Article Source: Founder Park

Image Source: Generated by Wujie AI
The Mixture of Experts (MoE) has become a recent hot topic.
First, there was a speculation post on Reddit about the structure of GPT-4, suggesting that GPT-4 might be a hybrid of 16 sub-modules of expert models (MoE). It is said that each of these 16 sub-modules of MoE has 111 billion parameters (for reference, GPT-3 has 175 billion parameters). Although it cannot be confirmed 100%, it is very likely that GPT-4 is a cluster composed of MoE.
Then, the French AI company MistralAI released the world's first large model Mistral-8x7B-MoE based on hybrid expert technology, which is a hybrid of 8 models with 7 billion parameters each.
The main features are as follows:
- It can handle 32K context data very elegantly;
- It performs well not only in English but also in French, German, Italian, and Spanish;
- It has strong coding capabilities;
- After fine-tuning, it scored 8.3 points on MT-Bench (GPT-3.5 is 8.32, LLaMA2 70B is 6.86);
Mistral-7B×8-MoE is the first proven open-source MoE LLM, which has proven that MoE can really be implemented and is far more effective than Dense models with the same activation values, compared to earlier research such as Switch Transformer and GLaM.
In a recent evaluation, Mistral-8x7B-MoE's performance after fine-tuning exceeded that of Llama2-65B.
What exactly is MoE, and will it be a new direction for training large models in the future?
Founder Park has compiled introductions to MOE from the public accounts "HsuDan" and "Deep Artificial Intelligence". For a more detailed technical interpretation, please refer to Hugging Face's official detailed technical interpretation of MoE.
01 The Past and Present of MoE
The concept of Mixture of Experts (MoE) can be traced back to ensemble learning, which is the process of training multiple models (base learners) to solve the same problem and combining their prediction results in a simple way (e.g., voting or averaging). The main goal of ensemble learning is to reduce overfitting, improve generalization, and enhance prediction performance. Common ensemble learning methods include Bagging, Boosting, and Stacking.
During the training process of ensemble learning, the training data set is used to train the base learners, and the algorithms of the base learners can be decision trees, SVM, linear regression, KNN, etc. In the inference process, for the input X, the corresponding answers from each base learner are combined in an organic way, for example, solving numerical problems by averaging the results and solving classification problems by voting.
The idea of MoE is similar to ensemble learning, as both methods integrate multiple models, but their implementation methods are quite different. The biggest difference between MoE and ensemble learning is that ensemble learning does not need to decompose tasks into subtasks, but rather combines multiple base learners. These base learners can use the same or different algorithms and can use the same or different training data.

The MoE model itself is not a completely new concept. Its theoretical basis can be traced back to a paper proposed by Michael Jordan and Geoffrey Hinton in 1991, which is more than 30 years old and is still widely used in technology. This concept has been frequently applied to practical scenarios of various models after it was proposed. In 2017, it was further developed when a team led by Quoc Le, Geoffrey Hinton, and Jeff Dean proposed a new type of MoE layer, which significantly increased the scale and efficiency of the model by introducing sparsity.
The method of combining large models with the MoE model is like an old tree sprouting new branches. With the increasing complexity and fragmentation of application scenarios, large models are becoming larger, and vertical domain applications are becoming more fragmented. It seems that MoE is a more cost-effective choice for a model that can answer general questions and solve professional domain problems. Under the wave of development of multimodal large models, MoE is likely to become a new direction for large model research in 2024, and large models will also bring MoE to greatness once again.
Below are some development events of MoE in recent years, which show that the early applications of MoE and the development of Transformers occurred around the same time in 2017.
In 2017, Google first introduced MoE into the field of natural language processing, achieving performance improvements in machine translation by adding MoE between LSTM layers;
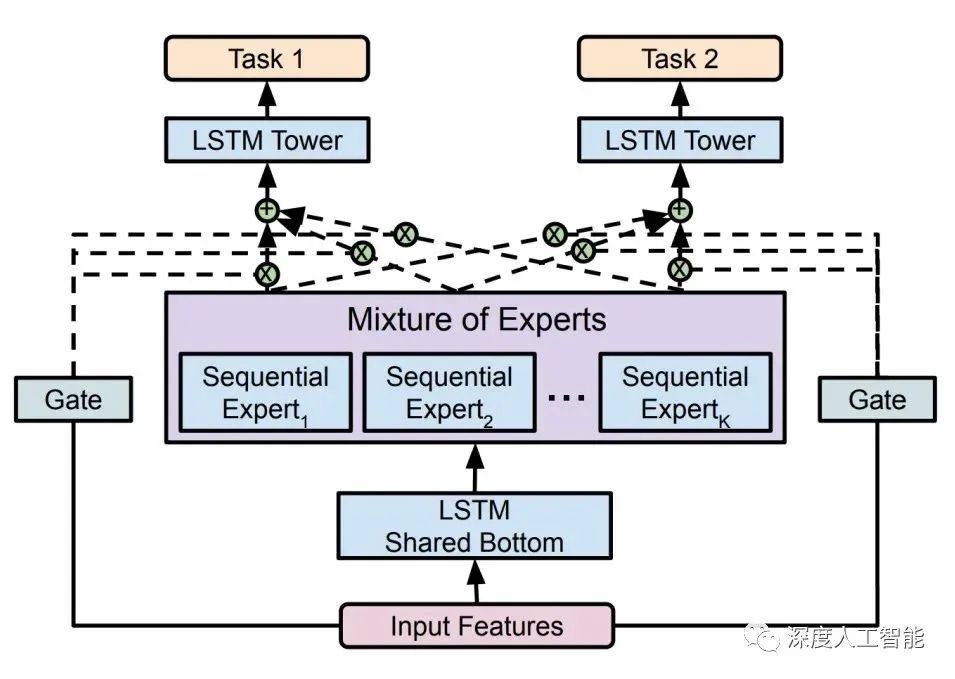
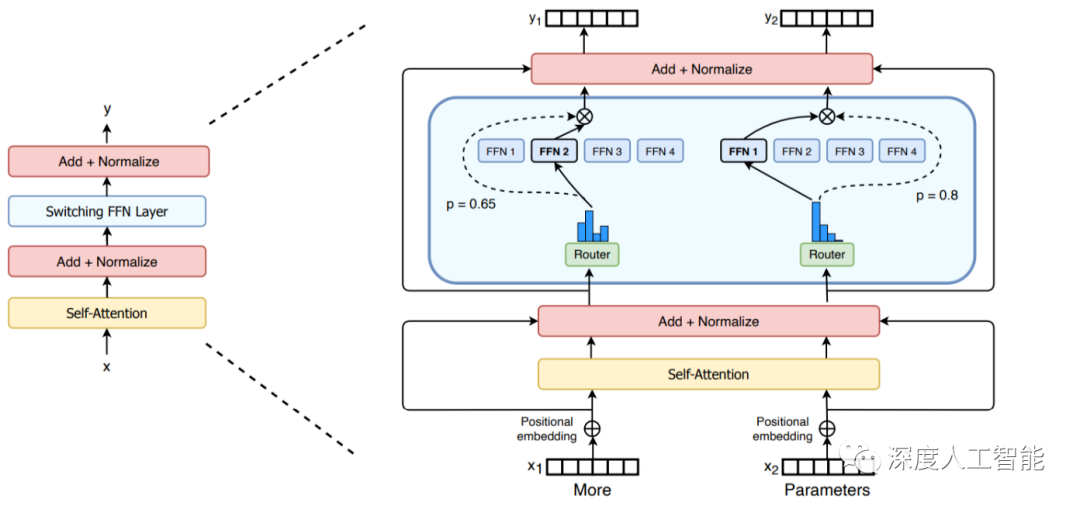
In 2020, Gshard first introduced MoE technology into the Transformer architecture and provided an efficient distributed parallel computing architecture. Subsequently, Google's Switch Transformer and GLaM further explored the potential applications of MoE technology in the field of natural language processing, achieving excellent performance;
In 2021, V-MoE applied the MoE architecture to the Transformer architecture model in the field of computer vision and achieved higher training efficiency and better performance in related tasks through improvements in routing algorithms;
In 2022, LIMoE was the first multimodal model to apply sparse Mixture of Experts model technology, and the model's performance was improved compared to CLIP.
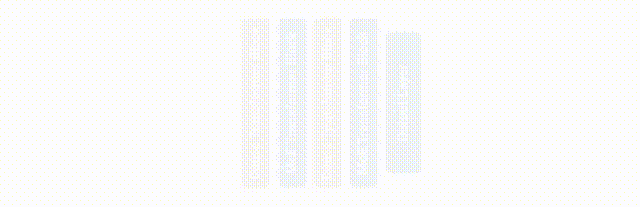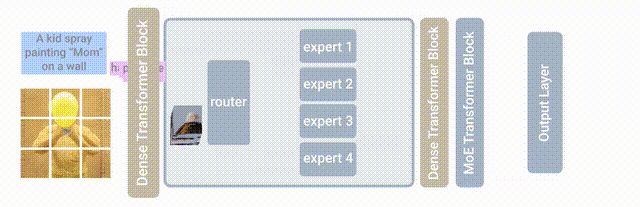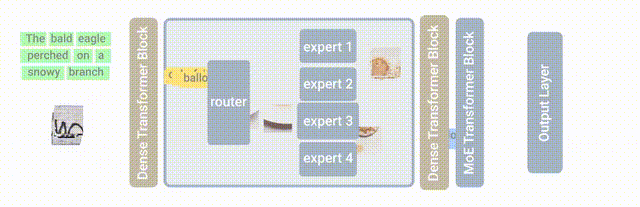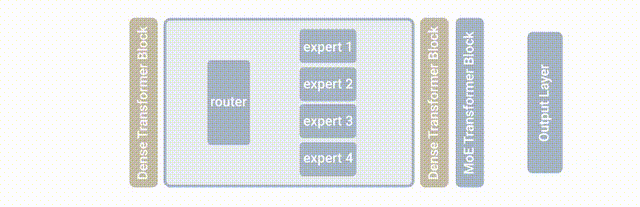
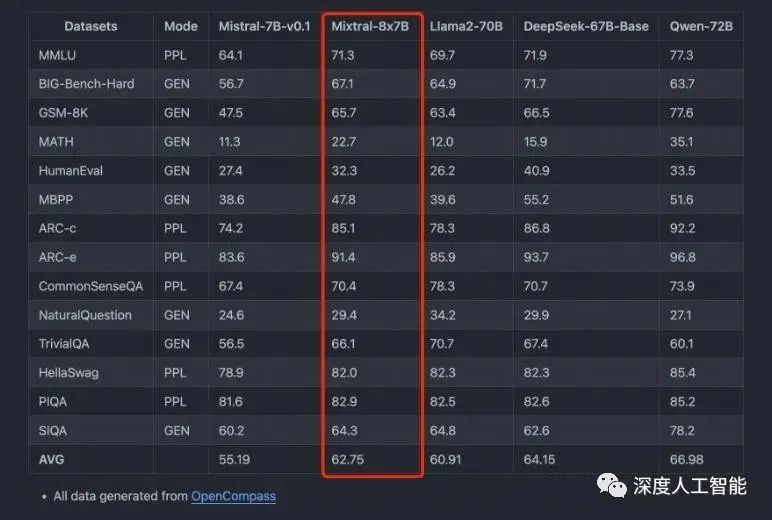
Recently, the Mistral 8x7B model released by Mistral AI is a MoE model composed of small models with 7 billion parameters, which directly outperformed the Llama 2 with as many as 70 billion parameters on multiple benchmarks.
Applying the Mixture of Experts (MoE) to large models seems to be a good idea. The Mistral 8x7B model released by Mistral AI has proven this point in various aspects of performance and parameters. It uses fewer parameters but achieves far better results than Llama 2, providing a new approach for the development of large models.
02 The Core Idea of MoE: Specialization in Skills
The ancient saying "everyone has their own strengths and skills" has long taught us how to simplify complex things. The development of large models has evolved from handling only text data in the early days to the need to handle both image and speech data, leading to increasingly complex and large model parameter quantities and structure designs.
If a single-modal large model is a "specialized student," then a multi-modal large model is an "all-around genius." To help this "all-around genius" learn better, its learning tasks need to be classified, and different subject teachers need to be assigned to guide the learning tasks, so that it can efficiently and quickly learn knowledge in various subjects and achieve outstanding performance in various subjects during exams.
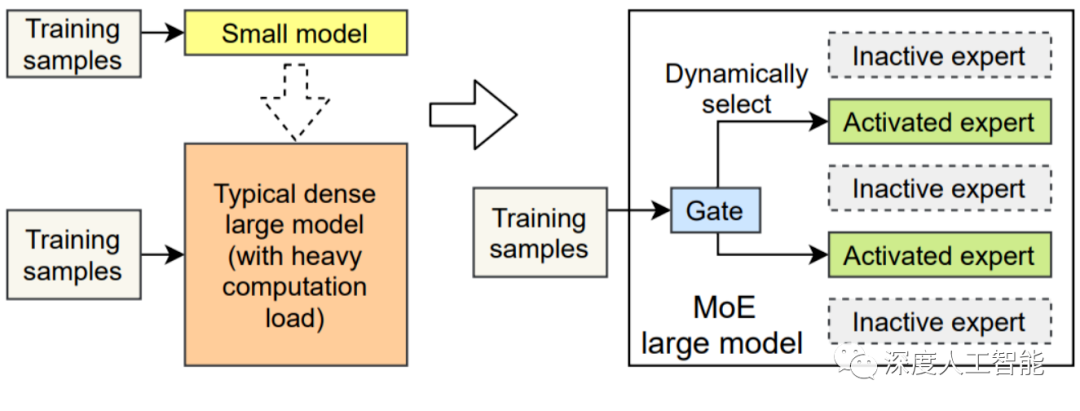
The Mixture of Experts (MoE) is a method to cultivate an "all-around genius." Its core idea is to categorize tasks and then assign them to various "expert models" for resolution. MoE is a sparse-gated deep learning model, mainly composed of a group of expert models and a gating model. The basic idea of MoE is to divide the input data into multiple regions based on the type of task and assign one or more expert models to each region. Each expert model can focus on processing this part of the input data, thereby improving the overall performance of the model.
The basic principle of the MoE architecture is very simple and clear, consisting of two core components: GateNet and Experts. The role of GateNet is to determine which expert model should take over the processing of the input sample. The Experts form a group of relatively independent expert models, each responsible for processing specific input subspaces.
Gating Model (GateNet): In the Mixture of Experts model, the "gate" is a sparse gate network that takes a single data element as input and outputs a weight, representing the contribution of each expert model to processing the input data. Generally, the gate control function models the probability distribution for experts or tokens using softmax and selects the top K. For example, if the model has three experts, the output probabilities might be 0.5, 0.4, and 0.1, meaning that the first expert contributes 50% to processing this data, the second expert contributes 40%, and the third expert contributes 10%. At this point, K can be chosen as 2, indicating that the recommendations of the first two expert models would be better for more precise answers, while the recommendation of the third expert model could be used for more creative answers.
Expert Models (Experts): During training, the input data is allocated to different expert models by the gating model for processing. During inference, the selected expert model generates the corresponding output for the input data. These outputs are then weighted and combined with the ability allocation of each expert model to process that feature, forming the final prediction result.
The Mixture of Experts model achieves "teaching in accordance with the student's aptitude" during the training process through the gating model, and then achieves "learning from the strengths of many" among expert models during inference. The expert models of MoE can be small MLPs or complex LLMs.
In traditional dense models, each input must go through the complete calculation process, leading to significant computational costs when processing large-scale data. However, in modern deep learning, the introduction of sparse Mixture of Experts (MoE) models provides a new approach to solving this problem. In this model, input data only activates or utilizes a few expert models, while the other expert models remain inactive, forming a "sparse" structure. This sparsity is considered an important advantage of the Mixture of Experts model, not only reducing computational burden but also improving model efficiency and performance.
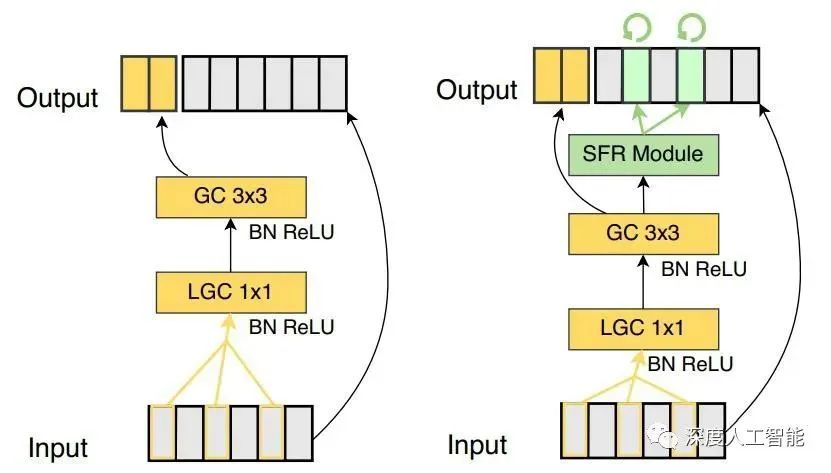
The advantage of the MoE model lies in its flexibility and scalability. Because the number and type of expert networks can be dynamically adjusted, the MoE model can effectively handle large and complex datasets. In addition, by parallel processing different expert networks, the MoE model can also improve computational efficiency.
In practical applications, the MoE model is often used to handle tasks that require a large amount of computational resources, such as language models, image recognition, and complex prediction problems. By decomposing large problems into smaller, more manageable sub-problems, the MoE model can provide more efficient and accurate solutions.
03 Advantages and Disadvantages of MoE
The advantages of the Mixture of Experts model are obvious. By using the MoE approach, the research and development of large models can be greatly promoted. However, its various issues should not be overlooked, and a balance of performance and parameters in various aspects should be considered in practical applications.
Advantages of the Mixture of Experts (MoE) model:
The Mixture of Experts (MoE) model has various advantages, making it widely used in the field of deep learning. Here are some of the advantages of the Mixture of Experts model:
1. Task Specificity: The use of the Mixture of Experts method can effectively make full use of the advantages of multiple expert models, each of which can specialize in handling different tasks or different parts of the data, achieving superior performance in handling complex tasks. Each expert model can model different data distributions and patterns, significantly improving the model's accuracy and generalization ability, allowing the model to better adapt to the complexity of tasks. This task specificity makes the Mixture of Experts model perform well in handling multimodal data and complex tasks.
2. Flexibility: The Mixture of Experts method demonstrates outstanding flexibility, allowing the flexible selection and combination of suitable expert models based on the needs of the task. The model's structure allows for the dynamic selection of activated expert models based on the task's requirements, enabling flexible processing of input data. This allows the model to adapt to different input distributions and task scenarios, improving the model's flexibility.
3. Efficiency: With only a few expert models being activated and most models remaining inactive, the Mixture of Experts model exhibits high sparsity. This sparsity leads to improved computational efficiency, as only specific expert models process the current input, reducing computational costs.
4. Performance: Each expert model can be designed to be more specialized, better capturing patterns and relationships in the input data. By combining the outputs of these experts, the overall model's ability to model complex data structures is enhanced, thereby improving the model's performance.
5. Interpretability: Because each expert model is relatively independent, the model's decision-making process is easier to explain and understand, providing higher interpretability for users. This is particularly important for applications with strong requirements for explaining the model's decision-making process.
The MoE architecture can also add learnable parameters to LLM without increasing the inference cost.
6. Adaptation to Large-Scale Data: The Mixture of Experts method is an ideal choice for handling large-scale datasets, effectively addressing the challenges of massive data volume and complex features. It can efficiently utilize sparse matrix calculations and leverage the parallel computing capabilities of GPUs to compute all expert layers, effectively addressing the challenges of massive data and complex features. Its parallel processing of different sub-tasks fully utilizes computing resources, helping to effectively expand the model and reduce training time, improving the efficiency of the model in both training and inference stages. This makes it highly scalable in large-scale data environments, obtaining better results at lower computational costs. This advantage makes the Mixture of Experts method a powerful tool for deep learning in big data environments.
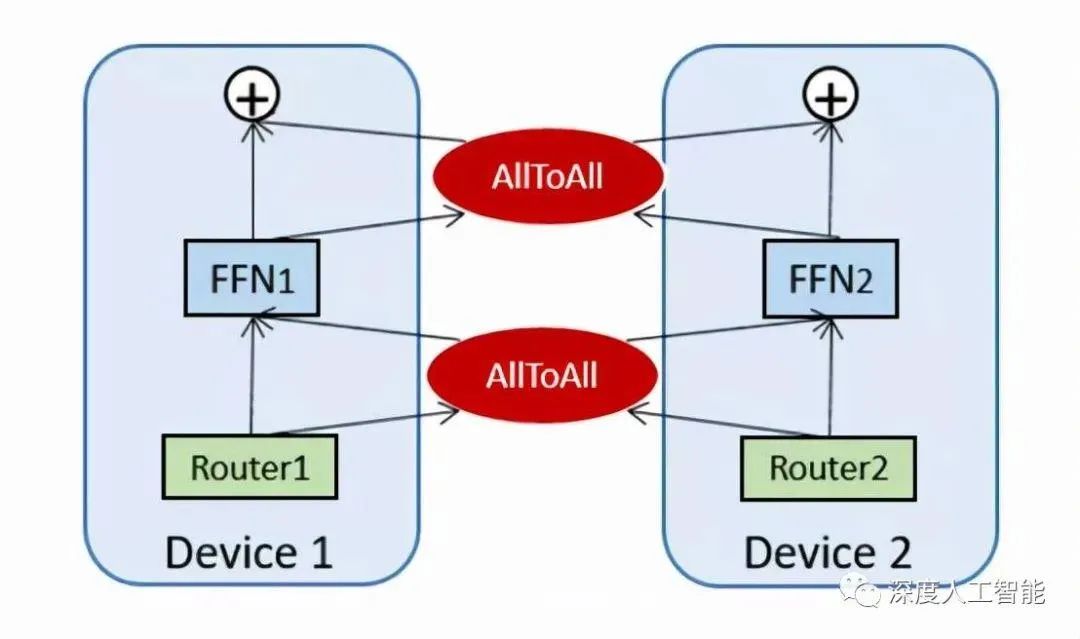
By fully utilizing the advantages of multiple expert models, the Mixture of Experts model achieves a balance in task processing, flexibility, computational efficiency, and interpretability, making it an effective tool for handling complex tasks and large-scale data.
Issues with the Mixture of Experts (MoE) model:
Although the Mixture of Experts model has many advantages, it also faces some issues and challenges that need to be carefully considered in practical applications. Here are some potential problems the Mixture of Experts model may face:
Additionally, an important point is that the Mixture of Experts model may face communication bandwidth bottlenecks in a distributed computing environment. This mainly involves the distributed deployment of the Mixture of Experts model, where different expert models or gating networks may be distributed across different computing nodes. In this case, the transmission and synchronization of model parameters may lead to excessive communication overhead, becoming a bottleneck for performance.
04 Rough Reading of MoE-Related Papers
MoE-Related Papers
- Adaptive mixtures of local experts, Neural Computation'1991
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, ICLR'17
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding, ICLR'21
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, JMLR'22
- GLaM: Efficient Scaling of Language Models with Mixture-of-Experts, 2021
- Go Wider Instead of Deeper, AAAI'22
- MoEBERT: from BERT to Mixture-of-Experts via Importance-Guided Adaptation, NAACL'22
Paper 3 GShard is the first work to extend the MoE concept to Transformers. The highlight of the paper is the introduction of the GShard framework, which can easily perform data parallelism or model parallelism on the MoE structure.
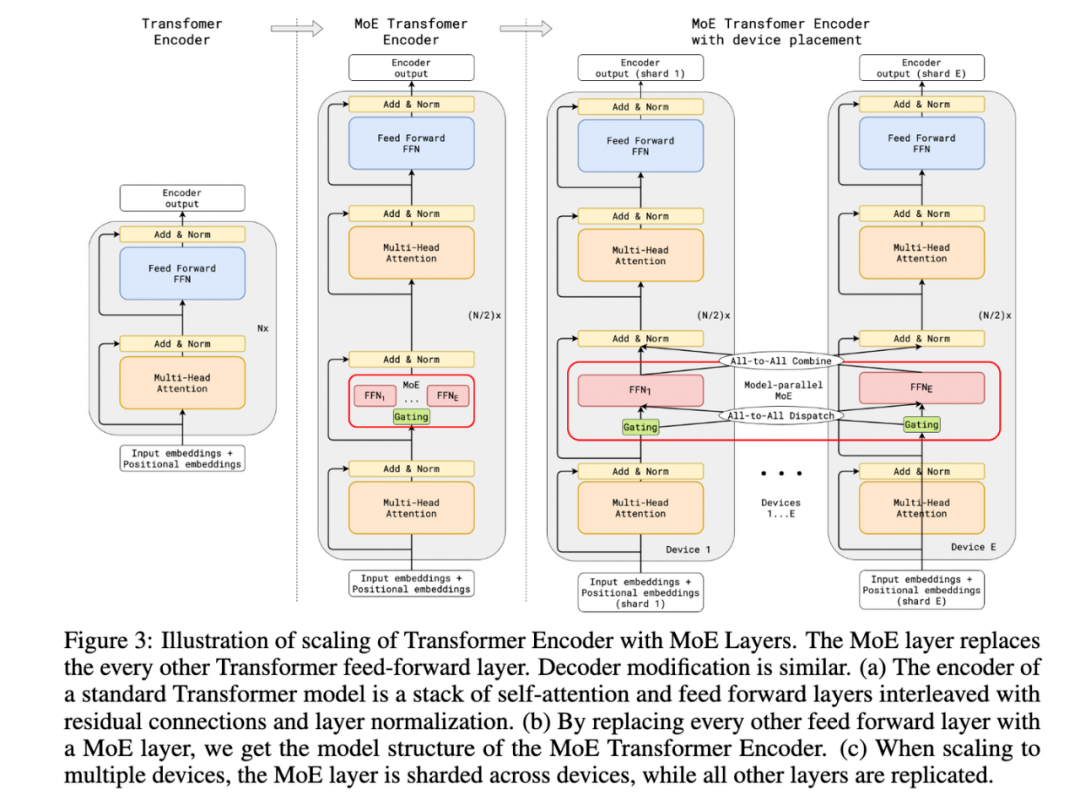
We can focus on the proposed MoE structure, where the specific approach in the paper is to replace every other FFN layer in the encoder and decoder of the Transformer with a position-wise MoE layer, and add a dispatcher (Gating) using the Top-2 gating network, meaning that different tokens are assigned to at most two experts each time.
The paper also mentions many other designs:
- Expert capacity balancing: Forcing the number of tokens processed by each expert to be within a certain range.
- Local group dispatching: Parallelizing calculations by grouping all tokens in a batch.
- Auxiliary loss: Also to alleviate the "winner takes all" problem.
- Random routing: Efficient routing for two experts under the Top-2 gating design.
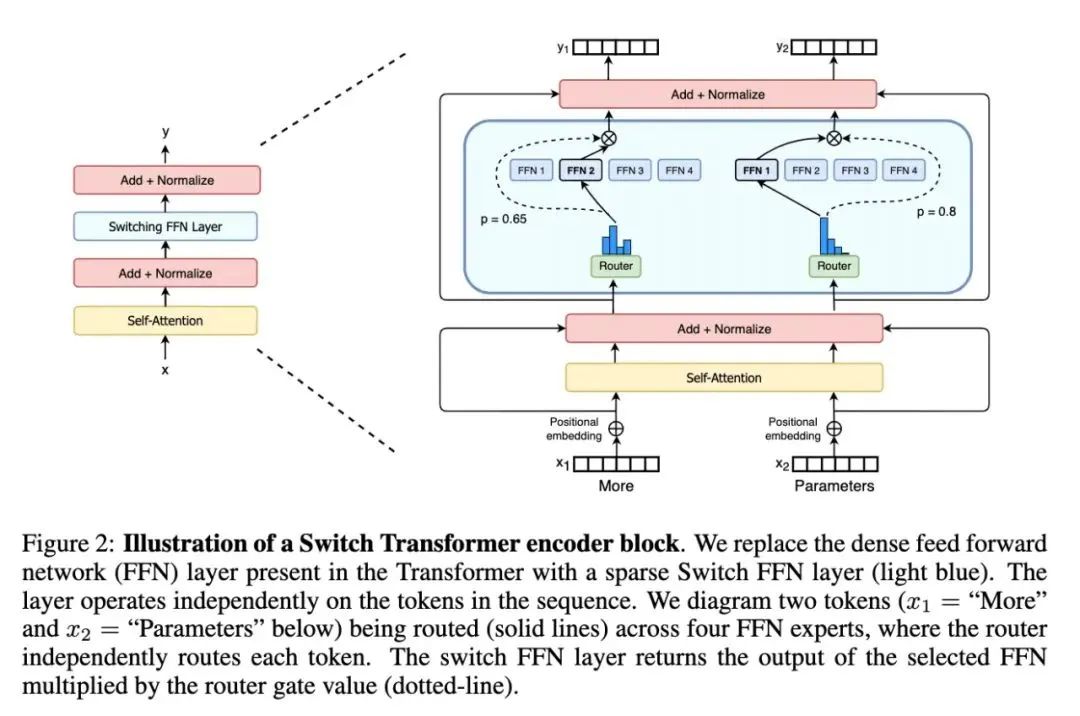
The highlight of Paper 4 Switch Transformer is the simplification of the MoE routing algorithm, where the number of activated experts for each FFN layer changes from multiple to one, improving computational efficiency and allowing the expansion of language model parameters to 1.6 trillion.
Paper 5 GLaM is a super-large model introduced by Google in 2021, three times larger than GPT-3, but due to the use of Sparse MoE design, the training cost is only one-third of GPT-3's, and it surpasses GPT-3 in 29 NLP tasks.
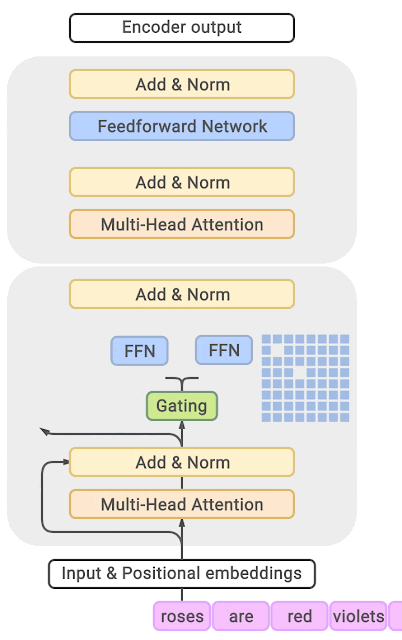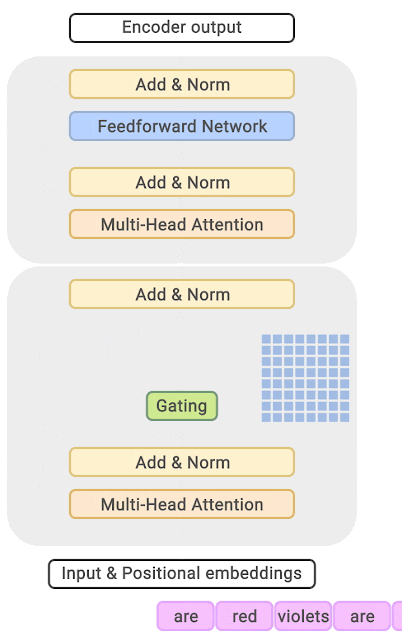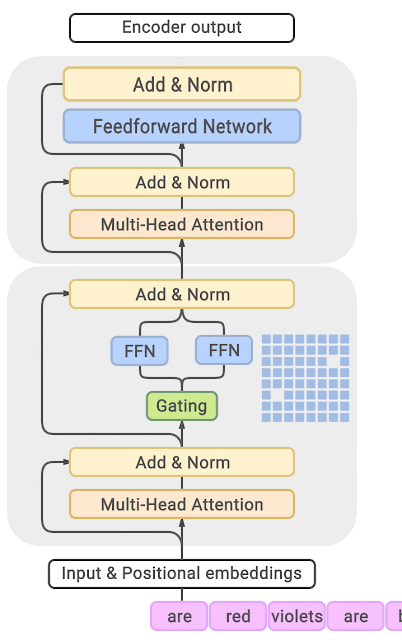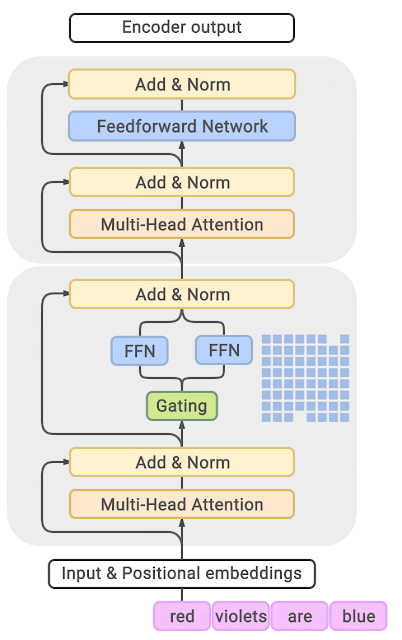
The above three papers (GShard, Switch-Transformer, GLaM) all aim to make the model as large as possible through the MoE method, to the point where ordinary people cannot afford it (often using hundreds of experts).
However, there are also more user-friendly approaches, Papers 6 and 7 are about how to use MoE to compress models and improve efficiency.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






