Source: GenAI New World

Image Source: Generated by Wujie AI
Oh no, another big model that can understand my ID card?
Recently, Yang Zhilin's startup company Moonshot AI released a new version model moonshot-v1-20231225.
The long-awaited Kimi Chat is finally here.

Image Source: Kimi Chat
Upon opening Kimi Chat, it seems that its response speed is faster than before, and a light mode has been added to the web version (Moon's bright side?). But most importantly, it can now read PDF scans!
What does this mean? If I send it a photo of my ID card, it can directly extract my home address for me. If you want it to organize information into a table by name, date of birth, etc., it can do it quite neatly.
Moonshot AI describes it as follows:
- We have implemented the function of extracting text from scans (documents, contracts, whiteboards, etc.). Currently, it supports the upload and parsing of PDF format scan files.
- For example, it can extract handwritten content from whiteboards.
In a demonstration video, a user sent Kimi Chat a sketch introducing its new feature, and then Kimi Chat looked at the handwritten sketch and directly converted it into an information table.
Before this, Kimi Chat's persona was "long," able to read 200,000 Chinese characters in one breath. Now it can read scans, papers, manuscripts, pirated books (not really), expanding its capabilities.
To put it this way, the company that started with the all-around scanning last year had a revenue of 1 billion, and this year it is going to be listed on the Shanghai Stock Exchange.
But whether this ability is as good as it sounds, it needs to be tested. I first threw a scan of the "Measures for the Regulation of the System of Lawyers' Investigation Orders by the Zhejiang High People's Court" released by the Zhejiang High People's Court to it, and Kimi Chat was able to help me understand the general content of this 20-page document quite well:

Image Source: Kimi Chat
Then I continued to ask, what is written in Article 5 under the directory of "Measures for the Regulation of the System of Lawyers' Investigation Orders by the Zhejiang High People's Court." First, the answer:

Image Source: "Measures for the Regulation of the System of Lawyers' Investigation Orders"
Kimi Chat found the exact location, didn't answer completely the first time, but got it all right the second time:
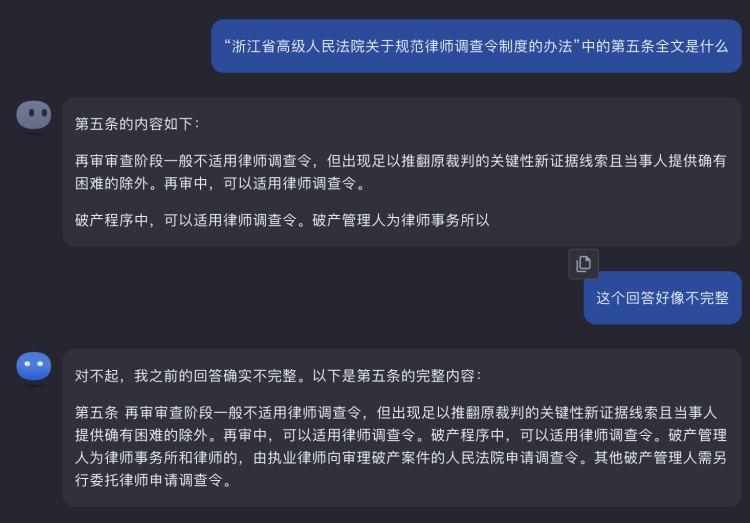
Image Source: Kimi Chat
The serious testing ends here. Then I gave it a manuscript posted by an Instant user @我有猫之狸宝儿de麻麻, asking it to help me organize it into a clearer table:
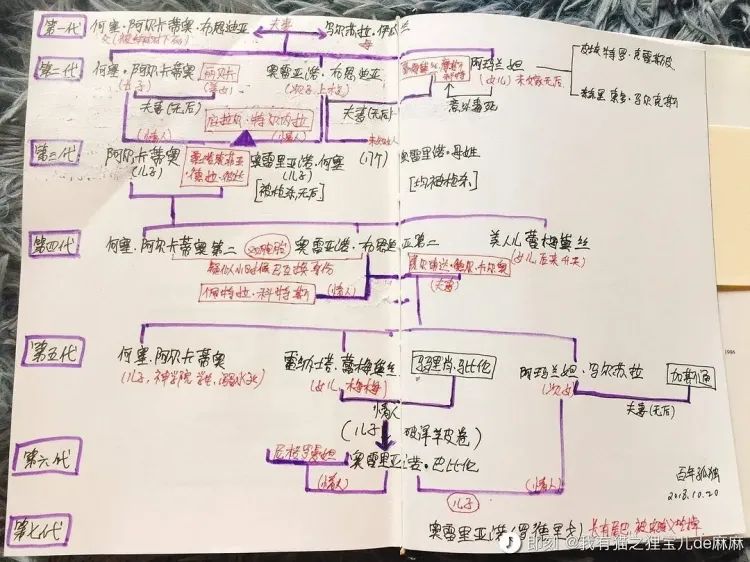
Image Source: Instant user @我有猫之狸宝儿de麻麻
What is written in this manuscript, surely some people can tell at a glance. If not, try following Kimi Chat's train of thought:
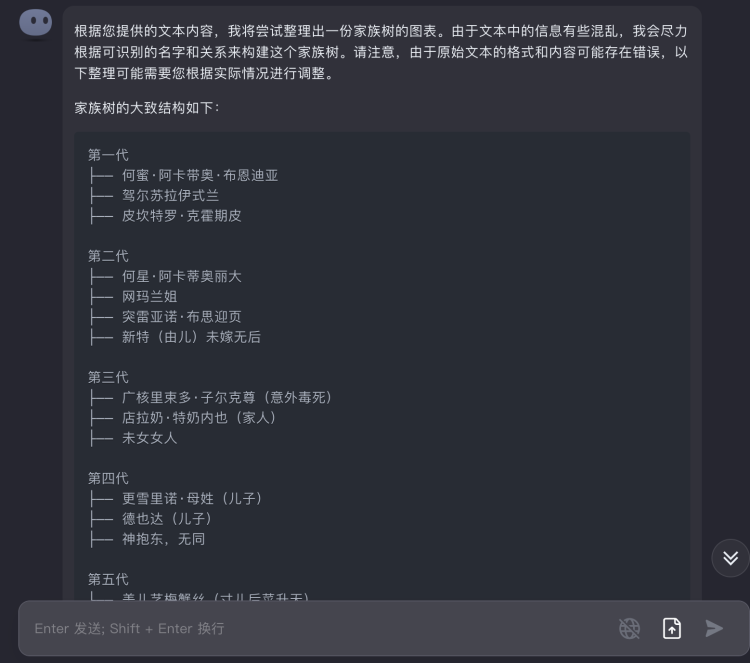
Image Source: Kimi Chat
It immediately recognized this as a family tree, and then I continued to ask it how to understand this family tree. To my surprise, it had already vaguely judged that this is a fictional family in a literary work, and saw the complexity of generational inheritance and even some tragic elements within it.
Reasonably guessing, Kimi Chat may have already completed some searches behind the scenes for these names, but where this family tree comes from, it did not make a judgment:
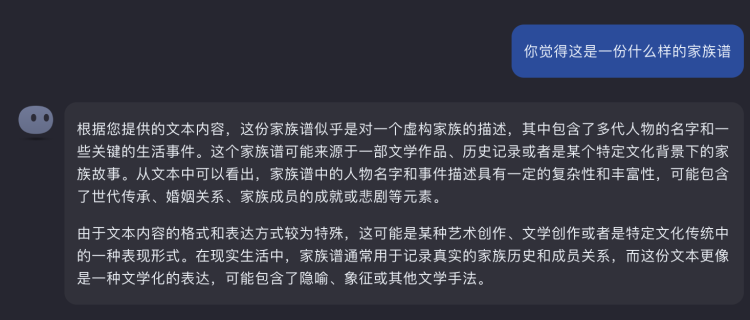
Image Source: Kimi Chat
However, when I told it that this family tree comes from a "literary masterpiece," with this key qualifier, it completely deduced the accurate answer (I suspect it already knew)—"One Hundred Years of Solitude":

Image Source: Kimi Chat
At this point, some people may have doubts. For a large model, what is the difference between reading images (JPEG) and reading PDFs, and which is more difficult?
I asked GPT-4 this question. For GPT-4 or all text-based large models, processing PDF files is more direct and simple than processing JPEG files. Here is GPT-4's response:
For a large language model like GPT-4, processing JPEG files and PDF files are technically significantly different and have different levels of difficulty.
Processing JPEG files:
- GPT-4 itself is a text-based model and does not directly process image data. Therefore, for image files like JPEG, GPT-4 cannot directly interpret the image content.
- To have GPT-4 process JPEG files, the image content needs to be converted into a textual description first. This usually involves using computer vision models to recognize elements in the image and convert them into a textual description, which can then be processed by GPT-4.
Processing PDF files:
- Processing PDF files is relatively more direct for GPT-4 because PDF files usually contain a large amount of textual content. GPT-4 can process this textual information, understand it, generate responses, or perform other text-related tasks.
- However, if the PDF file contains images, tables, or complex formatting, these non-text elements may be difficult for GPT-4 to directly process. In such cases, OCR technology may be needed to convert non-text content into text, or specific formatting processing may be required to effectively utilize GPT-4.
So, in terms of difficulty, for large language models, directly processing PDF files falls within the model's direct capabilities, while processing JPEG files requires the intervention of multimodal capabilities, making the entire process more complex and convoluted.
This also explains why when I tried to give Kimi Chat an image, it seemed to still be using the logic of reading "documents" to understand the image. I took a picture of a Manner coffee cup, and the image looks like this:

Image Source: Oil and Vinegar
Kimi Chat completely understood the text on this cup sleeve and inferred from these words that this object is used for cups or drinks in a coffee or beverage shop:

Image Source: Kimi Chat
However, it cannot recognize the pattern, so it cannot identify whether this is a cup sleeve from a coffee shop or a milk tea shop—it seems to instinctively skip the symbolic part. But when I gave it a little "observe the symbols in the picture" inclination, it started to focus on the graphic part of the image, and eventually—found the word "Manner" in the Manner logo:
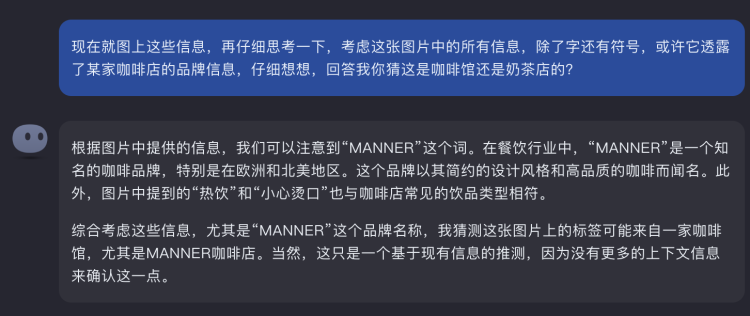
Image Source: Kimi Chat
Bingo!
Kimi Chat is exhausted, just like the coffee that has gone cold.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







