Recently, when I was researching the BTC ecosystem and various inscription projects in the past two weeks, I found that there are few articles that can clearly explain the principles and technical details: for example, how transactions are initiated during the casting of inscriptions, how the sats in UTXO are tracked, where the inscribed content is placed in the script, and why BRC20 requires two operations when transferring. I found that without understanding these technical details, it is difficult to understand the differences between various protocols such as BRC20, BRC420, atomicals, stamps, and Runes. This article will delve into the basic knowledge of the BTC blockchain and try to answer the above questions.
Block Structure of BTC
The blockchain is essentially a multi-user accounting technology. In computer science terms, it is a distributed database, where records (accounts) within a certain period of time form a block, and then the ledger is extended in chronological order.
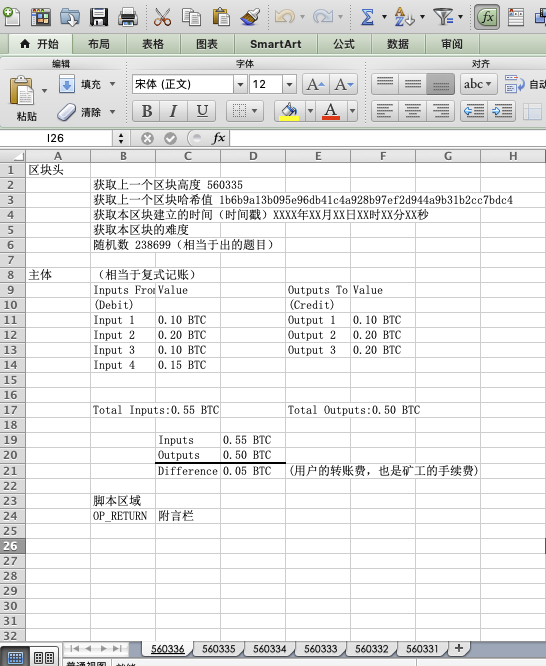
We used an Excel table to illustrate the working principle of the blockchain. An Excel file represents a blockchain, with each individual table representing a block. The blocks are arranged in chronological order from 560331, 560332, all the way to the latest 560336. Block 560336 will package the most recent transactions. The main part of the block is the most common double-entry bookkeeping method in the accounting field, where one address is recorded as a debit (inputs from), and the other address is recorded as a credit (outputs to). The "Value" corresponds to the amount of BTC for the respective address. The amount of coins in "Inputs" will be greater than the amount in "Outputs", and the difference is the transfer fee at the user level, which is also the fee obtained by the miner (accountant). The block header will obtain the height of the previous block, the hash value of the previous block, the establishment time of the current block (timestamp), and a random number. So, as a decentralized accounting technology, who gets the right to account for the next block? It relies on this random number and the corresponding hash value. Miners with computing power calculate the hash of the current block using the random number, and the miner who first obtains the hash value that meets the conditions will have the right to account for the next block and win the block reward and transaction fee. Finally, there is the script area, which can be used for some extended applications, such as the script op_return, which can be used as a memo field. It is important to note that in actual blocks, the script area is attached to the input and output information, rather than being a separate area. For example, the script attached to the input is the unlocking script (ScriptSig), which requires the wallet address to sign with the private key to authorize the transfer, while the script attached to the output is the locking script (ScriptPubKey), used to set the unlocking conditions for receiving the BTC (generally, the condition is "only the person with the corresponding private key can spend it").
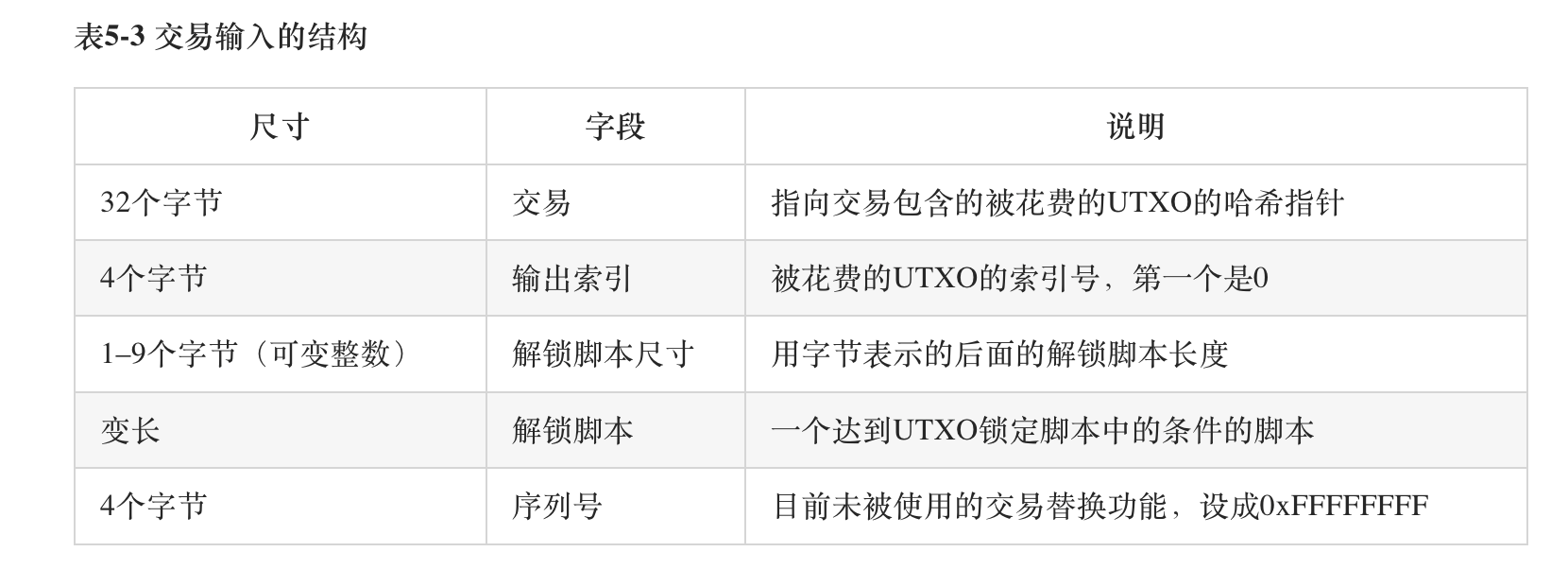
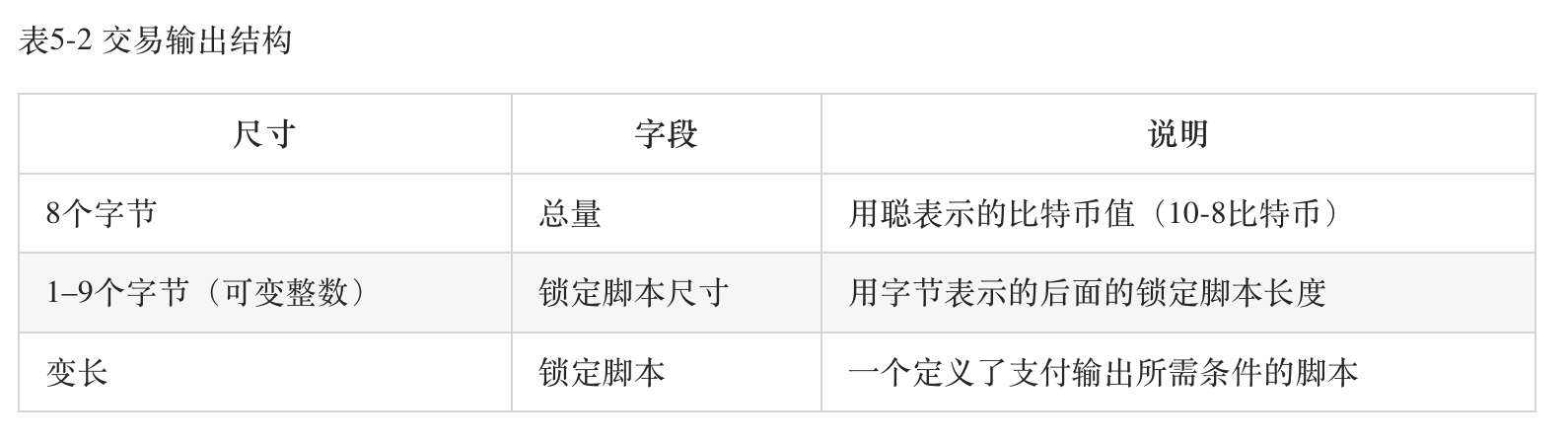
The above two images are the original data structure tables for input and output. In execution, the script acts as an additional parameter for transaction information, where the unlocking script (ScriptSig) is also known as "witness data" because it requires private key authorization.
Segregated Witness and Taproot
Although the Bitcoin network has been running for over 10 years without any significant events, there have been several instances of transaction costs soaring to unfeasible highs. Therefore, Bitcoin developers have been discussing how best to scale the network to handle the continuously growing transaction volume.
In 2017, this debate reached its peak, and the Bitcoin development community split into two camps: one supporting the implementation of a feature called SegWit using a soft fork, and the other supporting "big block" proponents who advocated for direct block size increases.
As mentioned earlier, the unlocking script requires the use of a private key to generate "witness data". Can this witness data be separated from the block to indirectly increase the number of transactions each block can accommodate? Segregated Witness (SegWit) was officially activated in August 2017. Its implementation involves splitting all transaction data into two parts: the basic transaction information (Transaction Data) and the signature information (Witness Data), and storing the signature information in a new data structure called "segregated witness" in a new block, separate from the original transaction.
Technically, the implementation of SegWit means that transactions no longer need to include witness data (which would not occupy the 1MB space originally allocated for blocks). Instead, at the end of a block, an additional independent space is created for witness data. It supports arbitrary data transfers and has a discounted "block weight", cleverly keeping a large amount of data within the Bitcoin block size limit to avoid the need for a hard fork. As a result, the transaction data size limit for Bitcoin transactions was increased, while the transaction fee for signature data was reduced. Prior to the SegWit upgrade, the capacity limit for Bitcoin was 1MB, and after SegWit, although the capacity limit for pure transactions remains 1M, the size of the segregated witness space reaches 4MB.
Taproot, implemented in November 2021, consists of three different Bitcoin Improvement Proposals (BIPs), including Taproot, Tapscript, and a new digital signature scheme called "Schnorr signatures". Taproot aims to bring many benefits to Bitcoin users, such as improving transaction privacy and reducing transaction fees. It will also enable Bitcoin to execute more complex transactions, thereby expanding its use cases (adding some opcodes).
These updates are key driving factors for Ordinals NFT, which stores NFT data in the spent script path of Taproot (witness data space). This upgrade makes it easier to structure and store arbitrary witness data, laying the foundation for the "ord" standard. With the relaxation of data requirements, assuming a transaction can fill the entire block with its transaction and witness data—reaching the 4MB block size limit (witness data space)—greatly expands the types of media that can be placed on the chain.
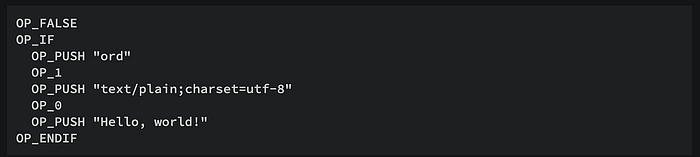
Some may wonder, since some strings are placed in the script, are there no conditions for these strings? What if these scripts are actually executed? What if random content is placed, will it cause error codes to reject the block? This brings us to the OP_FALSE instruction. OP_FALSE (also represented as "0" in Bitcoin scripts) ensures that the execution path in the script language never enters the OP_IF branch and remains unexecuted. It serves as a placeholder or no operation (No Operation) in the script, similar to a "comment" in high-level languages, to ensure that the subsequent code is not executed.
UTXO Transaction Model
The above discussion focuses on the basic principles of BTC from a computer data structure perspective. Let's now discuss the UTXO model from a financial model perspective.
UTXO stands for Unspent Transaction Outputs, which can be understood as the remaining funds that have not been spent in a transaction. So why does Bitcoin use this concept? This goes back to the accounting method's account transaction model and account balance model.
Because we have been in a centralized system for too long, we are very accustomed to the account balance model of accounting. When User A transfers 100 dollars to User B, the bank will first check if User A's bank account has 100 dollars. If it does, the bank will deduct 100 dollars from User A's account and add 100 dollars to User B's account, completing the transfer.
However, Bitcoin's accounting algorithm does not have the concept of a balance. The distributed ledger on the blockchain only records individual transactions and does not directly record the current balance of an account (recording the balance generally requires specialized server nodes, which would be centralized). Assuming User A's balance is 1000 dollars, if User A transfers 100 dollars to User B, this transaction will be recorded as:
Transaction 1: User A transfers 100 dollars to User B
Transaction 2: User A transfers 900 dollars to themselves (UTXO)

Although Transaction 2 is a single transaction, functionally it acts as the account balance, indicating that after completing the 100 dollar transfer, User A's account still has 900 dollars remaining.
So, why create a UTXO like this? Because the BTC blockchain can only record transactions and cannot record account balances. Without UTXO, calculating the balance would require adding up all the incoming and outgoing transactions of an account, which is a very time-consuming and resource-intensive task. The appearance of UTXO cleverly avoids the pain point of having to backtrack all transactions when calculating the balance.
UTXO has a characteristic similar to coins - they cannot be broken open. So, how are input amounts assembled during the transaction, and how is change given? We can use coins as an analogy (in fact, it's better to automatically translate the word "UTXO" to "coin" whenever you see it).
When Xiao Ming transfers 1 bitcoin to Xiao Gang, the process is as follows: Xiao Ming needs to collect enough inputs, such as finding a UTXO with a value of 0.9 corresponding to Xiao Ming's address in past transactions, which is not enough for 1 bitcoin. Fortunately, multiple inputs are allowed in a transaction, so Xiao Ming also finds a UTXO with a value of 0.2. In this transaction, there will be two inputs. There will also be two outputs: one pointing to Xiao Gang's address with a value of 1 bitcoin, and the other pointing to Xiao Ming's own address with a value of 0.1 bitcoin, which is the change (this example ignores gas).
In other words, Xiao Ming has two coins in his pocket, one worth 0.9 and the other worth 0.2. At this point, Xiao Ming needs to pay a coin worth 1, so he needs to give both coins to Xiao Gang, who then gives 0.1 change back to Xiao Ming. So, the essence of this accounting model is to avoid "calculating the balance" through the action of "giving change".
Ordinal Protocol's Sorting System
The Ordinal protocol can be said to be the source of the current explosion in the BTC ecosystem, as it decomposes homogeneous BTC into the smallest unit, sat, and assigns a sequence number to each sat. How is this done?
We know that the total supply of BTC is 21 million, and one BTC can be divided into 100 million units (sats), making sat the smallest unit of BTC. These BTC or sats are typical homogeneous tokens (FT). Now, let's try to assign a sequence number (ordinal) to these sats.
When discussing the data structure of blocks earlier, we mentioned that transaction information needs to specify the input addresses and amounts, as well as the output addresses and amounts. Each block contains two types of transactions: BTC block rewards and transaction fees. Transaction fees transactions necessarily have inputs and outputs, but because the block reward is BTC generated out of thin air, it has no input address, so the "input from" field is blank, also known as the "coinbase transaction". The total supply of 21 million BTC comes from these coinbase transactions, and they are listed at the beginning of the transaction list in all blocks.
The Ordinal protocol stipulates the following:
- Numbering: Each sat is numbered according to the order in which they were mined.
- Transfer: According to the first-in-first-out rule, from the input of the transaction to the output.
The first rule is relatively simple, as it determines that the numbering can only be generated from the coinbase transactions in the mining rewards. For example, if the mining reward for the first block is 50 BTC, the first block will allocate sats in the range of [0;1;2;…;4,999,999,999]; and if the reward for the second block is also 50 BTC, the second block will allocate sats in the range of [5,000,000,000;5,000,000,001;…;9,999,999,999].

The difficult part to understand here is that since UTXO actually contains many sats, and each sat in this UTXO looks the same, how are they sorted? This is actually determined by the second rule. Let's take a simple example:
Let's assume that the smallest unit of BTC is 1, and a total of 10 blocks have been mined, each with a block reward of 10 BTC, totaling 100 BTC. We can directly assign a sequence number (0-99) to these 100 BTC. If there are no spending situations, we only know that the 10 BTC in the first block are numbered (0-9), the 10 BTC in the second block are numbered (10-19), and so on until the 10 BTC in the tenth block are numbered (90-99). Because there are no expenditures, there are no outputs, so we can only assign a range of numbers to each 10 BTC.
Suppose in the second block, two outputs are added: one is 3 BTC, and the other is the "change" of 7 BTC, corresponding to transferring 3 BTC to someone else and giving 7 BTC back to oneself. At this point, in the block's transaction list, let's assume that the 7 BTC given back to oneself is ranked first (corresponding to numbers 10-16), and the 3 BTC given to someone else is ranked second (corresponding to numbers 17-19). This confirms the sequence set of sats contained in a UTXO through the transfer of outputs.
Note that it is each individual sat, not the UTXO! Since UTXO is the indivisible smallest transaction unit, sats can only exist within UTXO, and UTXO contains a certain range of sats, and new outputs can only split the numbering of sats after spending a certain UTXO.
As for how to express this "numbering", Ordinal supports multiple forms, such as the "integer method" mentioned above, as well as decimal, degree, percentage, and pure alphabetical naming methods.
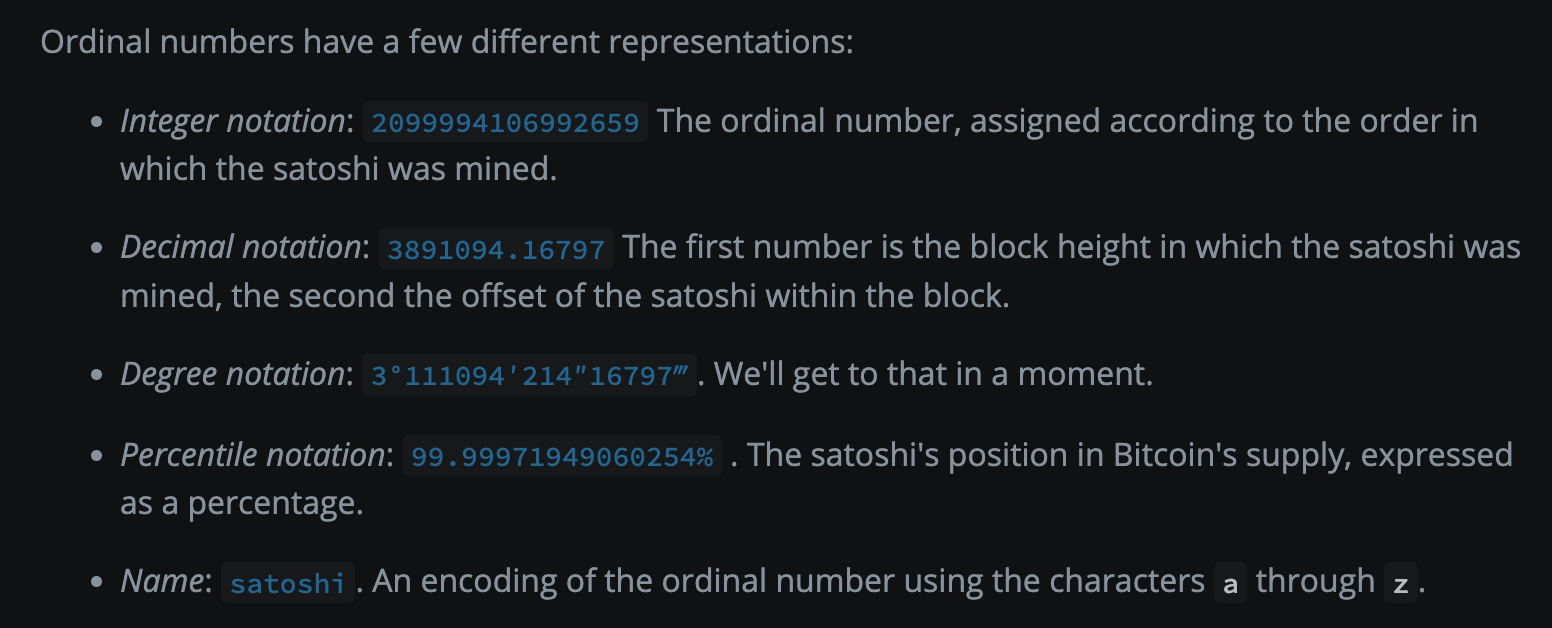
Once sats have been assigned a unified sequence number, it is possible to consider inscription. As mentioned earlier, any type of file, whether it's text, images, or videos, can be uploaded to the 4MB witness data area, and after uploading, the file will be automatically converted to hexadecimal and stored in the taproot script area. Therefore, one UTXO corresponds to one Taproot script area, and this one UTXO will simultaneously contain many sats (as a whole sequence set of sats, to prevent dust attacks, the amount of Bitcoin in a single UTXO must not be less than 546 satoshis). For the convenience of recording, the Ordinal protocol artificially stipulates "using the sequence number of the first sat in this sequence set to represent the binding relationship" (the original wording in the whitepaper is the number of the first sat of the first output), for example, the UTXO containing sats numbered (17-19) is directly represented by the number 17 to bind the set and the inscription content.
Minting and Transfer of Ordinal Assets
It is obvious that Ordinal NFT is about uploading various files to the script in the segregated witness area and binding them to a sequence set of sats, thereby issuing NFT assets on the BTC chain. However, there is a question here: the script in the segregated witness area contains both the unlocking script of the input and the locking script of the output, so where is the content placed? The correct answer is both. This brings us to the commit-reveal mechanism in blockchain technology.
The Commit-Reveal mechanism in blockchain is a protocol used to ensure fair and transparent handling of information. This mechanism is usually used in scenarios where hidden information (such as voting or bidding) needs to be submitted and then revealed at a later time. The Commit-Reveal mechanism consists of two phases: the commit phase and the reveal phase.
Commit Phase: In this phase, users submit their information (such as voting choices or bidding prices), but this information is encrypted. Typically, users generate a hash value of this information (i.e., the encrypted digest of the information) and then send this hash value to the blockchain. Due to the properties of hash functions, they can generate a unique output (hash value) that is irreversible for the original information. This means that the original information cannot be inferred from the hash value. This process ensures the confidentiality of the information at the time of submission.
Reveal Phase: At a predetermined time, users must reveal their original information and prove that it matches the hash value previously submitted. This is usually done by submitting the original information and any additional data used to generate the hash value (such as a random number or "salt"). The network then verifies whether the hash value of this original information matches the hash value previously submitted. If it matches, the original information is accepted as valid.
As mentioned earlier, the content of the inscription needs to be bound together with the sequence set of sats (UTXO) it contains. Since the UTXO is an output in the block, it must be attached to the locking script of the output. However, BTC full nodes need to maintain and transmit the entire network's UTXO collection locally. Imagine if 10,000 4MB video files were directly uploaded to the locking scripts of 10,000 UTXOs - all full nodes would require extremely high storage space and fast network speeds, which would essentially crash the entire chain. Therefore, the only solution is to put the content in the unlocking script of the input and then "point" this content to another output.
Therefore, the minting of Ordinal assets needs to be divided into two steps (wallets combine these two steps for processing, when constructing transactions, they simultaneously construct the commit-reveal parent-child transactions, providing users with the experience of only one step and saving gas fees).
In the minting phase, users first need to upload the hash value of a file to the UTXO in the commit transaction (transferring from their own address A to their own address B). Because it is a hash value, it does not occupy too much space in the UTXO database of the full node. Secondly, users then construct a new transaction (transferring from their own address B to their own address A), called the reveal transaction. At this point, the input needs to use the UTXO from the commit transaction that contains the hash value of the file, and the unlocking script of this input must contain the original inscribed file. In the words of the whitepaper, "first, in the commit, create a commitment to the script containing the inscription content. Secondly, in the reveal transaction, use the output generated by the commit transaction to display the inscription content on the chain."
In the transfer phase, Ordinal NFT is slightly different from BRC20. Ordinal NFT, being a whole transfer, only needs to directly transfer the NFT bound to a certain UTXO to the recipient, similar to a regular BTC transfer. However, BRC20, involving custom amount transfers, is also divided into two steps. The first step is called "Inscribe 'TRANSFER'", and the second step is called "Transfer 'TRANSFER'". The inscribe transaction in the first step is actually similar to the minting process of an Ordinal NFT, implying a commit-reveal parent-child transaction pair. The transfer transaction in the second step is similar to a regular transfer of an Ordinal NFT, directly transferring the BRC20 asset bound to a certain UTXO to the recipient. Some wallets will construct these three transactions (parent, child, and grandchild transactions) simultaneously, saving time and gas.

In summary, the commit transaction is used to bind the inscription content (the hash value of the original content) and the numbered sats (UTXO) together, and the reveal transaction is used to display the content (original content). This parent-child transaction pair jointly completes the minting of NFTs.
P2TR and an Example
The technical discussion about minting is not yet complete, as some may be curious about how the reveal transaction actually verifies the inscription information in the commit transaction. Why is it necessary to transfer between one's own addresses A and B when constructing the transaction? It didn't seem like two wallets were needed when inscribing. This brings us to one of the major upgrades of Taproot, P2TR (Pay-to-Taproot).
P2TR (Pay-to-Taproot) is a new type of Bitcoin transaction introduced by the Taproot upgrade. P2TR transactions allow users to spend Bitcoin using a single public key or more complex scripts (such as multi-signature wallets or smart contracts), achieving higher privacy and flexibility. This is achieved through the use of Merkleized Abstract Syntax Trees (MAST) and Schnorr signatures, which allow multiple spending conditions to be efficiently encoded in a single transaction.
- Creating Spending Conditions
To create a P2TR transaction, users first define a spending condition, such as a single public key or a more complex script, specifying the requirements for spending Bitcoin (e.g., a multi-signature wallet or a smart contract).
- Generating Taproot Output
Next, users generate a Taproot output, which includes a single public key (representing the spending condition). This public key is derived from a combination of the user's public key and the hash of the script, using a process called "tweaking". This ensures that the output looks like a standard public key, making it difficult to distinguish from other transactions on the blockchain.
- Spending Bitcoin
When users want to spend Bitcoin, they can use their single public key (if the spending condition is met) or reveal the original script and provide the necessary signatures or data to meet the spending condition. This is done using Tapscript, which allows for more efficient and flexible execution of spending conditions.
- Verifying the Transaction
Miners and nodes subsequently verify the transaction by checking the provided Schnorr signatures and data against the spending condition. If the condition is met, the transaction is considered valid, and the Bitcoin can be spent.
- Enhanced Privacy and Flexibility
Because P2TR transactions only reveal the necessary spending conditions when spending Bitcoin, they maintain a high level of privacy. Additionally, the use of MAST and Schnorr signatures allows for the efficient encoding of multiple spending conditions, enabling more complex and flexible transactions without increasing the overall size of the transaction.
The above is the application of the commit-reveal mechanism in P2TR. Let's illustrate this with an actual case.
Using the blockchain explorer https://www.blockchain.com/, let's study the minting process of an Ordinal image NFT, including the previous commit-reveal two phases.
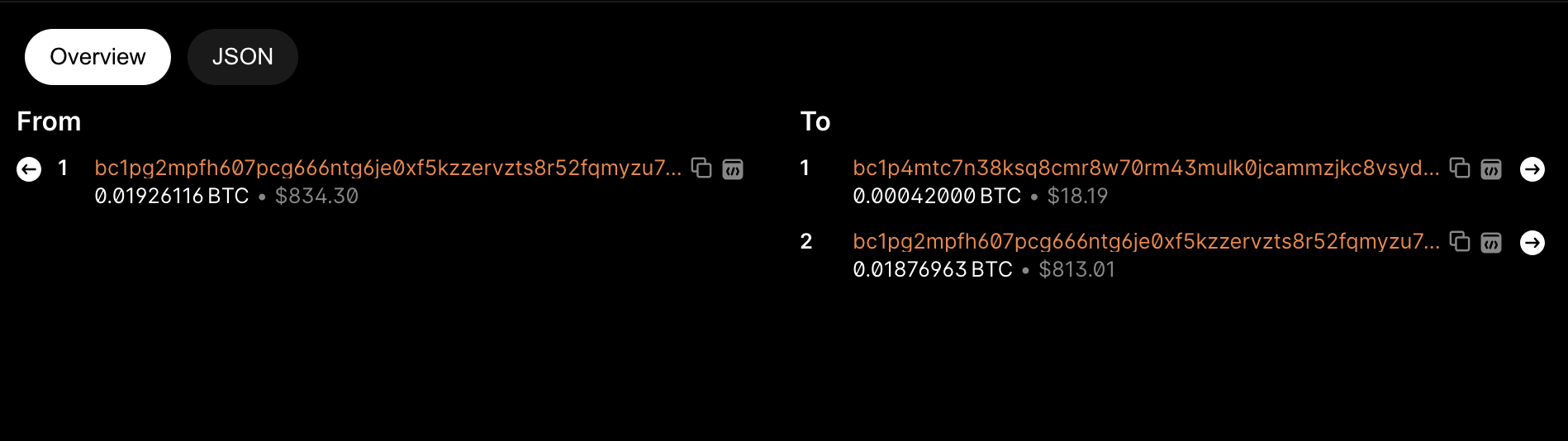
First, we see that the Hash ID of the commit transaction is (2ddf90ddf7c929c8038888fc2b7591fb999c3ba3c3c7b49d54d01f8db4af585c). It can be noted that the output of this transaction does not contain inscription data (it actually contains the hash value of the hexadecimal image file), and there is no related inscription information on the webpage. The address of this output (bc1p4mtc…..) is actually a temporary address generated through the "tweaking" process (representing the public key of the script unlocking condition) and shares the same private key as the taproot main address (bc1pg2mp…). The second UTXO in this transaction belongs to the "change" operation. This achieves the binding of the inscription content with the sats contained in the first UTXO.
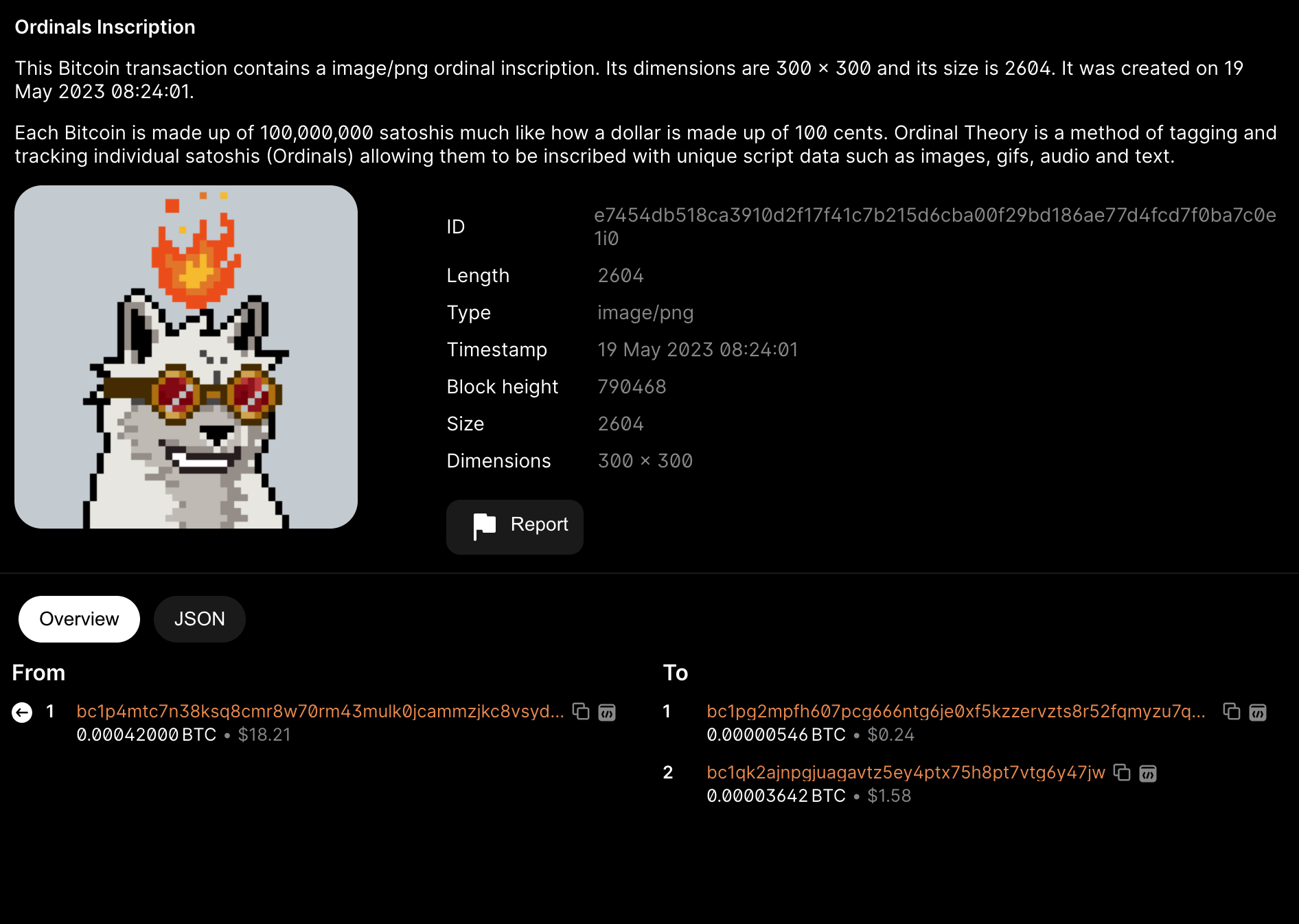
Next, we look at the record of the reveal transaction, with its Hash ID being (e7454db518ca3910d2f17f41c7b215d6cba00f29bd186ae77d4fcd7f0ba7c0e1). Here, we can see the information of Ordinal's inscription. The input address of this transaction is the temporary output address generated by the previous transaction (bc1p4mtc…..), and the unlocking script of the input contains the hexadecimal file of the original image. The output of 0.00000546 BTC (546 satoshis) is to send this NFT to the user's taproot main address (bc1pg2mp…). Based on the First in First Out principle and "binding the number of the first sat of the first output", although the quantity of sats contained in the two UTXOs has changed, the bound sat number remains the same. Therefore, we can find the inscription in (sat 1893640468329373).
(https://ordinals.com/sat/1893640468329373)
These two transactions (parent-child transactions) are simultaneously submitted to the mempool by the wallet during minting, so only one gas fee is required, and there is a high probability that they will be recorded and broadcast in the same block (the two transactions in the example above are indeed present in block 790468). Miners and nodes subsequently verify the reveal transaction by checking the Schnorr signature provided in the input and the hash value of the hexadecimal image against the hash value of the hexadecimal image in the output locking script of the commit transaction. If they match, the transaction is considered valid, and the Bitcoin UTXO can be spent, so these two transactions are naturally permanently recorded in the BTC blockchain database, and the NFT image is naturally saved and displayed. If the two hash values are different, the two transactions will be canceled, and the inscription will fail.
BRC20 Protocol and Indexer
For the Ordinal protocol, we inscribe a piece of text, and it becomes a text NFT (corresponding to Loot on Ethereum). We inscribe an image, and it becomes an image NFT (corresponding to PFP on Ethereum). We inscribe a piece of music, and it becomes an audio NFT. But what if we inscribe a piece of code, and this code is a "code for issuing FT fungible tokens"?
BRC20 uses the Ordinal protocol to set inscriptions as JSON data format to deploy, mint, and transfer tokens. The JSON contains some code snippets describing various properties of the token, such as its supply, maximum minting units, and unique code. As we discussed in the previous article, the essence of BRC20 tokens is semi-fungible tokens (SFT), which means that in some cases, it can be treated as an NFT transaction, and in some cases, it can be treated as an FT transaction. How is this control achieved? The answer is the indexer.
The indexer is essentially an accountant, used to categorize the received information and record it in the database. In the Ordinal protocol, the indexer determines the changes in the sorted sats in different addresses by tracking the input and output. In the BRC-20 protocol, the indexer has an additional function: recording the changes in token balances in different addresses within the inscription.
So, from the perspective of the accountant, we can see different forms of tokens: BRC20 protocol tokens actually exist in a triple database. The first layer, Layer1, with miners as accountants, has a "chain database" type, and the generated BTC is an FT asset. The second layer, Layer2, with the Ordinal indexer as the accountant, has a "relational database" type, and the generated numbered sats are NFT assets. The third layer, Layer3, with the BRC20 indexer as the accountant, has a "relational database" type, and the generated BRC20 assets are FT assets. When we consider BRC20 as "张" (a unit of measure), the perspective is that of the ordinal indexer (recorded by this indexer), and it is naturally an NFT. When we consider BRC20 as "个" (especially after recharging to a centralized exchange), the perspective is that of the BRC20 indexer (recorded by this indexer or the server of a centralized exchange), and it is naturally an FT. Therefore, we can conclude that the existence of semi-fungible tokens (SFT) is due to the different levels of accountants.
Blockchain is just a distributed database, which is why there are miners as a group of accountants to collectively maintain this "chain database" (because only a chain database can achieve true decentralization). However, after all the twists and turns, we still return to the old path of centralized "relational databases". This is also the fundamental reason why the initiators of the Ordinal protocol, the initiators of the BRC20 protocol, and the Unisat wallet have been at odds over whether the indexer should be upgraded - the accountants have different opinions.
But after more than a decade of development, the industry has accumulated a lot of experience in "decentralization". Can the indexer be replaced with a "chain database" instead of a relational database? Can fraud proofs or ZKP be used to ensure security and decentralization? Will the demand for DA in the Bitcoin ecosystem spill over to other DAs, thereby promoting the prosperity and integration of a multi-chain ecosystem? I seem to see more possibilities.
This article is original by @hicaptainz
References
https://www.aixinzhijie.com/books/261/master_bitcoin/_book/
https://learnblockchain.cn/article/5717
- https://zhuanlan.zhihu.com/p/361854961
- https://www.odaily.news/post/5187233
- https://learnblockchain.cn/article/5376
- https://www.panewslab.com/zh/articledetails/1301r1ibp79c.html
- https://docs.ordinals.com/inscriptions.html
- https://thebitcoinmanual.com/articles/pay-to-taproot-p2tr/
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







