperation with the ledger.
From the perspective of technical implementation, we will understand that the Blockchain system is a block chain structure, and the advantages and disadvantages of this technical structure can be easily summarized.
For the structure of the Bitcoin ecosystem, from the perspective of ledger and state machine, we can better understand the advantages and disadvantages of each structure, and how to use the three optional structures to build the second layer of Bitcoin, and even the entire architecture of building Web3.0 applications.
When reading the Ethereum document "EthereumEVMillustrated", I had a feeling. Observing Ethereum from three different perspectives can provide some thinking and processing experience references for solving Ethereum. For example, when Ethereum is seen as a state-based automaton, the theory and algorithms of state machines in the computer field can be used for Ethereum through transformation. When Ethereum is seen as a ledger-based database, some theories in the database can be used for Ethereum—such as the sharding idea in the database. This feeling is also applicable in the Bitcoin ecosystem and will be used in the three major system structures, making it more flexible.
1.1. Business Perspective—Distributed Ledger
From the perspective of a ledger, a blockchain is a group of transactions, just like data written on a page of a ledger.
From the perspective of a ledger, we can easily understand its business capabilities, and therefore more easily understand its role in currency and finance. This is also a necessary role in the overall architecture of Web3.0 applications.
From the perspective of a ledger, we can also understand the second-layer construction of the chain. The accounts of different businesses can be recorded on different ledgers, and these sub-ledgers can be summarized into the general ledger.
From the perspective of a ledger + distributed system, we can understand that when giving a digital currency to the participants, how to handle it and how to settle accounts can be negotiated by the participants themselves, and then recorded in the ledger.
1.2. Abstract Computing Perspective—State Machine
Here we will introduce the state machine in detail, because this perspective can help us understand the blockchain system and distributed systems very well. It can also help us understand the differences in data (or state) processing between the blockchain system and the distributed system.
From the perspective of the state, the blockchain is a transaction-based state machine. A transaction is a triggering condition that causes an original state σt to transition to the next state σt+1.
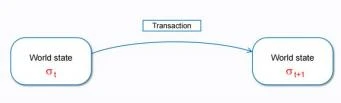
A set of transactions packaged into a blockchain is a data packet that causes the states associated with this data to change.
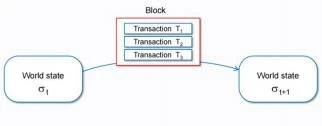
So from this perspective, the blockchain is a state chain (in a distributed system, it is a state channel). From the perspective of the state, the blockchain system can be seen as a state-based automaton.
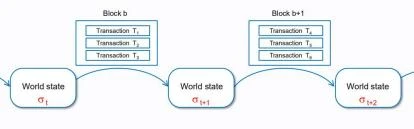
From the perspective of the state, observing the blockchain + distributed system will make it easier to understand the rules for the transmission and change of states in the two systems, as both systems are based on state-based automata.
When we consider blockchain as a state-based automaton, the theory and algorithms of state machines in the field of computer graph theory can be applied to blockchain. Similarly, if the implemented technical structure is not a blockchain structure but a distributed structure, we can also use the theory of state machines. Technologies such as Directed Acyclic Graph (DAG) (to avoid double spending), state channels, and one-time sealing are all used in distributed systems to handle state processing.
1.3. Technical Implementation Perspective—Block + Chain Structure
From the perspective of technical implementation, systems like Bitcoin and Ethereum are based on a blockchain. Data blocks and the hash pointers inside them link dispersed data together.
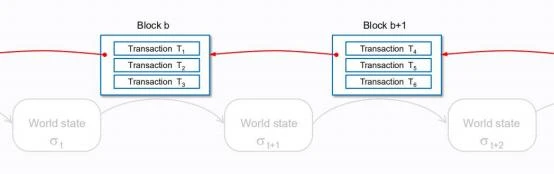
This is just one technical implementation structure to operate systems like blockchain. The data and computations on the blockchain are done globally, and only this structure can fulfill the function of a ledger. When connecting with external systems, the implementation details and applicability of this structure need to be considered.
With this block + chain technical implementation structure, we can easily understand its characteristics and calculate performance metrics. For example, the block size of the Bitcoin network is 1MB (the theoretical maximum after SegWit is 4MB), and the supported number of transactions can be calculated.
The calculation formula is: (block size / average transaction size) / average block interval. In general, Bitcoin can accommodate approximately 2000-3000 transactions per block, which translates to 3-7 TPS.
1.4. Basic Characteristics of Blockchain and the Characteristics of Three Layer2 Construction Structures
Referring to the three classifications of Bitcoin's second-layer construction: blockchain-like structure, distributed system structure, centralized system structure. By comparing the basic characteristics of Bitcoin's first and second layers, we can clearly see the differences between them. As shown in the table below. Later, in conjunction with the application requirements in section 3.2, it will be easier for us to select a suitable architecture from these basic system structures.
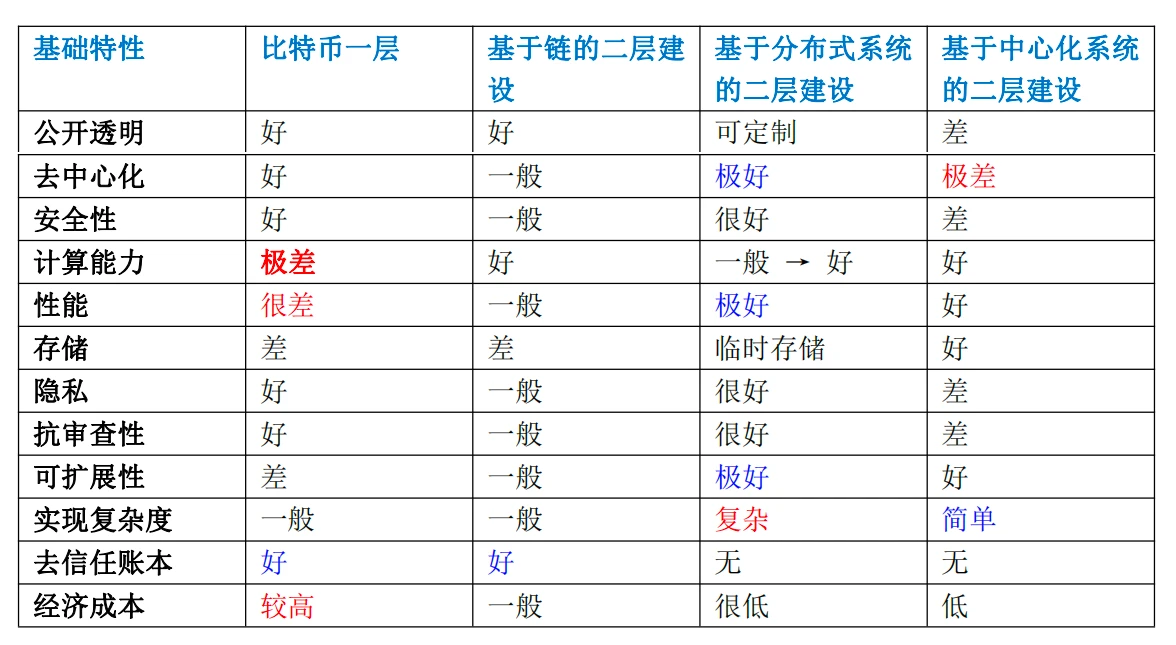
From the table, we can roughly summarize the characteristics of blockchain structure, distributed system structure, and centralized structure.
(1) Blockchain Structure
The biggest advantage of the blockchain structure is solving trust-related issues and being able to record the data change process (state transition). Therefore, data and computational rules become trusted data and trusted computation. These trusted data include basic raw data (represented as currency) and a set of instructions for processing data (represented as code and smart contracts).
The biggest problem with the blockchain structure is poor performance, for two reasons. First, the blockchain structure cannot handle scenarios where partial computation is needed, as it processes all requests through full computation. For example, partial computation vs. global computation, local data vs. global data, temporary data vs. permanent data. Second, the blockchain structure has a clear performance limit. If second-layer expansion is done through a chain, the supported number of transactions is also very limited. A simple calculation is as follows:
The upper limit of a blockchain system is the maximum number of transactions that can be accommodated in a single block, and the upper limit of a multi-level blockchain is the product of the number of transactions in each layer. For example, if Bitcoin processes 7 TPS per second, and a second-layer chain has a processing capacity of 100 TPS, then the combination of these two structures would be 700 TPS.
To improve the performance of a blockchain structure, multi-layer construction is needed, and it needs to be combined with heterogeneous systems. For work that must be completed in a blockchain system, only data that needs to be globally saved and computed needs to be recorded, while other non-global data can be allocated to other layers for processing, to ensure that the processing of data and code is as closely related to relevant parties as possible.
From the table, only the blockchain structure can achieve the function of a trustless ledger, so if a system wants to achieve the function of a trustless ledger, it must include a blockchain system. However, the performance requirements of large-scale applications make it necessary for a blockchain system to be combined with other systems to meet the demand.
(2) Distributed System
In the table, we can see the obvious advantages of distributed systems: decentralization, performance, and scalability are all excellent, but they have relatively complex characteristics in terms of functionality. In addition, distributed systems do not have the ability to provide a trustless ledger.
Therefore, if we can use a distributed system in the second-layer construction based on the ledger function of Bitcoin's first layer, theoretically, we can achieve unlimited performance expansion while maintaining the basic characteristics of the blockchain. A representative case in this regard is the combination of Bitcoin and the Lightning Network, which would result in a performance of 7 TPS * ∞.
The reason for implementing Turing completeness in distributed systems is that the cost of recording and running smart contracts in a blockchain system is high, as it involves global data and global code. Therefore, smart contracts are also suitable for layered theory, with the storage and execution of smart contract code limited to participants. This is also the scenario where client-side verification in distributed systems occurs, where only trusted data (state, one-time sealing) among relevant parties is involved in computation, and Turing complete computation is only done locally. This is what is commonly referred to as the difficulty of building a second layer using a distributed system structure, as the technical implementation complexity is quite large. Networks like the Lightning Network, which solely address payment issues, have developed slowly and have many imperfections. Implementing Turing complete computation in a distributed system presents an even greater challenge. The slow development and slow version updates of RGB are a reference case.
The biggest cost of solving complexity is the increased likelihood of security issues and the high development threshold. Implementing Turing complete smart contract functionality in a distributed system not only has a long development cycle and high development difficulty at the platform level, but also often leads to contract code vulnerabilities and ongoing hacker attacks.
(3) Centralized System
In the table, we can see that the advantage of a centralized system is relatively simple engineering implementation, due to its simple internal logic control and computation. Similarly, a centralized system also does not have the ability to provide a trustless ledger. The advantages of a centralized system are not prominent, and it is relatively more suitable for handling small-scale data or temporary data and computations.
The second-layer construction of a centralized system can serve as a complementary or transitional solution for the other two methods.
(4) Comprehensive Analysis
In the era of value, through the above content, we can see that it is difficult to meet the requirements by relying solely on one system. This is also a practical requirement for the development of the second layer in the Bitcoin ecosystem. However, the combination of these three systems requires a lot of exploration. We first analyze it theoretically, and in the face of different requirements, there will be different combinations of structures.
First, from the perspective of protocol layering design, the Bitcoin network does not really need Turing completeness. It is a global trust machine that only needs to store the data that needs global trust and the trajectory of data changes. Based on this most basic requirement, the instruction set of Bitcoin can be minimized. Other functions are left to upper-layer extensions to complete. In addition to meeting the requirements of this layer, the further development and improvement of the connection technology between the first layer of Bitcoin and upper-layer networks is needed. This connection technology should occupy as little Bitcoin data space as possible while meeting the functional requirements.
For general small-scale applications, completion on a single blockchain is sufficient. For slightly larger systems, completion on a blockchain + blockchain second-layer construction is suitable. However, for large-scale applications, the preferred solution is to use a blockchain system + distributed system. From a performance perspective, the upper limit of a distributed system is theoretically unlimited, so this combination would be 7 TPS * ∞ for Bitcoin. In engineering implementation, there will be limitations due to specific factors. Typically, the upper limit of such a system is limited by the routing capacity of the distributed system, the processing capacity of the directed acyclic graph of state changes, and other specific technical implementation details. Later, in typical application architectures of Web3.0, we can also see diagrams of various system combinations.
Through the combination of various system structures, the limitations of a single system's basic theory can be overcome. For example, the blockchain system is limited by the impossibility triangle of DSS, but if a blockchain system + distributed system is used, it can solve the impossibility triangle of decentralization D, security S, and scalability S. Other combinations, such as blockchain + centralized system, can also to some extent solve the scalability problem. A distributed system + centralized system can solve the limitations of the CAP triangle in a distributed system.
In the history of technological development, there have been cases of combined usage. For example, when centralized databases are limited in capacity, they adopt a master-slave structure, then sharding, and eventually a distributed database, which is an example of using both centralized and distributed systems.
This combination also reflects a philosophical idea: the solution to a problem cannot be found at the level where the problem arises, but it can be resolved at a higher level. Understanding this statement is not particularly easy. I recall a metaphor from "Zen and the Art of Motorcycle Maintenance": "We can't pull ourselves up by our own hair." This tells us that we cannot rely on the system itself to solve its own problems; we definitely need to rely on external systems to solve them.
2. Re-examining the Design and Development of Bitcoin's Second Layer from the Perspective of a State Machine
States and state machines exist in all three second-layer constructions, but they are named differently, which causes most people to overlook this observation angle.
When we look at it from the perspective of states and state machines, all three second-layer structures are state machines that handle states, with slightly different principles. When these three systems are used in combination, it is necessary to ensure that the concept of "state" is consistent across the three systems, and that the state machine of each system can handle state changes without compromising state consistency.
In the application architecture of the Bitcoin ecosystem or Web3.0, from the perspective of a state machine, it is a combination of these systems to handle state transitions and thereby complete the processing of business logic.
Using this state machine approach, when we look at the construction of Bitcoin's second-layer network, we can see that each layer of the architecture has a division of labor suitable for its characteristics.
2.1. Basic Knowledge of States and State Machines in Graph Theory
In graph theory, the basic knowledge of states and state machines includes the following:
State: A state refers to a node or vertex in graph theory. In a directed graph, a state can be represented as a node; in an undirected graph, a state can be represented as a vertex.
State Transition: State transition refers to the process of moving from one state to another. In a directed graph, state transition can be represented as a directed edge; in an undirected graph, state transition can be represented as an undirected edge.
State Machine: A state machine is an abstract computational model used to describe a series of states and the rules for transitioning between states. A state machine consists of a set of states, an initial state, a transition function, and terminal states.
Directed Graph: A directed graph is a graph structure composed of vertices and directed edges, where a directed edge points from one vertex to another, representing the transition relationship between states.
Undirected Graph: An undirected graph is a graph structure composed of vertices and undirected edges, where an undirected edge connects two vertices, representing the relationship between states.
Topological Sorting: Topological sorting refers to the linear ordering of vertices in a directed acyclic graph (DAG), such that for any two vertices u and v, if there is an edge (u, v), then u appears before v in the ordering.
Directed Acyclic Graph (DAG): A directed acyclic graph is a directed graph in which there is no cycle that can be reached from any vertex by following the edges.
Shortest Path: The shortest path refers to finding the path with the smallest sum of edge weights that connects two vertices in a graph.
Minimum Spanning Tree: The minimum spanning tree refers to finding a tree that includes all vertices in a connected graph, such that the sum of the weights of the tree's edges is minimized.
These fundamental concepts in graph theory are used to describe and analyze the relationships between states and the rules for transitioning between them. Further study of related knowledge and diagrams can be found in professional books.
Although these concepts may seem abstract and dry, it is easy to understand them when we translate them into some commonly encountered blockchain concepts. For example, the requirement for a directed acyclic graph is to avoid double spending; one-time sealing transforms the state in a blockchain into a state in a distributed system; routing algorithms calculate the shortest path in a distributed system; finding the minimum cost route in the Lightning Network is a minimum spanning tree problem; client-side verification can also be seen as a form of state machine.
2.2. State Machines and Distributed Systems
Here, we will use several distributed networks to illustrate:
(1) In the Lightning Network
In the Lightning Network, the following knowledge points related to states and state machines are evident:
The Lightning Network is a second-layer solution for Bitcoin based on state channel technology. Payment channels in the Lightning Network are bidirectional state channels, allowing participants to conduct multiple transactions within the channel and achieve fast, low-cost payments through updating channel states.
Transactions (i.e., states) in the Lightning Network are implemented using Hash Time-Locked Contracts (HTLC), allowing participants to lock funds using this contract (transferring states between the Bitcoin and Lightning Network systems) and conduct secure transactions within the channel (simple state processing).
Routing in the Lightning Network: To enable cross-channel payments, the Lightning Network uses a mechanism called routing, allowing participants to find a trusted path for payments.
Relay nodes in the Lightning Network: Relay nodes are nodes that can forward payment requests, helping to facilitate cross-channel payments.
Bidirectional payments in the Lightning Network: The Lightning Network allows participants to make bidirectional payments within payment channels, enabling both sending and receiving payments.
Payment privacy in the Lightning Network: Since transactions in the Lightning Network occur within channels and do not need to be recorded on the blockchain, it can enhance payment privacy.
Limitations of the Lightning Network (mostly related to the implementation of state and state machine technology): The Lightning Network still has some limitations, such as channel liveliness and fund lock times, which need to be considered comprehensively when designing suitable payment channels.
(2) In RGB, the following knowledge points related to states, state machines, and state channels are evident:
RGB is based on the LNP and BP protocols. There is a discussion about whether RGB is a second or third layer. If it directly extends the Turing complete functionality of Bitcoin based on BP, it belongs to the second layer, with limited performance expansion. If it operates RGB based on LNP, it belongs to the third layer (because LNP is the second layer of Bitcoin), which can expand both performance and Turing complete computational capabilities, albeit with a certain level of technical complexity. Typically, a combination approach can expand computational capabilities, performance, and reduce implementation complexity.
RGB is based on state channel technology from Bitcoin or the Lightning Network. State channels in RGB refer to bilateral or multilateral communication channels built on LNP and BP, allowing multiple transactions and state updates within the channel, reducing the number of transactions and fees on the blockchain.
State channels in RGB use multi-signature scripts based on Bitcoin to lock funds and use special transaction types to update the channel's state.
State channels in RGB can be applied to various scenarios, such as payment channels, decentralized exchanges, and asset issuance, improving transaction efficiency and user experience.
State channels in RGB achieve payments and asset transfers through updating channel states, with transactions within the channel not needing to be written to the blockchain, with only the final state being written to the blockchain.
State channels in RGB can also achieve more complex functions, such as atomic swaps, payment routing, etc., through smart contracts and multi-signature scripts.
State channels in RGB can be combined with other technologies and protocols, such as the Lightning Network, LNURL, etc., to provide richer functionality and a better user experience.
The design and implementation of state channels in RGB need to consider factors such as security, privacy, and scalability to ensure the reliability and availability of the system.
(3) In Nostr, concepts related to states, state machines, and state channels.
In Nostr, because information is being transmitted, the concept of state (trusted data, digital currency) and state machines has not been reflected yet. However, I believe that with a slight modification, Nostr, as a distributed structure, can be transformed into a system similar to the Lightning Network, which can not only transmit information but also transfer value. In section 3.3 of the Web3.0 application architecture diagram, the possibility of the gradual transformation of information-based distributed systems into distributed systems that include value processing is also described.
Currently, a brief introduction to Nostr: There are two main components in Nostr, the client and the relay. Each user runs a client to communicate with the relay and others. Each user is identified by a public key. Each post published by a user is signed, and each client verifies these signatures. Clients retrieve data from the relay they choose and publish data to the relay they choose. The relays do not communicate with each other, only directly with the users.
(4) In distributed systems, knowledge related to state machines includes:
State Machine Model: A state machine is a mathematical model used to describe the transition and behavior of a system between different states. In distributed systems, the state machine model is commonly used to describe the behavior of the system and state changes.
Finite State Machine (FSM): A finite state machine is the most basic state machine model, consisting of a set of finite states and a set of transition rules between states. In distributed systems, a finite state machine can describe various states of the system and transitions between states.
State Transition: State transition refers to the process of the system moving from one state to another. In distributed systems, state transitions may be triggered by various events or conditions, such as receiving messages, timeouts, etc.
Behavior of State Machines: State machines can define different behaviors in different states. In distributed systems, the behavior of state machines may include message processing, execution of operations, sending messages, etc.
State Consistency: In distributed systems, multiple nodes may have different states. State consistency refers to maintaining the coordination and consistency of states among nodes in the system.
Distributed State Machine (DSM): A distributed state machine is a technology that applies the state machine model to distributed systems. It distributes the states and state transitions of the system across multiple nodes and ensures consistency between the states of the nodes.
Atomic State Machine (ASM): An atomic state machine is a state machine that maintains atomicity during state transitions. In distributed systems, an atomic state machine can ensure the consistency and reliability of the system during state transitions.
Consensus Protocol: A consensus protocol is a protocol used to ensure state consistency in distributed systems. Common consensus protocols include Paxos, Raft, ZAB, etc.
Fault Tolerance: Distributed state machines need to have fault tolerance, ensuring that the system can maintain correct states and behavior in the event of node failures or message loss.
Scalability: Distributed state machines need to be scalable, maintaining efficient state transitions and consistency as the system scales.
2.3. State Machines and Blockchain Systems
According to Ethereum's document "EthereumEVMillustrated," each block is a set of triggered states, and the entire Ethereum system is a state processing machine. In section 1.2, we introduced the content of state machines in blockchain systems. The Ethereum whitepaper also contains many descriptions of state machines.
Although state machines have strong processing capabilities, they are limited by the structure of the blockchain.
For blockchain applications based on the UTXO model and account-based model (similar to EVM), the implementation of states and state machines differs significantly. Blockchain based on the UTXO model is relatively easy to integrate with distributed systems because the states in both systems are based on UTXO, with no or only simple transformations required. On the other hand, for chains based on the account model, further encapsulation and transformation of states between the blockchain and external distributed systems are needed, leading to complexity in implementation. This is also part of the reason why the development of the Lightning Network on Ethereum has not been smooth.
2.4. State Machines and Centralized Systems
Examples of using a combination of blockchain and centralized systems include Ordinals and centralized exchanges (CEX).
These systems are relatively simple, with some fundamentally non-existent state transfer. For example, in the case of Ordinals, statistical work is solely completed using centralized indexing.
In centralized exchanges, the state transfer within them relies entirely on the rules set by the centralized system, and the state machine within them is a state processing machine composed of the centralized system's program, without complex concepts.
In the future applications of Web3.0, there are likely to be more cases of using a combination of blockchain and centralized systems.
3. What Should the Structure of Web3 Applications Look Like
From the content of the article, we know that a more complex structure can be designed through the combination of the three Bitcoin second-layer architectures to meet the required feature demands. From a business perspective, if the underlying logic of an application can be decomposed into states and state machines, a combination of the three systems can be used to complete the entire business logic at the upper level.
So, what are the common combinations, and what factors determine the structure of the combination? We can speculate on the structure that meets the needs of large-scale Web3.0 applications based on common application classifications and application requirements.
3.1. Common Application Classifications
We refer to the application statistics in the 48th "Statistical Report on the Development of China's Internet" for reference. Because Web2.0 has matured and does not affect the results of the analysis of application classifications and user scale, we use old data from 2020 and 2021. It is important to note that this is only the statistical data of the Chinese Internet. In the Web3.0 stage, many applications are global, with higher user scale and performance requirements.
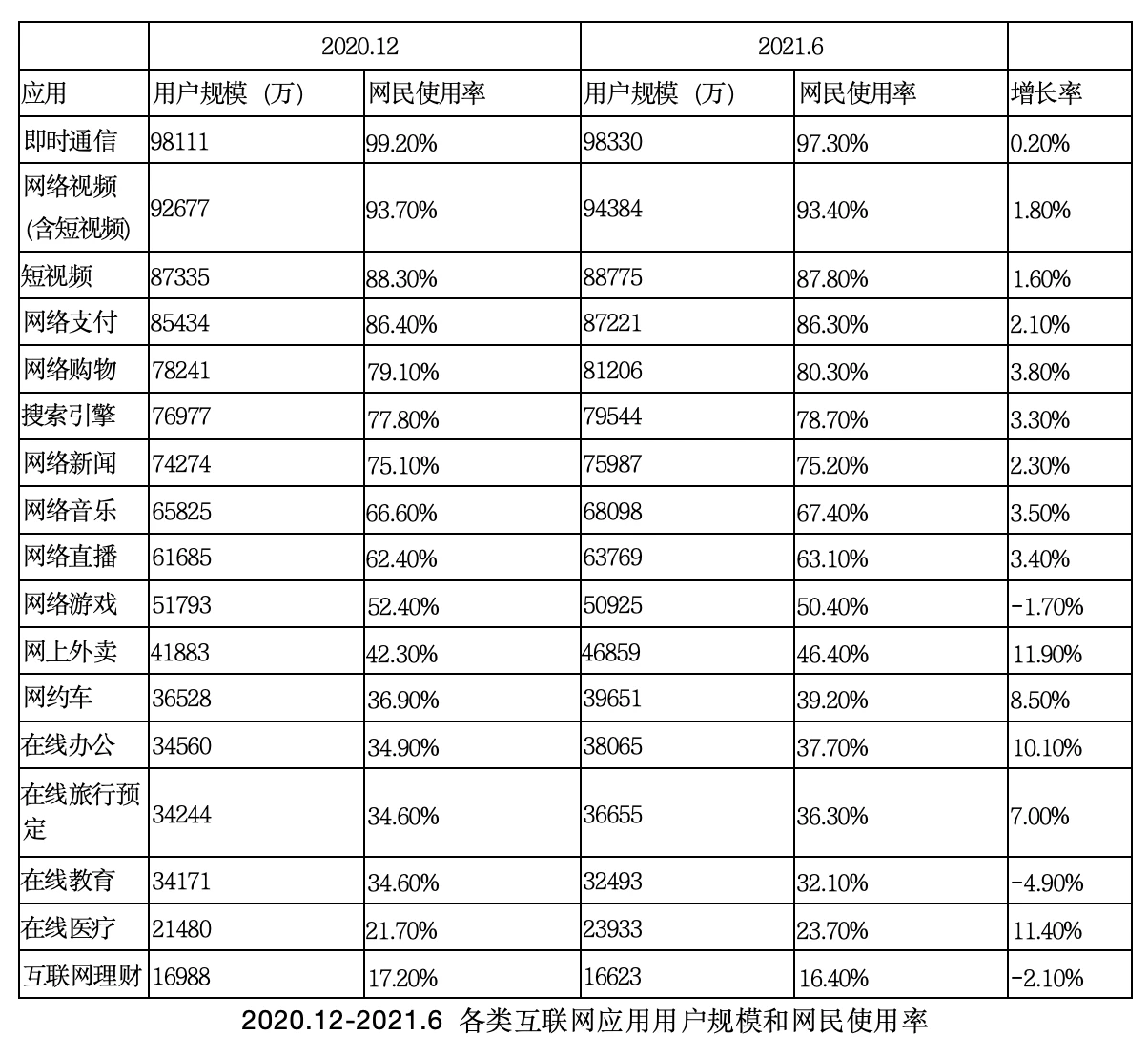
In the statistical report, we can see that the applications in Web2.0 are already very diverse and have a huge user base. These applications include instant messaging, online video, short videos, online payments, online shopping, search engines, online news, online music, live streaming, online gaming, online food delivery, online literature, online ride-hailing, online office, online travel booking, online education, online healthcare, etc., covering almost all aspects of people's lives. In addition to these consumer internet contents, there are also many applications in the industrial internet.
If all Web2.0 applications were to migrate to Web3.0, the performance requirements for the vast majority would be very high. Taking Visa payments as an example, the peak performance demand is 65,000 TPS, a performance metric that only distributed systems can support. For example, the Lightning Network currently achieves 40 million transactions per second, and the performance of the Lightning Network theoretically has no upper limit.
Furthermore, taking common games as an example, the highest TPS of a full-chain game on the blockchain can reach a peak of around a few thousand TPS, which is a huge gap compared to the traditional Web2 3A games with TPS in the tens of thousands. If all games were to be migrated to Web3.0, the infrastructure performance required would be a significant challenge.
Moreover, games are just one type of application in the common application classifications, and there are many other performance and specific requirements for other applications.
3.2. Requirements of Web3.0 Applications
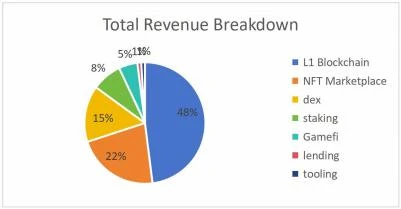
Understanding the requirements of applications, using revenue structure as an indicator would be more direct. We refer to the "TokenTerminal, curated by FutureMoneyResearch 2022 Q2" report, which, although slightly earlier, still represents the core product composition of current Web3.0. As shown in the figure.
1) Layer1 (the basic main chain in blockchain) accounts for 48% of the revenue, nearly half of the total revenue, and its business model can be understood as "selling block space";
2) NFT trading platforms account for 22% of the revenue, with a business model that can be understood as royalty commissions or monetization of marketing activities;
3) Dex in DeFi accounts for 15% of the revenue, with a business model of transaction fees and liquidity provision income;
4) Staking in DeFi accounts for 8% of the revenue, with a business model of asset management commissions or spreads;
5) Gamefi accounts for 5%, with a business model of royalty commissions, transfer fees, and NFT sales;
6) Lending in DeFi accounts for approximately 1% of the revenue, with a business model of spreads;
7) Tooling accounts for approximately 1% of the revenue, with a business model of service fees, and in the future, it will also include traffic monetization fees.
Other industries related to Web3.0, which are not core industries of Web3.0 applications, are not counted as part of Web3.0. For example, Web3.0 media, research organizations, training organizations, etc.
From the revenue structure, it can be seen that the application demands in the current BTC ecosystem can be solved by blockchain and its second-layer systems without the need for complex system architecture. However, Gamefi and SocialFi are developing rapidly. Using the example of games from the reference literature, it can be seen that large-scale games already have higher and more specific demands for system architecture.
From the revenue structure, the application demands in the current BTC ecosystem are worth redoing in ecosystems such as Ethereum. Slightly modifying the Ethereum-based on-chain second-layer construction technology and establishing new second layers on Bitcoin can effectively meet these primary demands, with compromises made in decentralization, security, privacy, and resistance to censorship. The new on-chain second-layer constructions based on EVM types in the article "A Comprehensive System of Basic Knowledge for Bitcoin Second-Layer (Layer2) Construction" are examples of this situation.
**(2) Analysis of High-Performance Demand Applications Using the Example of Games**
In the article "Turning the Impossible into Reality: Making Full-Chain Game Development on the Lightning Network a Reality," significant demands for functionality and performance are outlined. The true architecture of Web3.0 applications is gradually emerging.
The problem described in the article: Full-chain games have not found an optimal solution for scalability while ensuring security, privacy, and decentralization. For example, the most popular full-chain game engines, Mud and Dojo, are dedicated to helping full-chain games achieve higher TPS, but players still experience a buffer of over 2 seconds for each operation. In fact, the highest TPS of full-chain games on the blockchain can reach a peak of around a few thousand TPS, which is a significant gap compared to the traditional Web2 3A games with TPS in the tens of thousands. In pursuit of not losing the advantages of the blockchain, full-chain games need to overcome scalability.
In the solutions discussed later in the article, the use of the Lightning Network and RGB to enhance performance is proposed, along with the concepts of ephemeral chains and dedicated chains.
**Ephemeral Chain**
Ephemeral blockchains can be defined as blockchains that will not exist forever. Once the purpose of the blockchain is achieved (e.g., recording transactions), or once its state is permanently stored elsewhere, they will be destroyed. The termination state stored by ephemeral chains only contains data about the termination of ephemeral chains, compressing all content to a significantly smaller scale. Ephemeral chains are mainly limited by transaction delays and throughput on the blockchain.
**Ephemeral Chain vs. State Channels**
Regarding ephemeral chains, since there is state on the public chain, we will eventually have a large number of users. The state that needs to be inserted into the public chain will be reduced in size through pruning/compression/differential extraction, and then saved on the public chain periodically rather than sporadically. The setup of RGB state channels has the potential to bypass the performance constraints of ephemeral chains and achieve the same functionality as ephemeral chains.
**App-Specific Blockchains**
App-specific blockchains are blockchains created for running a single decentralized application (dapp). Developers build new blockchains from scratch using a custom virtual machine (VM) to execute transactions that interact with the application. Developers can also customize different elements of the blockchain network stack—consensus, network, and execution—to meet specific design requirements. Improving smart contract execution speed and addressing computational resource limitations can help app-specific blockchains land. This allows developers to customize infrastructure for different use cases, making development easier. It also allows web3 developers to build powerful value models and expand their dapps to meet exponential growth demands, inspiring more innovation.
Through this game example, along with the analysis of the previous architectures, we can roughly determine the architecture of future large-scale applications.
### 3.3. What Should the Architecture of Large-Scale Web3.0 Applications Look Like
In the previous content, we learned about the common application classifications in Web2.0, which need to be upgraded to Web3.0 to fully enter the Web3.0 era. What kind of architecture can meet the numerous applications mentioned above?
**(1) Simple Differences Between Web2.0 and Web3.0 Architectures**
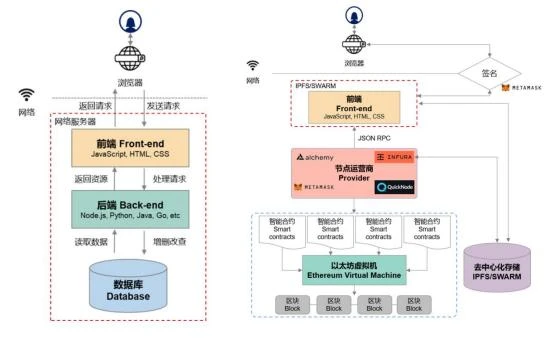 This is based on the article "The Architecture of a Web3.0 Application" by blockchain expert Preethi Kasireddy. The structure described for Web3.0 applications is a very simple one, relying solely on the blockchain system to be completed. However, this structure is too simple and does not yet reflect second-layer construction, making it inadequate for large-scale applications.
Comparing the technical implementations of traditional centralized products and Web3.0 products will make it easier to understand the differences in technical implementations between the two. Combining Gavin Wood's vision of the Web3.0 technology stack, we can see that the biggest difference in Web3.0's technical implementation lies in the backend, with minimal differences in the user experience layer.
**(2) System Architecture for Large-Scale Applications in the Web3.0 Era**
In the era without blockchain, applications were built on top of centralized and distributed systems. For example, e-commerce, instant messaging, and video applications were built on centralized systems, while Thunder download was built on distributed systems.
With the advent of the blockchain system, we entered the Web3.0 era, where applications are built on a complex architecture consisting of the blockchain system, distributed system, and centralized system. The blockchain system and its second-layer extensions handle the transfer and processing of value, while the distributed and centralized systems handle the transfer and processing of information.
As shown in the diagram below,
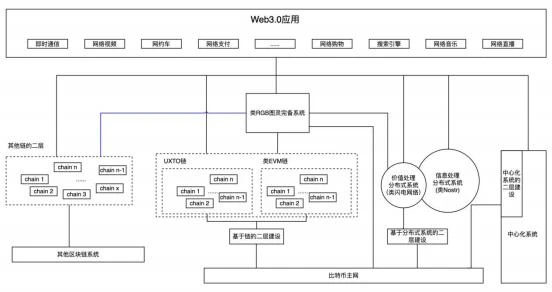
The specific descriptions are as follows:
(1) Bitcoin's main network and second-layer construction are the center of all value, with most of the value built on this network. In Bitcoin's second-layer construction, on-chain second layers achieve performance extension and processing of value, handling full ledger data. In Bitcoin's second-layer construction, off-chain second layers based on distributed systems achieve performance extension, handling locally relevant data, using consensus among relevant parties, but the final calculation results need to be stored on the blockchain system. In Bitcoin's second-layer construction, off-chain second layers based on centralized systems directly provide services to upper-layer applications.
(2) Systems similar to RGB will also require some ephemeral or intermediate chains to complete ledger settlement functions, as indicated by the blue lines in the diagram. This scenario is described in the game example from Reference 1. The reason it has not yet appeared on a large scale is that the construction of systems similar to RGB is complex and has not yet matured.
(3) In addition to the Bitcoin ecosystem, there are other blockchain ecosystems that meet the demands of different business scenarios. As described in our article on second-layer infrastructure, there will be numerous projects based on-chain second layers, which also apply to chains outside the Bitcoin ecosystem. Other blockchain systems and second layers can also enter the Lightning Network and RGB, and as technology matures, this situation will gradually emerge.
(4) In the Web3.0 ecosystem, centralized systems will also have a place, but not as large a proportion as in Web2.0. Centralized systems have many advantages.
(5) In practical applications, the internal connections in the diagram will become more complex, with some not needing to use second layers and directly operating on the first-layer network, such as RGB when using the BP protocol. Other blockchains may also use distributed systems, such as the Lightning Network on Ethereum, although it is not mature yet. If there are demand scenarios, there will be usage scenarios through the modification of some basic features. The diagram provides a simplified description of the architecture of Web3.0 applications.
### 3.4. Feasible Construction Paths
From the income structure, we can see the current application demands in the BTC ecosystem. From the classification of common applications, we can see the future demand for complete entry into Web3.0. This will be a long road. Therefore, for things with a relatively long construction period, they need to be handled in stages.
The three stages here are very similar to the short-term, medium-term, and long-term stages mentioned by Mr. Dashan. It's just that the simple stage of on-chain second-layer construction is also included in the first stage of construction.
(1) The first stage is the early stage of on-chain and on-chain-based second-layer construction
On-chain and on-chain-based second-layer construction, because it is relatively easy, has led to the emergence of numerous applications. Whether it's brc20, src20, arc20, oracles, or those projects based on on-chain second-layer construction, they are very diverse.
This stage of construction is relatively simple, mostly focused on financial applications, and with the experience of Ethereum's second layer, it is easier and faster. Although relatively simple, this process is essential and important. They have helped to prosper the ecosystem, attracted traffic and funds, tested cross-chain connection technology, tested stablecoins, and tested various possibilities. This stage is mainly about completing various verifications of functional feasibility.
(2) The second stage is the mid-to-late stage of on-chain second-layer construction and the construction of second layers based on distributed systems
In this stage, on-chain second-layer construction is also involved, representing the advanced stage of on-chain construction. In addition, the focus of the second stage is to test and improve various distributed second-layer constructions. The Lightning Network will become more mature, RGB functionality and stability will be greatly improved, and application scenarios will become more diverse. Competitors similar to RGB will gradually emerge and mature, such as BitVM. Meanwhile, distributed systems like Nostr will also integrate value functions. This stage is mainly about completing various verifications of functional and performance feasibility.
(3) Large-scale construction based on the Bitcoin ecosystem
The final stage is the mature stage, where Web3.0 begins large-scale construction and gradually matures. The common applications described in 3.1 will begin to enter the Web3.0 era.
Perhaps this stage will take a long time to arrive, or perhaps a turning point event will push a large number of Web2.0 applications to enter, and the time may not be so long.
In any case, when the true Web3.0 era arrives, there will be significant differences, and the functionality and value will be even greater and more brilliant than the overall PC Internet + mobile Internet. Perhaps it will be as stunning as the emergence of Sora in the AI field, very amazing and shocking, just not as sudden in the process.
References
(1) Reference to Mr. Dashan's related articles and course content on the short-term, medium-term, and long-term aspects of the Bitcoin ecosystem.
(2) "Turning the Impossible into Reality: Making Full-Chain Game Development on the Lightning Network a Reality" https://m.jinse.cn/news/blockchain/3667669.html (This article had a greater inspiring and validating effect)
(3) The three observation perspectives mainly refer to "Ethereum EVM Illustrated," Takenobu T., 2018.3
(4) The content related to application classification mainly refers to the author's "Web3.0: Building the Digital Future of the Metaverse" written in 2022.
(5) Reference to graph theory knowledge in university digital logic.
(6) Reference to some content on distributed systems.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







