Source: Quantum Bit

Image Source: Generated by Wujie AI
Originally, it used to require a 16,000 yuan 80G A100 to do the job, but now a less than 20,000 yuan 24G 4090 is enough!
The open-source inference framework PowerInfer launched by the IPADS Laboratory of Shanghai Jiao Tong University has accelerated the inference speed of large models by 11 times.
Moreover, without quantization, using FP16 precision can also allow a 40B model to run on a personal computer; if quantized, a 2080 Ti can smoothly run a 70B model.

By combining the unique features of large models and hybrid computing between CPU and GPU, PowerInfer can achieve fast inference on personal computers with limited memory.
Compared to llama.cpp, PowerInfer has achieved up to 11 times acceleration, allowing a 40B model to output ten tokens per second on a personal computer.
Our familiar ChatGPT, on the one hand, may crash due to excessive traffic, and on the other hand, there are data security issues.

Open-source models can better solve these two problems, but running speed is often very slow without high-performance graphics cards:
The emergence of PowerInfer just happens to solve this pain point.
The release of PowerInfer has caused a strong response, gaining 500+ stars in less than 24 hours, including one from the author of llama.cpp, Gerganov.
Currently, the source code and paper of PowerInfer have been publicly released. Let's take a look at how strong its acceleration effect is.
Inference Speed Increased by Up to 11 Times
On a consumer-grade hardware platform equipped with x86 CPU and NVIDIA GPU, PowerInfer conducted end-to-end inference speed tests on a series of LLM models with parameter sizes ranging from 7B to 175B as the baseline, and compared the performance of PowerInfer with the best-performing inference framework llama.cpp on the same platform.
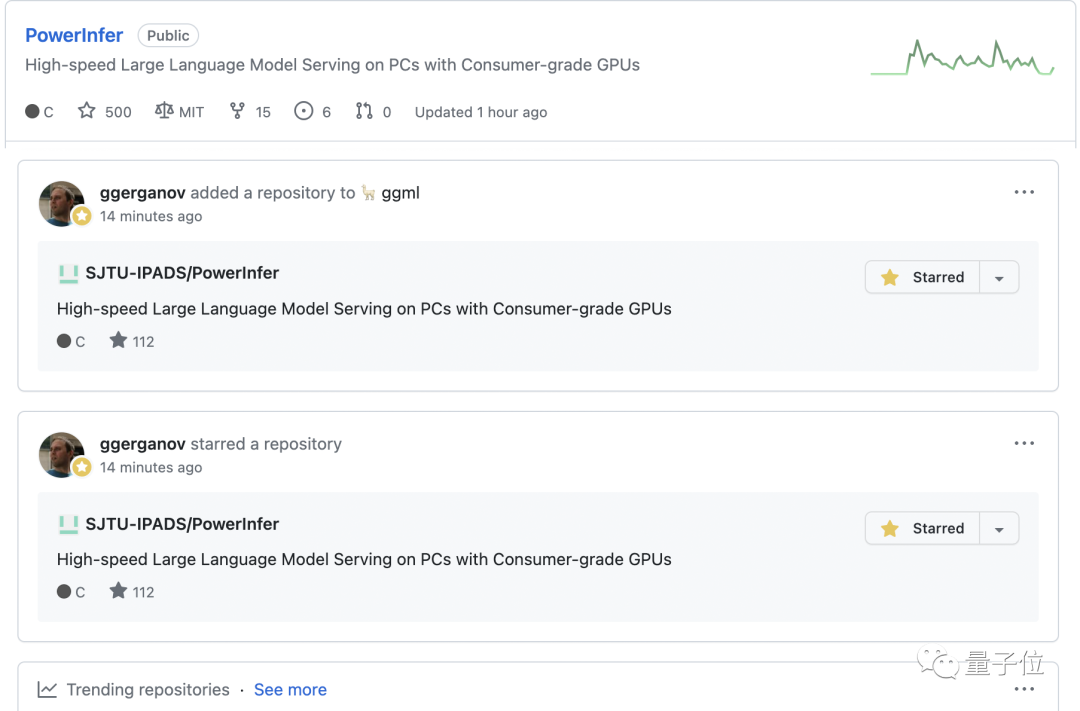
For FP16 precision models, on a high-end PC (PC-High) equipped with 13th generation Intel Core i9 and a single RTX 4090, PowerInfer achieved an average speed increase of 7.23 times, with a high of 11.69 times speed increase on Falcon 40B.
Across all test cases, PowerInfer achieved an average of 8.32 tokens/s, reaching a maximum of 16.06 tokens/s on OPT 30B and 12.94 tokens/s on Falcon 40B.
With PowerInfer, today's consumer-grade platforms can smoothly run LLM models at the 30-40B level and run 70B level LLM models at an acceptable speed.
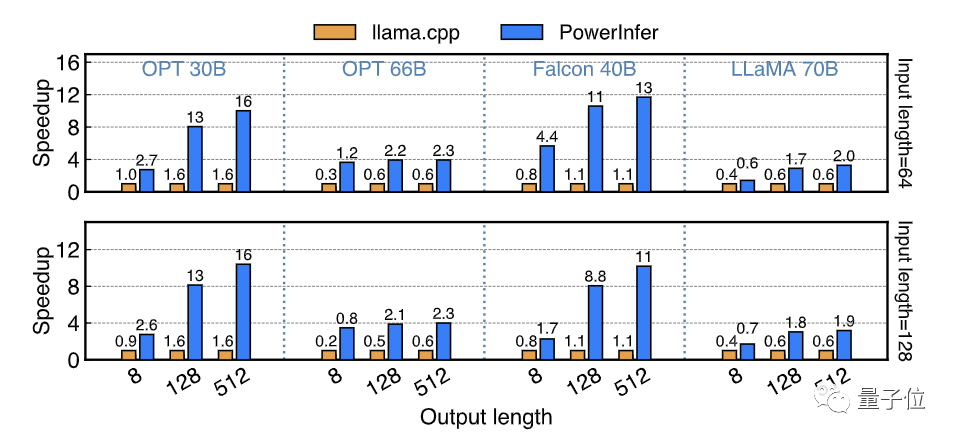
Model quantization is a commonly used technique for edge-side LLM inference, and PowerInfer also supports the inference of INT4 quantized models.
PowerInfer tested a series of INT4 quantized models on a high-end PC (PC-High) and a mid-low-end PC (PC-Low) equipped with a single RTX 2080Ti.
On PC-High, PowerInfer can run models of 40-70B scale at high speed, reaching a maximum inference speed of 29.09 tokens/s, and achieving an average speed increase of 2.89 times, with a maximum of 4.28 times.
At the same time, running models of the OPT-175B scale on consumer-grade hardware has also become possible.
On PC-Low, a mid-low-end PC, PowerInfer can smoothly run models of 30-70B scale, achieving an average speed increase of 5.01 times, with a maximum of 8.00 times, mainly due to the placement of most hot neurons in the video memory after INT4 quantization.
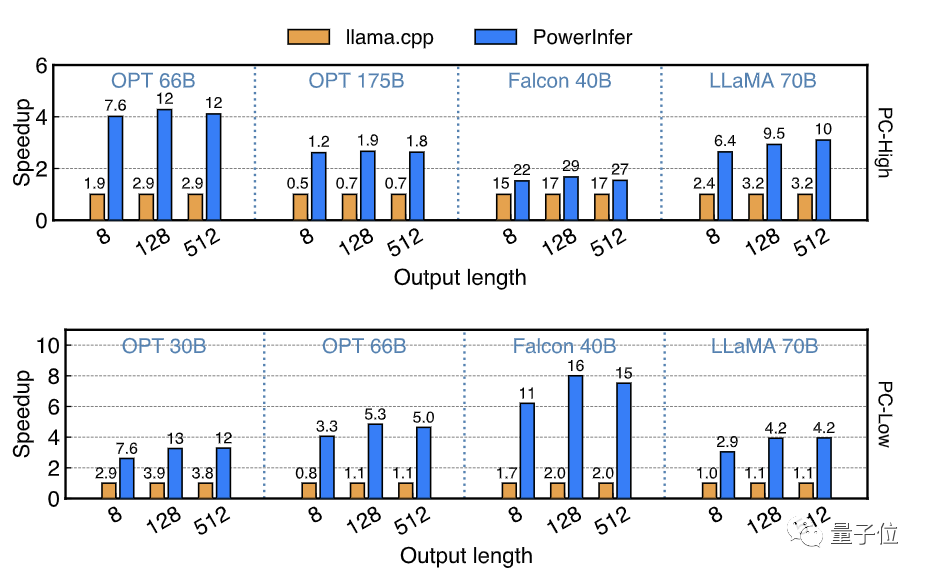
Finally, PowerInfer compared the end-to-end inference speed of PowerInfer running on PC-High with the top-level cloud computing card A100 running the SOTA framework vLLM, for FP16 precision models OPT-30B and Falcon-40B(ReLU).
When the input length is 64, the speed gap between PowerInfer and A100 narrowed from 93%-94% to 28%-29%; in a pure generation scenario with an input length of 1, this gap will be further reduced to as low as 18%.
This means that with the help of sparse activation and CPU/GPU hybrid inference, PowerInfer greatly bridges the speed gap between consumer-grade graphics cards and top-tier server computing cards.
So, how does PowerInfer achieve high-speed inference on consumer-grade hardware?
Fully Utilizing Model and Hardware Characteristics
The secret to PowerInfer's high-speed inference lies in fully utilizing the high local sparsity of dense models and combining it with the computational characteristics of CPU and GPU.
What is "Sparse Activation"?
Recently, the Mixtral MoE large model has caused a sensation in the AI community, bringing sparse models back into everyone's view.
An interesting fact is that LLMs considered as dense models, such as OPT and LLaMA(ReLU), also exhibit sparse activation features.
What is sparse activation in dense models?
Similar to the MoE model, where only one or two expert modules in the FFN layer need to be activated for each input token, in the case of the dense FFN layer of the OPT model, only a small portion (approximately 10% according to experiments) of neurons need to be activated to ensure the correctness of the output.
Although other neurons participate in the computation, they do not significantly contribute to the output.
In other words, each neuron in the dense model is an expert!
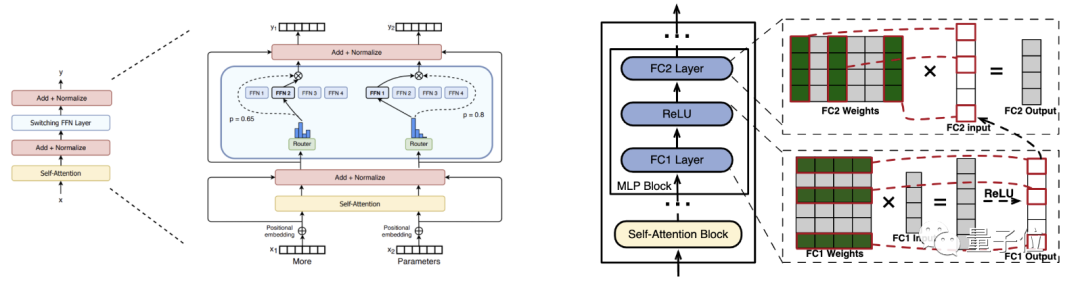
The MoE model can distribute inputs to one or two expert modules for computation through a routing module before the expert FFN layer. So, how can sparse activation in dense models be routed or known which expert neurons will contribute to the result before computation?
The answer is to add a routing prediction module to the dense model.
Before the model starts serving, PowerInfer first conducts offline analysis of the model by inferring the correspondence between each layer's input and activated neurons in a general dataset. Then, a small predictive routing module is trained for each layer of the dense model to predict which neurons will be activated for each input, and only the neurons activated by the routing are computed (the experts).
In testing across multiple downstream tasks, PowerInfer's routing module introduced almost no additional accuracy loss.
Inference Locality from Sparse Activation
Another interesting fact about sparse activation is that, although the distribution of activated neurons varies for different input tokens, when inferring on a sufficient amount of data and overlaying the distribution of activations each time, PowerInfer found that a small number of neurons are generally activated at a higher probability.
In other words, statistically, the activation of neurons in large models follows a Power Law distribution (Power Law distribution is a statistical pattern that indicates the frequency of occurrence of a few events is much higher than that of many other events).
As shown in the following figure (a), for the OPT-30B and LLaMA(ReGLU)-70B models, statistically, 26% and 43% of neurons respectively contributed to 80% of the activation.
On the scale of the entire model, as shown in the following figure (b), 17% and 26% of neurons contributed to 80% of the activation.
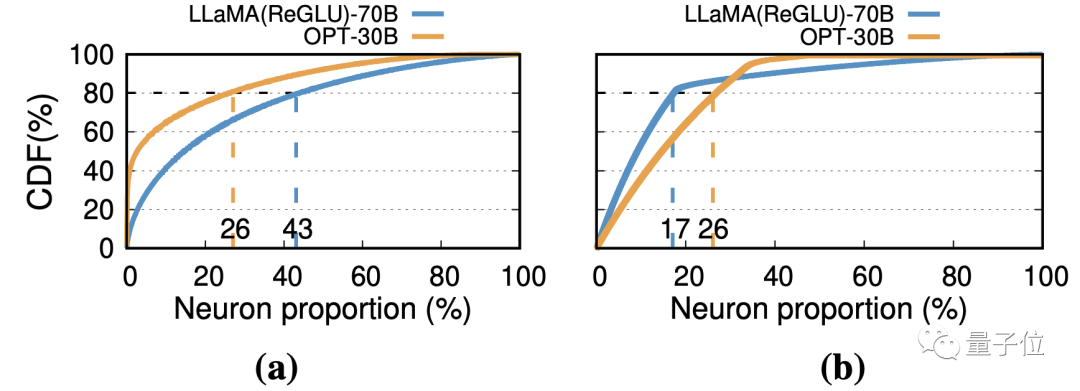
Therefore, when considering the computation that contributes to the final activation, LLM exhibits inference locality: access to weights tends to concentrate in a certain area, rather than being uniformly distributed across all neurons.
In inference computation, this manifests as program locality: access to memory space tends to concentrate in a certain area, rather than being uniformly distributed across the entire memory space.
In common personal computers, GPUs have less video memory and stronger computing power, suitable for handling tasks with frequent access and high computational intensity; while CPUs have larger memory capacity but relatively weaker computing power, suitable for handling tasks with low access and computational intensity.
Therefore, ideally, a small portion of frequently accessed neurons should be stored in video memory, while larger, less frequently accessed neurons are more suitable for storage in memory and computation by the CPU.
This inspired the design of PowerInfer's CPU/GPU hybrid inference system based on locality features.
Design of CPU/GPU Hybrid Inference
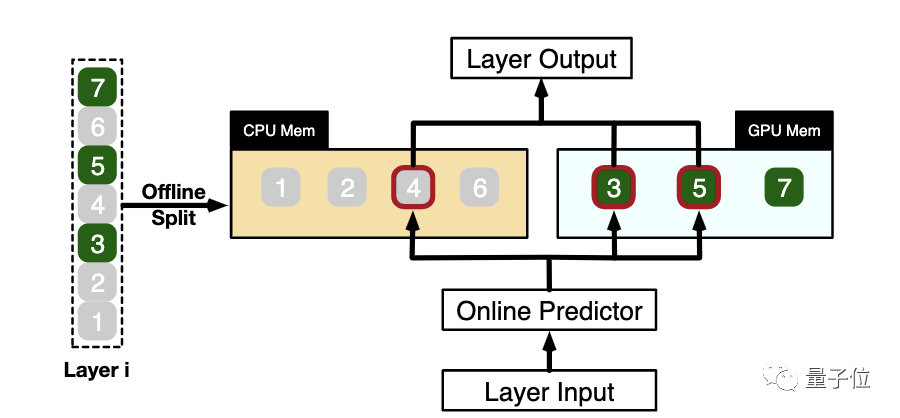
Based on the Power Law of neurons and the resulting locality, PowerInfer statically analyzes the hotness of each neuron in advance, loading a small number of hot neurons into GPU video memory and the remaining cold neurons into CPU memory.
With a neuron-level model hybrid loading, there are some neurons on the GPU and some on the CPU within a layer.
For this reason, PowerInfer designed a fine-grained CPU/GPU hybrid inference engine.
Taking the example in the following figure, for the input of a certain layer, PowerInfer first predicts that neurons 3, 4, and 5 will be activated.
Then, the CPU and GPU execute the computation of neurons stored in their respective memory based on the prediction. Specifically, in the example in the figure, the CPU computes the fourth neuron, while the GPU computes the third and fifth neurons, and then the results of both computations are efficiently merged on the GPU.
Overall Architecture of PowerInfer
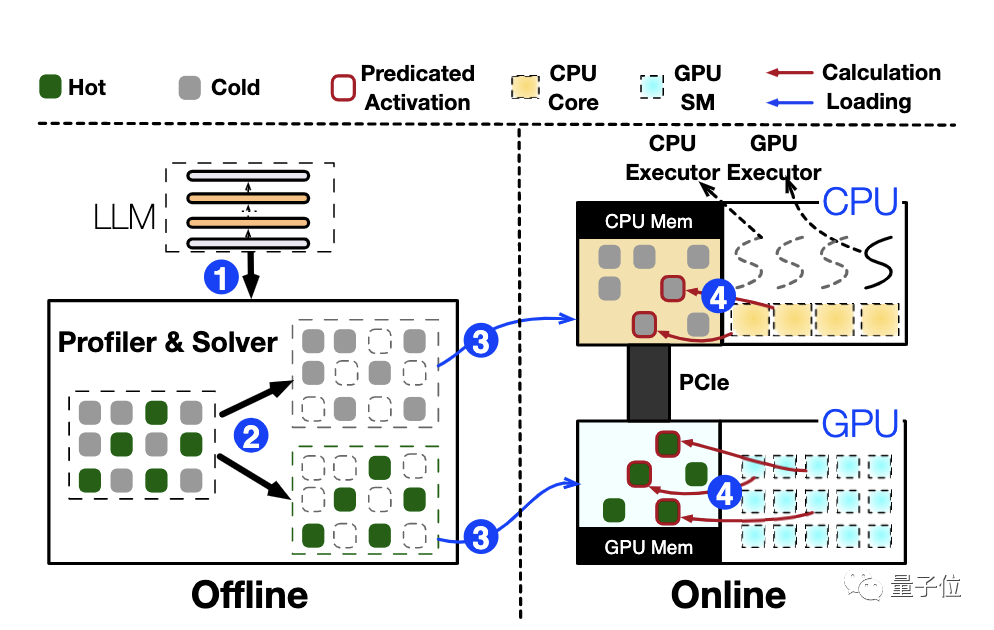
Overall, PowerInfer has developed an innovative CPU/GPU hybrid inference engine by leveraging the sparse activation based on dense models and the locality it introduces.
When integrating a large language model (LLM), PowerInfer first trains the predictive routing module of the model in the offline phase and deeply analyzes the activation characteristics of the model.
At the same time, combining critical information such as the bandwidth and capacity of the target hardware, it calculates the optimal neuron placement strategy.
Based on these calculations, PowerInfer optimally distributes neurons in memory or video memory.
In the online inference phase, the CPU and GPU handle neurons stored in their respective memory, and then efficiently merge the independently computed results on the GPU.
Conclusion and Outlook
For edge-side users, PowerInfer's efficient inference framework opens up new possibilities.
First, it allows personal computer users to run advanced large language models locally without the need for expensive specialized hardware.
This not only promotes the popularization of artificial intelligence applications but also provides unprecedented opportunities for enthusiasts, researchers, and small businesses.
In terms of cloud deployment, PowerInfer also has tremendous potential.
Existing cloud CPUs also have powerful AMX computing units, and by leveraging the heterogeneous features between CPUs and GPUs, it can be optimistically assumed that PowerInfer can achieve higher service throughput using fewer high-end computing cards.
Paper link:
https://ipads.se.sjtu.edu.cn/_media/publications/powerinfer-20231219.pdf
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








