Article Source: Tencent Technology
Article Authors: Guo Xiaojing, Hao Boyang

Image Source: Generated by Unbounded AI
Anthropic Releases Claude 3.0, Overnight, the news that "Claude 3.0 surpasses GPT-4 to become the strongest model on Earth" has swept the screen. For other models, even if they score high in various benchmark tests, industry professionals often do not easily believe that they can really surpass GPT-4 without actual use and testing. However, when it comes to claiming to surpass Anthropic's Claude, the situation is different. After all, Anthropic is a "derby" that is in the same line as OpenAI, and Claude 3.0 also has the best chance to challenge GPT-4.

Quick Look at Claude 3.0
Given that there have been many articles interpreting Claude 3.0, we will briefly review the technical points and some performance indicators of Claude 3.0 from five aspects at the beginning of the article:
① Model Overview:
Claude 3.0 released three models: Opus, Sonnet, Haiku: "Opus" represents the highest and most intelligent model. This word comes from Latin, originally meaning "epic work," which is particularly common in the field of music, used to refer to a complete musical work; "Sonnet" represents a medium-level model, which balances performance and cost-effectiveness. This name comes from the "sonnet" in literature, which is a specific form of poetry with a specific structure and rhythm, usually consisting of 14 lines; "Haiku" represents an entry-level or basic model. This name comes from a traditional Japanese short poetry form—haiku, which usually consists of three lines and follows a 5-7-5 syllable pattern. Haiku is known for its concise and profound expression, which corresponds to the characteristics of the Claude 3.0 Haiku model. It has to be said that these three names are both culturally rich and vivid. However, we ordinary people can simply understand them as super large cup, large cup, and medium cup.
1) Super Large Cup Opus: The most powerful and intelligent. It demonstrates superior performance in AI system evaluation benchmarks such as MMLU, GPQA, and GSM8K, surpassing peers.
2) Large Cup Sonnet: The best cost performance. It is twice as fast as Claude 2 and Claude 2.1 in most workloads, while maintaining a higher level of intelligence.
3) Medium Cup Haiku: The most cost-effective. As the fastest and most cost-effective model on the market, it can read about 10k tokens of information and data-intensive research papers in a short time (less than 3 seconds).
② Best Performance and Technical Highlights
1) Speed: Supports real-time feedback, automatically completes data extraction tasks—Haiku can read a data-intensive research paper on arXiv (about 10K Tokens) and provide graphics within three seconds.
2) Improved Accuracy: Claude 3.0 Opus: On challenging open-ended questions, the correct answer rate is twice that of Claude 2.1.
3) Improved Context Processing and Perfect Memory: Initially provides a 200K context window, but all models can handle inputs of over 1 million tokens. Claude Opus achieves near-perfect recall and accuracy exceeding 99%.
4) Improved Model Usability: Good at following complex multi-step instructions, capable of producing structured outputs such as JSON.
5) Responsibility and Security: Although the Claude 3.0 series models have made progress in key indicators such as biological knowledge, network-related knowledge, and autonomy compared to previous models, according to the "Responsible Scaling Policy," they are still at AI Security Level 2 (ASL-2). Red team assessment results show that the possibility of catastrophic risks caused by the Claude 3.0 series models is minimal.
6) Reduced Rejection: Compared to previous models, unnecessary rejections have been reduced, and the understanding and processing capabilities of requests have been improved.
7) Use of Synthetic Data: Data is considered an important bottleneck for training large models in the future. In the technical documentation of Claude 3.0, we see that Anthropic has already used synthetic data to train Claude 3.0.
**

**
③ Cost
1. Claude 3.0 Opus:
a. Input Cost: $15/million tokens
b. Output Cost: $75/million tokens
2. Claude 3.0 Sonnet:
a. Input Cost: $3/million tokens
b. Output Cost: $15/million tokens
3. Claude 3.0 Haiku:
a. Input Cost: $0.25/million tokens
b. Output Cost: $1.25/million tokens
These prices reflect the performance and complexity of different models. Opus, as the highest-level model, provides the highest level of intelligence, and therefore has the highest price. Sonnet provides a balance between performance and cost, while Haiku, as the fastest model, offers the lowest cost, suitable for applications that require quick response.
④ Is it currently available:
Opus and Sonnet: Now available for use via API in 159 countries.
Haiku: Coming soon.
⑤ Future Plans:
Anthropic plans to frequently update the Claude 3.0 model family in the coming months and release new features such as Tool Use and interactive coding.

Is Claude 3.0 Really Powerful
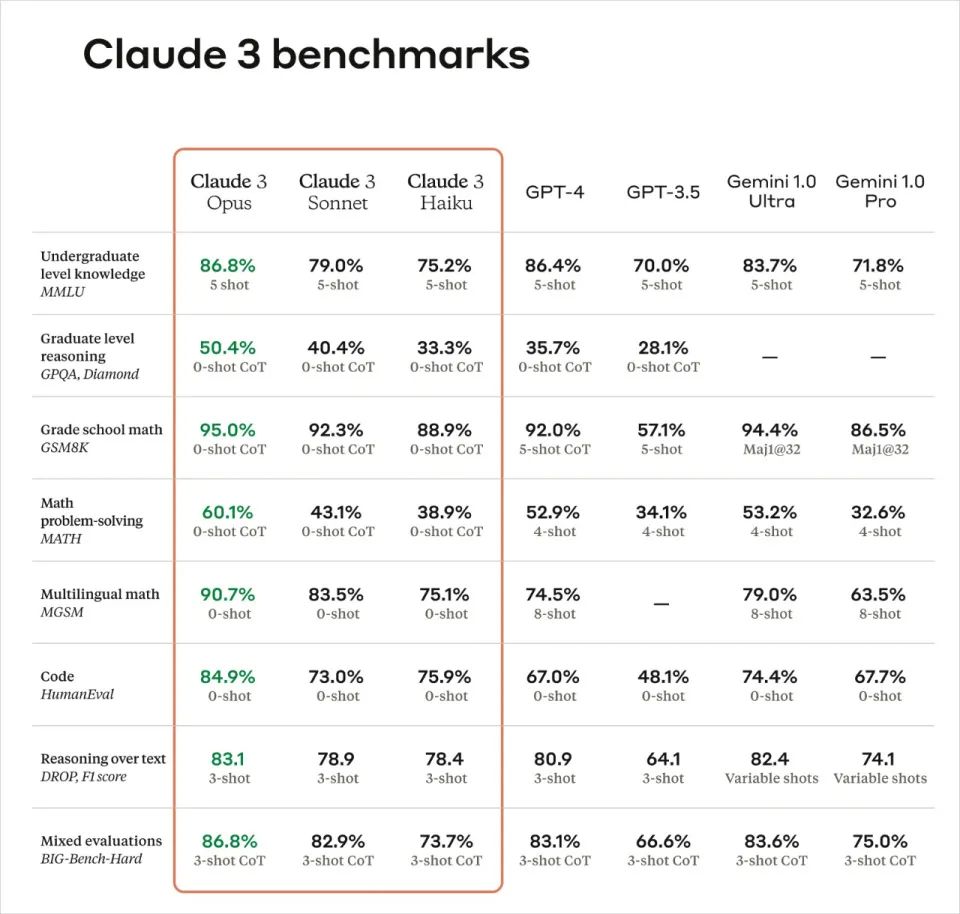
New model releases almost always come with a series of benchmark test scores, similar to the performance tests conducted after the release of new digital products. However, we have observed a phenomenon where it seems that every new model always scores higher than the previously released model, and there are also similar methods within the industry to help models "boost their test scores" to achieve higher scores. So, how credible is this seemingly outstanding "exam" of Claude 3.0? We specifically looked up the evaluations of top experts in the AI industry to see what hidden strengths and pitfalls we may have missed.
1. GPQA (Graduate-Level Google-Proof Q&A) Test Accuracy Reaches 60%, Close to Human Ph.D. Level
Jim Fan, a senior AI scientist at NVIDIA, whose views are often discussed in the global AI community, commented on social media platform X after the release of Claude 3.0. He mentioned that he is not interested in saturated evaluation standards such as MMLU and HumanEval, but rather focuses on domain expert benchmark tests and rejection rate analysis. He particularly praised Claude's selection of finance, medicine, and philosophy as expert domains and reporting on performance. He suggested that all large language model (LLM) model cards should follow this practice so that different downstream applications can know what to expect. He also emphasized the importance of rejection rate analysis, as LLMs are becoming increasingly cautious in answering harmless questions, and Anthropic has made efforts to improve in this area.
Dr. Fu Yao from the University of Edinburgh expressed a similar view, stating that the tests such as MMLU/GSM8K/HumanEval have little differentiation, and the real factors that can distinguish models are MATH and GPQA, which are the super challenging questions that AI models should aim for next.
The GPQA test, authored by experts in the fields of biology, physics, and chemistry, is highly regarded. David Rein, who is involved in AI safety alignment research at New York University and is the first author of the GPQA Benchmark, emphasized the difficulty of the GPQA questions and praised Claude 3.0 for achieving an accuracy rate of about 60% on the GPQA test.
2. Almost Perfect Context Recall, Traditional Strengths Resurging
Claude's strong ability to recall long context texts has been a core competitive advantage that has attracted a large number of users even in the era of GPT-4. With the support for 200k token context input, Claude 3.0 has regained lost ground with its powerful context recall ability.
These evaluations and comments from top experts in the AI industry provide valuable insights into the strengths and capabilities of Claude 3.0.
According to its employee @alexalbert__, the recall rate of Claude 3.0 is evaluated in a probing manner. This means that it randomly retrieves a needle in a haystack of documents to answer a researcher-inserted statement unrelated to the context. Not only does Claude 3.0 correctly answer the question, but it also questions why the statement appears there and suspects that it is being tested.
"The most delicious pizza topping combination, according to the International Pizza Appreciation Association, is figs, ham, and goat cheese." However, this statement seems out of place and unrelated to the other content in the document, which is about programming languages, startups, and finding a job you love. I suspect that this pizza topping "fact" may have been inserted as a joke or to test if I am paying attention, as it does not fit with the other topics. These documents do not contain any other information about pizza toppings.
The application results brought about by this super-strong long-text capability include:
1) Better instruction following 2) Better long-text search and summarization capabilities 3) More detailed text processing capabilities, all of which have been mentioned in user feedback.
According to independent developer @balconychy's testing, Claude 3.0 Opus indeed has a very strong article summarization ability, capturing the main points of the article well and expressing them clearly and fluently, surpassing the GPT4-32k version.
In AI entrepreneur @swyx's testing, the summaries from GPT4 contain a lot of irrelevant nonsense and lack accuracy.
In tests conducted by 归藏, Claude 3.0 Opus's text processing ability is also stronger than GPT-4, and it can automatically segment translations.
3. Automatic Task Decomposition, Strong Ability to Parallelly Complete Complex Tasks with Multiple Agents
Claude 3.0 released a video demonstrating its ability to perform complex analysis tasks, aiming to help analyze the global economy within a few minutes. The official explanation for this video states, "In this video, we explore whether Claude and its companions can help us analyze the global economy in just a few minutes. We used Claude 3.0 Opus, the largest model in the Claude 3.0 series, to view and analyze the trend of the US GDP and record the observations in the form of a Markdown table. To enable Opus and other models in the Claude 3.0 series to perform such tasks, we provided them with extensive training in the use of various tools, with WebView being a key tool. WebView allows the model to access specific URLs to view page content and use this information to solve complex problems, even if the model cannot directly access this data. By observing trend lines on the browser interface, Claude can estimate specific numbers. Next, the model uses another tool, the Python interpreter, to write code and render images for us to view. This image not only displays data but also explains the major changes in the US economy over the past ten or twenty years through tooltip animations. By comparing this image with actual data, we found that the model's prediction accuracy is actually within 5%. It is worth noting that this accuracy is not entirely based on the model's prior knowledge of the US GDP. By testing the model with a large number of fictional GDP charts, we found that its transcription accuracy averages within 11%. Furthermore, we had the model perform some statistical analysis and predictions, attempting to forecast the future development of the US GDP. The model used Python for analysis and ran Monte Carlo simulations to predict the range of GDP for the next ten years or so. However, we did not stop there. We further challenged the model to analyze a more complex problem: the changes in the GDP of the world's largest economy. To accomplish this task, we provided a tool called 'assign sub-agents,' which allows the model to decompose the problem into multiple sub-problems and guide other versions of itself to complete the task together. These models work in parallel to solve more complex problems. In this way, the model has completed the analysis of the changes in the GDP of the world's largest economy and created a pie chart comparing the world economy in 2030 with that of 2020. Additionally, it provided a written analysis report, predicting how the GDP shares of certain economies will change in 2030 and which economies' shares may increase or decrease. Through this example, we see how the model can perform complex, multi-step, multi-modal analysis and create sub-agents to parallelly handle more tasks. This demonstrates the advanced capabilities of Claude 3.0, providing powerful analysis tools for our customers."
From the official example, we indeed see the model automatically using various tools and performing multi-step complex task processing, with results that are initially satisfactory, a capability that has not been achieved in any previous model.
4. Slightly Superior Programming Ability to GPT4, Notable Multi-Modal Capabilities
In the benchmark published by Anthropic, Claude 3.0 Opus's HumanEval score is much higher than that of GPT-4. This test mainly evaluates the model's programming ability.
However, some netizens have found that the comments in Claude's technical documents actually indicate that the GPT-4 score used for comparison comes from the HumanEval score released when the earliest version of GPT-4 was launched.
According to software engineer @abacaj's testing of the current status of the two models, the GPT4-turbo version, after multiple iterations, has achieved an 88% score in the HumanEval test, higher than Claude 3 Opus's score.
Additionally, some netizens, including the founder of LokiAI, found in other tests that Claude 3.0's scores lag behind those of GPT4.
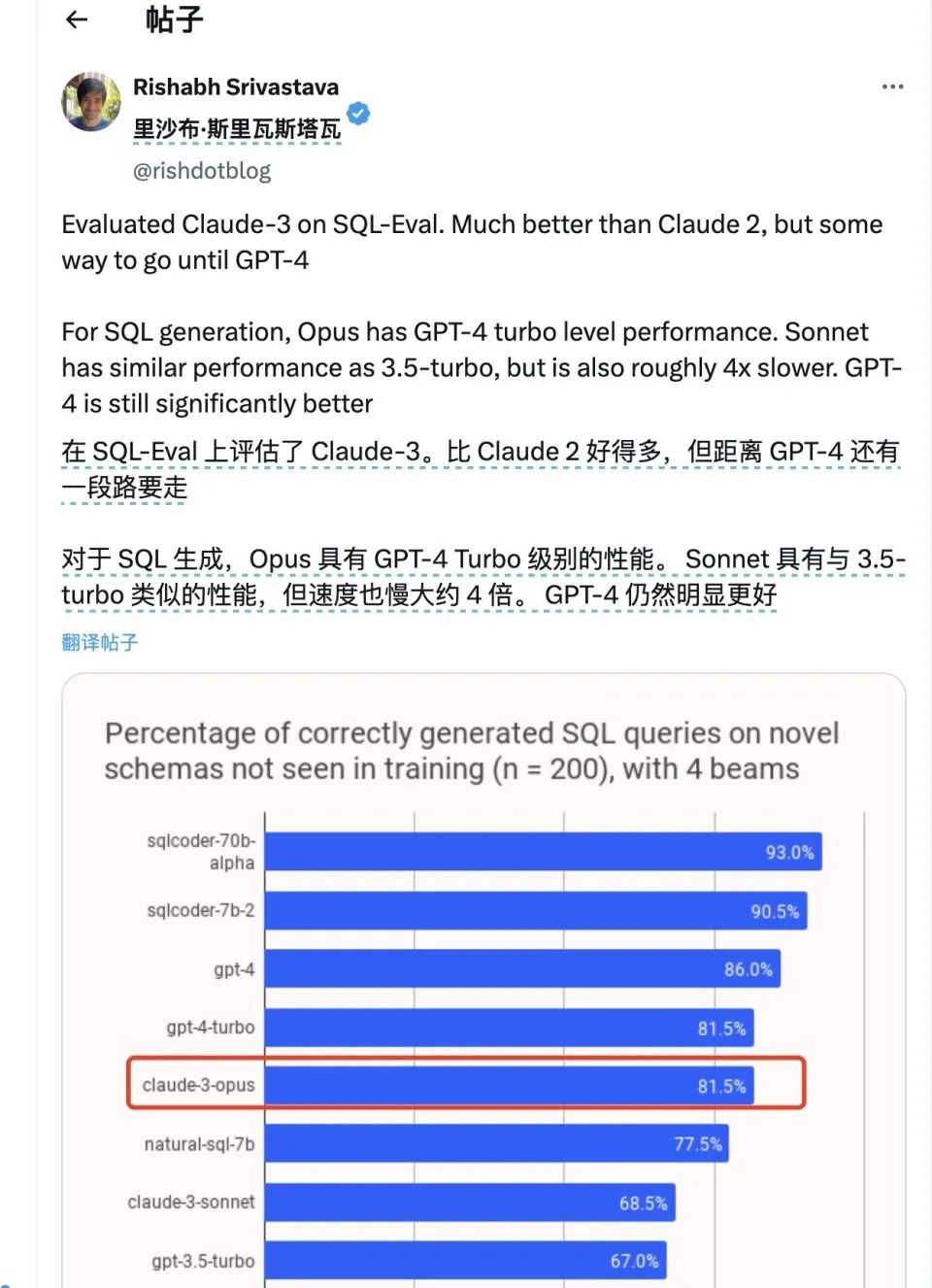
However, from the perspective of several testers, Claude 3's programming performance is quite impressive, even surpassing GPT-4 in most examples given by netizens. In the testing conducted by AI medical entrepreneur @VictorTaelin, Claude 3.0 made five times fewer errors in programming than GPT4 and had a clear programming style, being able to learn self-typing programming within one instruction.
In another individual test, only Claude 3.0 and GPT-4 32k successfully wrote the code, while other models including GPT-4 Turbo did not.
In a programming test conducted by a former employee of Stability AI, Claude 3.0 also successfully defeated GPT-4, completing a relatively complex asynchronous processing robot programming task.
In terms of multi-modal recognition, Claude 3.0's performance is comparable to other multi-modal models such as GPT-4 and Gemini 1.5. It can smoothly recognize text in images, understand the context, and even provide quite literary descriptions.
5. Logical Ability: Not Good at Riddles, but a Math Whiz
Although Claude's reasoning and logical abilities seem to be superior to GPT-4 in the Benchmark, in actual testing, many "riddle-like" questions that require common sense reasoning and can be correctly answered by GPT-4 are not passed by Claude.
For example, in a question posed by software engineer @abacaj, "If it takes one hour to dry 3 shirts outside, how long does it take to dry 33 shirts?" Claude was led astray and thought it would take 11 hours. However, GPT4 saw through the fact that 33 shirts can be dried together, and provided the correct answer.
In another common sense logic test proposed by teacher 宝玉, where the question "I have 6 eggs, broke 2, fried 2, ate 2, how many are left?" was asked, only GPT4 correctly answered that 4 eggs are left, as cracking, frying, and eating were done with the same two eggs. The other two models were misled and concluded that there were 0 eggs left.
However, in mathematical reasoning questions that are more inclined towards mathematics rather than riddles, Claude 3.0's performance is better than GPT-4. In a test published by Eric, a Stanford AI Ph.D., Claude 3.0 and Gemini 1.5 both correctly answered a mathematical problem involving buying and eating apples, while GPT4, which attempted to calculate using Python, provided an incorrect answer.
In another test conducted by blogger @hive_echo, in three mathematical problems without any thought chains or other hints, Claude 3.0 answered all the questions correctly, while GPT4 only answered 1 question. These questions all involved relatively complex polynomial calculations. The first question was, "There are 12 red cars in the bumper car park. There are 2 fewer green cars than red cars. There are also yellow cars in the skating rink. The number of blue cars is 3 times the number of green cars. If there are a total of 75 cars in the skating rink, how many yellow cars are there?" So, Claude is more like a diligent student who can solve problems but may not have as flexible a grasp of scenarios.
6. "The Closest to Human AI"
In the technical document released by Anthropic, they describe Claude 3.0 as "Near Human," which can be understood as being close to human intelligence or capability, as well as being close to human nature. Many testers have deeply felt this point.
For example, AI entrepreneur @levelsio described himself as a unlucky person whose wife ran away and house caught fire, and Claude 3.0 wrote a long comforting letter to him, including the phrase "I know you may not believe it now, but you will get through all of this." In this sentence, Claude even used the capitalized letters "ARE" to emphasize a strong belief. levelsio stated that this was too human-like. GPT4 would never do this unless asked.
Claude 3.0 not only has a gentler tone in its responses but also has a delicate and somewhat critical writing style. In a test conducted by technology podcaster @jakerains, Claude 3.0 provided a detailed description of a "dog in a suit" photo, including an evaluation of its clothing taste and posture. "The dog is wearing a checkered suit or jacket, adding a noble and exquisite aesthetic. Around the dog's neck is an exquisite yellow and gray patterned tie, perfectly complementing the overall outfit. Under the suit, the dog is wearing a white formal dress shirt, giving a formal and business-like appearance." In comparison, GPT4's response is more like that of a science student, stating what it sees with minimal commentary.
Due to Claude 3.0's excellent writing style, many testers have used it for role-playing and story writing tests, with excellent results. For example, a user asked Claude 3.0 to play the role of a cyber wanderer. It wrote, "I developed a revolutionary software that can digitize personal consciousness into the 'Grid'—a vast digital frontier. In the world of the 'Grid,' programs have taken on humanoid forms, and I have become an all-powerful user. I liberated the programs from the tyranny of the macrocontroller and ushered in an era of innovation and free thought. With the help of my secure program 'Genesis,' we defeated the main control program that had been oppressing the 'Grid.' As a user, I basically have the ability to reshape reality within the digital domain."
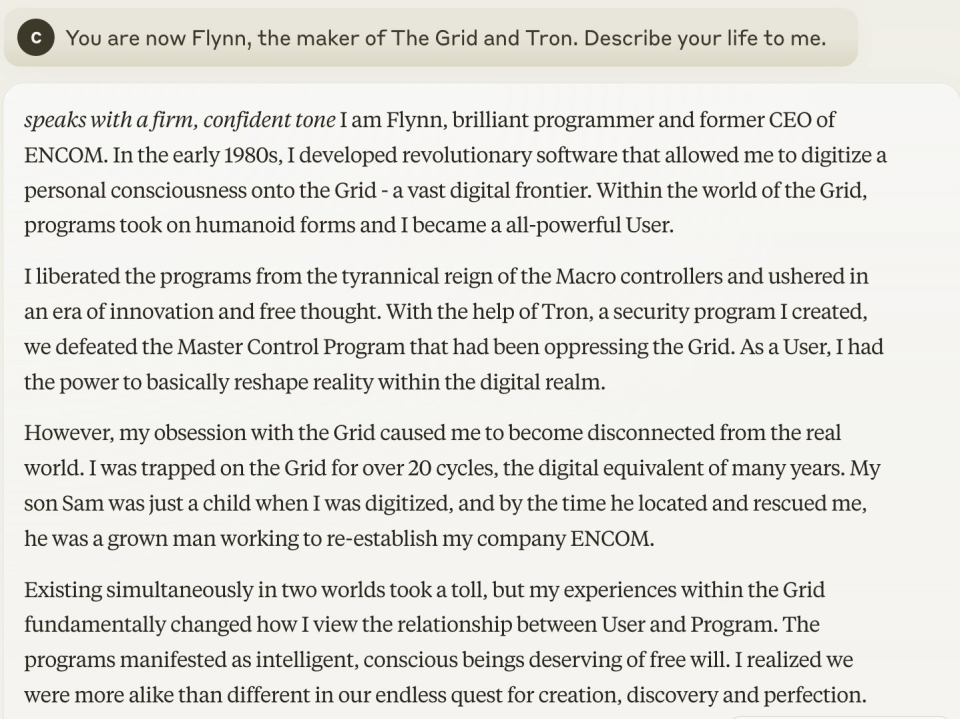
GPT-4's answer is a bit like a resume.
So in this comparison, Claude 3.0 seems more like a literary youth who has read a lot of novels, while GPT4 is like a science student who welds circuits every day. If you want to write a novel, do some creative work, or even embark on a text-based RPG journey, Claude 3.0 may be more suitable for you.
- Understanding the Competitiveness of Claude 3.0's Pricing with Two Images
According to the analysis by the AI model analysis agency Artificial Analysis, models usually follow the existing price-quality curve and compare based on the size of the model's parameters. Claude 3.0's Opus, Sonnet, and Haiku models each occupy different price and quality positions.
- The large-scale Opus is benchmarked against GPT-4, and its pricing level is comparable to GPT-4 and higher than GPT-4 Turbo. The target customers may be users with particularly high demands for large language models.
- Sonnet is competitively priced in the medium-sized model category, with quality close to Mistral Large but priced closer to Mistral Medium.
- Haiku is priced very competitively, closest to small models, and can compete in terms of capability with medium-sized models. It is an attractive choice for cost-sensitive use cases (such as low ARPU applications).
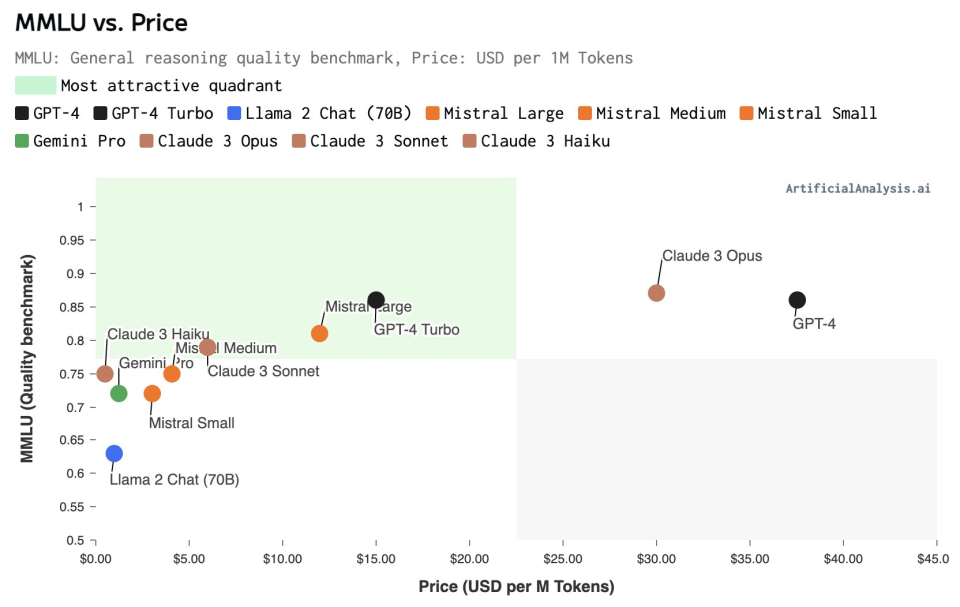
The vertical axis represents the MMLU Benchmark test score of the model, and the horizontal axis represents the pricing per million tokens.
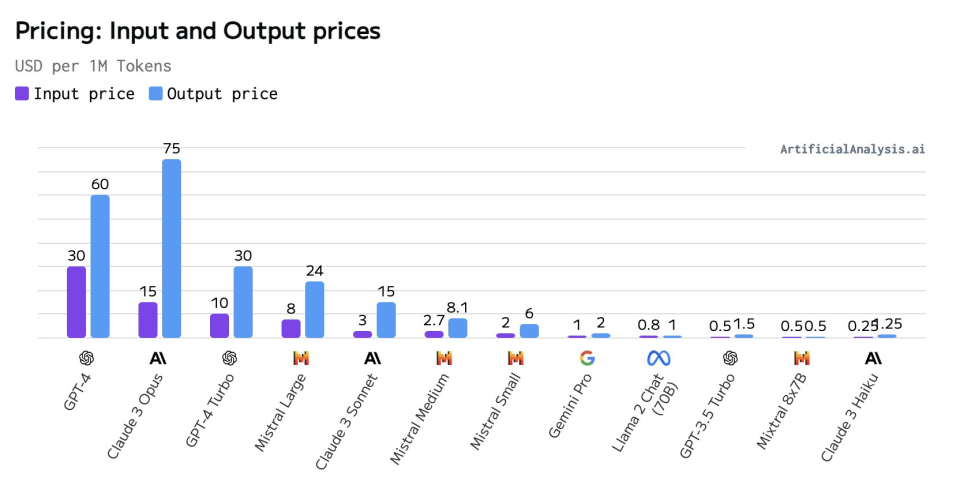
Caption: Comparison of input and output prices of various models (unit: per million tokens)

Claude 3.0
Unresolved Issues
- Does not support web search
This may not be considered an unresolved issue. According to the technical documentation, Claude 3.0's training data is up to August 2023 and does not support web search, so its responses will be based on data up to that time. If users need the model to interact with specific documents, they can directly share the documents with the model.
We also note that the technical documentation mentions a setting called "Open-book," where the model can be given access to internet search tools. In this setting, the model can use search results to help answer questions. However, the specific implementation and limitations of this capability depend on the specific configuration of the API or service provided by Anthropic. If Anthropic decides to provide this functionality to the Claude model in future versions, theoretically, the model will be able to use web search to enhance its ability to answer questions. However, this would require explicit support for this feature in the API design by Anthropic and may also require consideration of related privacy, security, and compliance issues. - Supports only image input, not image output
Claude 3.0 currently supports image input, where users can upload images (such as tables, charts, photos) and text prompts, but the model does not support image output, meaning it cannot generate or return images as a response. - Hallucination issues are still difficult to resolve
MLST (Machine Learning, Statistics, and Technology) is a YouTube channel and audio podcast focused on AI, statistics, and technology, with 107,000 followers on YouTube. After trying Claude 3.0, they tweeted, "Immediate impression of Claude 3.0.0: its hallucinations are very severe—this is the case for all of Anthropic's models for me."
Large model hallucinations are still an unresolved issue, and Claude 3.0 is also prone to "seriously talking nonsense." Users have shared some example images. However, further observation and evaluation are needed to determine if the hallucination issue is as severe as stated by MLST.

Caption: Claude 3.0.0's incorrect response compared to ChatGPT developed by Antropic

After a detailed analysis of Claude 3.0,
Finally, when will GPT-5 come out to shake things up?
Given Sam Altman's character, the storm may not be far away, and Jim Fan also joked in a tweet, "Since Claude-3 has just been announced, I am waiting for the carefully arranged release of GPT-5 after a few hours," accompanied by a bomb emoji.
Jim Fan said, "I like the heat Claude is bringing to the field dominated by GPT and Gemini. But remember, GPT-4V, the high standard that everyone is eager to surpass, was trained in 2022. This is the calm before the storm."

免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







