Article Source: AIGC Open Community

Image Source: Generated by Unbounded AI
With the popularity of platforms such as Douyin and Kuaishou, more and more users are creating a large amount of short video content. However, effectively understanding and analyzing these videos still faces some difficulties. Especially for videos longer than a few minutes, or even hours, traditional video subtitle generation techniques often fail to meet the demand.
Therefore, researchers from the University of North Carolina and Meta AI have open-sourced the Video ReCap, a recursive video subtitle generation model. This model can handle videos ranging from 1 second to 2 hours and output video subtitles at multiple levels.
In addition, the researchers introduced a hierarchical video subtitle dataset, Ego4D-HCap, by adding 8,267 manually collected long video summaries to the Ego4D dataset, and used this dataset to comprehensively evaluate Video ReCap.
The results show that Video ReCap's test metrics for short video segment subtitles, medium-length segment descriptions, and long video summaries all significantly outperform multiple strong baseline models. The hierarchical video subtitles generated by this model also significantly improve the long video question-answering performance based on the EgoSchema dataset.
Open Source Address: https://github.com/md-mohaiminul/VideoRecap?tab=readme-ov-file
Paper Address: https://arxiv.org/abs/2402.13250

Introduction to the Video ReCap Model
The core technology of Video ReCap uses a recursive video language architecture, mainly through a recursive processing mechanism, allowing the model to understand videos at different time lengths and abstraction levels, thereby generating accurate and hierarchically rich video description subtitles. It mainly consists of three major modules.
1) Video Encoder: Video ReCap uses a pre-trained video encoder to extract features from long videos. For short video clips, the encoder outputs dense spatiotemporal features.
This allows the model to capture detailed information at a fine-grained level. For higher-level subtitles, global features (such as CLS features) are used to reduce computational costs and capture the global properties of the long video input.
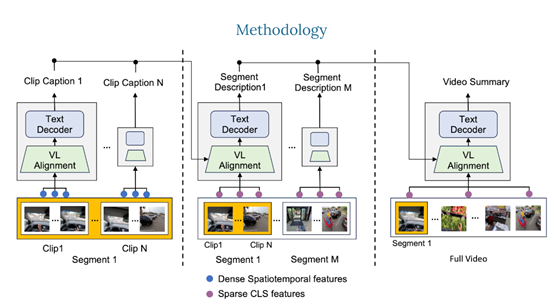
2) Video-Language Alignment: This module can map video and text features to a joint feature space so that the recursive text decoder can jointly process both.
Specifically, a pre-trained language model is used, and trainable cross-attention layers are injected into each transformer block to learn a fixed number of video embeddings from the video features. Then, text embeddings are learned from subtitles belonging to specific hierarchies. Finally, the video and text embeddings are concatenated to obtain joint embeddings, which are then used by the subsequent recursive text decoder.
3) Recursive Text Decoder: This module is mainly used to handle subtitles for short, medium, and long videos, so it adopts a hierarchical generation strategy. First, features extracted from short video clips are used to generate subtitles at the short clip level. These short clip-level subtitles describe the atomic actions and low-level visual elements in the video, such as objects, scenes, and atomic actions.

Then, using sparsely sampled video features and subtitles generated at the previous level as input, subtitles at the current level are generated. This recursive design can effectively leverage the interaction between different video hierarchies and efficiently generate subtitles for videos up to 2 hours long.
Experimental Data for Video ReCap
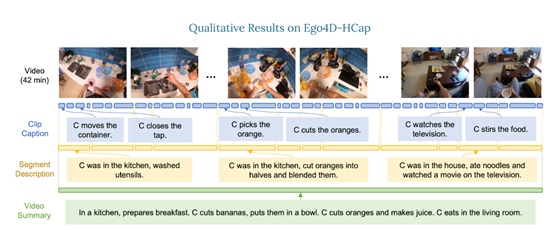
To evaluate the Video ReCap model, researchers introduced a new hierarchical video subtitle dataset, Ego4D-HCap. This dataset is based on Ego4D, one of the largest publicly available first-person video datasets.
Ego4D-HCap mainly contains subtitles at three levels: short clip subtitles, descriptions of several minutes in length, and long segment video summaries, used to verify the effectiveness of the hierarchical video subtitle task.
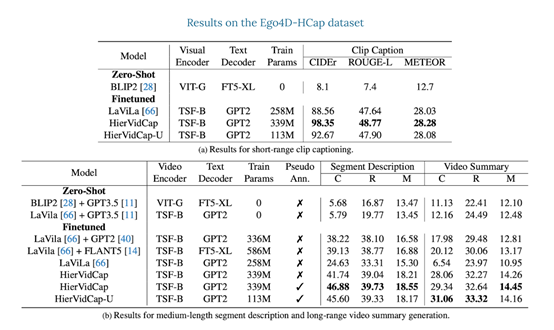
The results show that at all three time levels, the Video ReCap model significantly outperforms previous strong video subtitle baseline models. Furthermore, it was found that the recursive architecture is crucial for generating segment descriptions and video summaries.
For example, the model without recursive input shows a performance decrease of 1.57% in CIDEr for segment description generation and a decrease of 2.42% for generating long video summaries.
The researchers also validated the model on the recently released long sequential video question-answering benchmark, EgoSchema. The results show that the hierarchical video subtitles generated by Video ReCap can improve the performance of the text question-answering model by 4.2%, achieving a record-breaking 50.23% overall accuracy, which is an 18.13% improvement over the previous best method.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







