Source: Silicon Alien

Image Source: Generated by Wujie AI
In the self-attention mechanism of the Transformer, each token is associated with all other tokens. Therefore, if we have n tokens, the computational complexity of self-attention is O(n^2). As the sequence length n increases, the required computation and storage space will grow quadratically, leading to very large computational and storage overhead.
This means that when you are no longer satisfied with feeding a large model a 200-word paragraph and want to throw a 20,000-word paper at it, its computational load increases by 10,000 times.
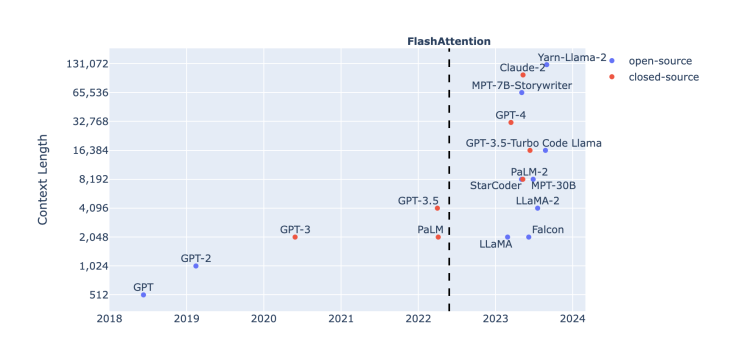
Image Source: Harm de Vries Blog
The dialogue box responsible for input and output is like a bottleneck for artificial intelligence to enter the real world. From the first time ChatGPT leaped to 4096 tokens, to GPT-4 expanding the context input length to 32k, to the MegaByte method proposed by MetaAI with several million tokens, and the length competition between the dark side of the moon and Baichuan Intelligence, with 200,000 and 350,000 Chinese characters, the appetite of the input window is becoming an important prerequisite for large models to solve practical problems.
In other words, when it can read "Dream of the Red Chamber" as carefully as solving a riddle, things will be much easier.
The breakthrough point falls on the number of tokens. Research on it has never stopped.
The Longer, the Better?
Advancing the context length is necessary. A research team from Fudan University and the University of Hong Kong demonstrated this in a paper. They conducted an evaluation benchmark called L-Eval, and under this benchmark, Claude-100k's reasoning ability in closed tasks is still weaker than that of GPT-4-32k, but in open tasks, Claude-100k, which has a longer length—meaning usually more input tokens—outperforms GPT-4-32k.
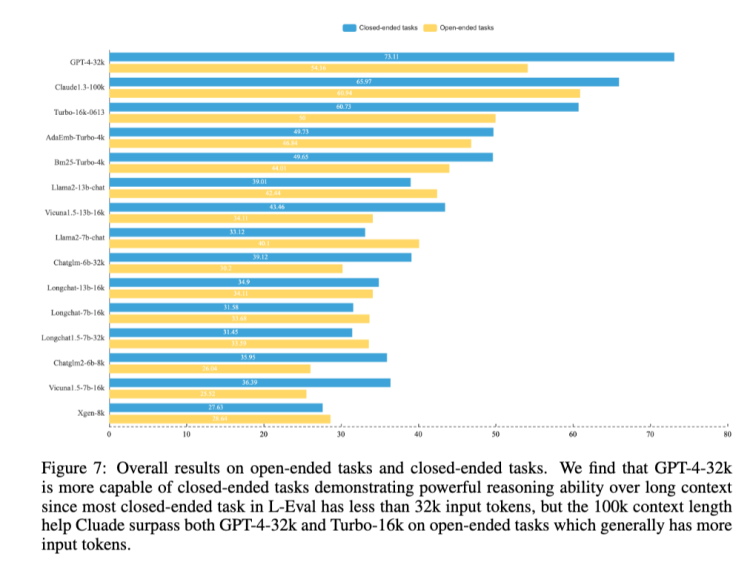
Image Source: "L-Eval: Instituting Standardized Evaluation for Long Context Language Models"
The conclusion is very positive, indicating that the story of diligence making up for clumsiness still holds true. If the brain is not good, you can give more instructions, and even a less intelligent student can succeed.
Before that, Google Brain had also conducted similar experiments. Li Wei, an engineer who has been involved in the development and training of Bard, told Silicon Alien that last year, the Google team observed the model's output performance by controlling the length of the training input context, and the result indeed showed a positive correlation between the context length and the model's performance. This understanding also helped in the subsequent development of Bard.
At least this is a very firm direction in the industry. So theoretically, wouldn't it be better to just keep extending the context length?
The problem is that expansion is not feasible, and this obstacle still lies with the Transformer.
Gradient
Based on the transformer architecture, large models also mean accepting the capabilities and limitations conferred by the self-attention mechanism. The self-attention mechanism is fond of understanding ability but naturally contradicts with long text input. The longer the text, the more difficult the training, and the worst result may be gradient explosion or disappearance.
Gradient represents the direction and magnitude of parameter updates. In an ideal training process, the gap between the large model's content generation and the human-desired response should get closer after each round of deep learning. If we imagine the model as trying to learn a linear relationship y=wx+b, where w represents the weight the model is seeking, the concept of gradient shows how w changes.
A stable learning process is gradual, meaning that adjustments are traceable. This means the weight cannot remain unchanged, nor can it change very weakly—i.e., gradient disappearance—indicating that the learning time of the deep learning network is infinitely prolonged; a sudden change is called gradient explosion, where the weight update is too large, leading to an unstable network. This may cause the weight to become very large or the model to diverge, making training impossible.
Triangle
The most fundamental issue is that short texts often cannot fully describe complex problems, and under the constraints of the attention mechanism, processing long texts requires a large amount of computing power, which also means increased costs. The context length itself determines the descriptive ability of the problem, the self-attention mechanism determines the understanding and decomposition ability of the large model, and the computing power supports all of this behind the scenes.

Image Source: ArXiv
The problem still lies with the Transformer, as the computational complexity of the self-attention mechanism restricts the extension of the context length within a triangle.
This impossible triangle is right here, and the solution is also here. Ideally, pushing the computing power (money and cards) to infinity would be the best solution for increasing the context length. Obviously, this is not practical at the moment, so the focus can only be on the attention mechanism, thereby reducing the computational complexity from n^2.
Efforts to expand the context input have largely driven an innovation in the Transformer.
The Transformation of Transformer
In July of this year, the research team at Google DeepMind proposed a new framework called Focused Transformer (FoT), which adopts a training process inspired by contrastive learning to improve the structure of the (key, value) space and allows some attention layers to access (key, value) pairs in external memory through the k-nearest neighbor (kNN) algorithm. This mechanism effectively extends the overall context length.
This is somewhat similar to another derivative of the Memorizing Transformer by Google in 2022, where the adjusted logic of the Transformer is that when encoding long texts, the model saves all previously seen tokens in a database while reading down, and when reading the current segment, it finds similar content in the database using the kNN method.
The combination of Focused Transformer and the open-source model LLaMA-3B becomes LongLLaMA-3B, and a horizontal comparison is made with LLaMA-3B in terms of the length of the context input. The result is that only after the context input length reaches 100k does the accuracy of LongLLaMA-3B's answers begin to rapidly decline from 94.5%. LLaMA-3B instantly drops to 0 after exceeding 2k.
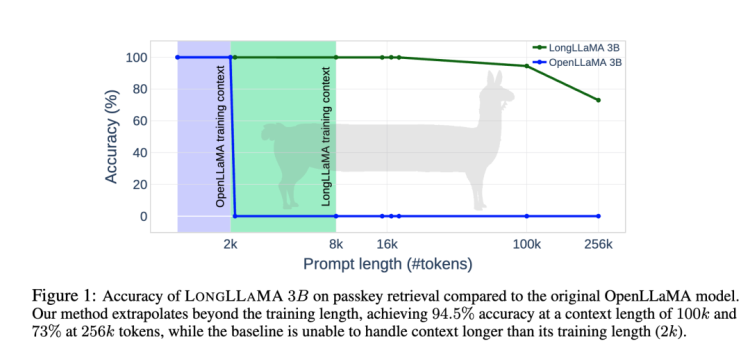
Image Source: "Focused Transformer: Contrastive Training for Context Scaling"
From the appearance of Transformer-XL in 2019, which introduced the Segment Recurrent Mechanism to provide additional context for the model, to a year later when Longformer and BigBird introduced sparse attention mechanisms, extending the length for the first time to 4096 tokens, both recurrent attention and sparse attention mechanisms began to become the direction of transformation for the Transformer.
The Focused Transformer also achieved a form of sparse attention through the kNN algorithm, and the updated architectural adjustment scheme is the Ring Attention.
In October of this year, a team from Berkeley proposed Ring Attention, which changes the Transformer framework from a memory perspective. By chunking the self-attention mechanism and the feed-forward network computation, the context sequence can be distributed across multiple devices and analyzed more efficiently. This theoretically eliminates the memory limitations imposed by a single device, allowing for the training and inference of sequences much longer than before with higher memory efficiency.
In other words, Ring Attention achieves "almost infinite context."
Lost in the Middle
However, this is not absolute. In September, Stanford published a study showing that if the context is too long, the model may skip the middle part.
They conducted controlled experiments on various open-source (MPT-30B-Instruct, LongChat-13B (16K)) and closed-source (OpenAI's GPT-3.5-Turbo and Anthropic's Claude) language models. Researchers increased the input context length by adding more documents to the input context (similar to retrieving more documents in retrieval-augmented generation tasks); and by modifying the order of the documents in the input context, placing relevant information at the beginning, middle, or end of the context, thus changing the position of relevant information in the context.
The results showed a clear U-shaped trend in model performance as the position of relevant information changed. This means that when relevant information appears at the beginning or end of the input context, the language model performs best; but when the information the model needs to access and use is in the middle of the input context, the model's performance significantly declines. For example, when the relevant information is placed in the middle of its input context, GPT3.5-Turbo's performance on multi-document problem tasks is worse than when there are no documents (i.e., a closed-book setting; 56.1%). Furthermore, the researchers also found that as the context becomes longer, the model's performance steadily declines, and models with context extensions are not necessarily better at using their own context.
Clash
Currently, the context length of mainstream large models globally, such as GPT-4 and LLaMA 2 Long, has reached 32k, while Claude 2.1 has reached 200k. In China, the context length of the large model ChatGLM-6B has reached 32k, and the latest star company, Yue Zhi An Mian, has directly presented a 200k Kimi Chat.
Yue Zhi An Mian's approach is also to transform the Transformer, but Yang Zhilin has also sparked a clash.
Tadpole model and Bee model.
In simple terms, there are many ways to create a model that can support longer context inputs, and the simplest way is to sacrifice the model's parameters.
Reducing the model's parameters means reducing memory consumption and simplifying computation. The reallocation of memory and computational resources can transform the increase in context input length under the same computational resources. Looking back, the validation of Focused Transformer was done on a small parameter model of 3B, and the experiments with Ring Attention focused more on the effectiveness validation of the proposed method, without going through large models with over a hundred billion parameters.
However, models with parameters in the range of 1 billion do not have good emergent intelligence capabilities. Yang Zhilin described it as a tadpole model because it cannot do much.
In addition, another way to increase the length is to introduce a search mechanism from the outside.
Principle of Exploration
This is currently a common method for large models to quickly extend the context length—if the internal attention mechanism is not changed, another way is to turn long texts into a collection of short texts.
For example, the common Retrieval-augmented generation (RAG). It is a deep learning framework that combines both retrieval and generation mechanisms, aiming to introduce information retrieval capabilities into sequence generation tasks, allowing the model to use an external knowledge base when generating responses or content.
When the model processes long texts, the introduced search mechanism retrieves short texts from a database to obtain a long text composed of multiple short text responses. Only the required short text segments are loaded each time, thus avoiding the problem of the model being unable to read the entire long text at once.
Yang Zhilin referred to these models as Bee models.
Traditional Transformer architectures, such as GPT, have limited input lengths, typically ranging from a few hundred to a few thousand tokens. This means that when a large amount of information or long documents need to be processed, the model may encounter difficulties. RAG can retrieve information from a large external knowledge base through its retrieval mechanism, and then only feed the most relevant segments into the original input for the generation model. This allows the model to handle a larger input length than its original input length.
The principle behind this approach is quite interesting. If recurrent attention and sparse attention are both improvements to the attention mechanism at the model structure level, then avoiding direct processing of complete long texts by retrieving relevant segments from an external database and feeding the most relevant segments into the generation model only belongs to the input level optimization.
The main purpose of this method is to quickly capture the most relevant information segments from a large number of documents, and these information segments may only represent part of the original input context or certain specific aspects. In other words, this method focuses more on local information and may not grasp the overall meaning of a long text input.
Just like modules separated from each other in a beehive.
The term "Bee model" has a somewhat playful implication, pointing to the large model vendors in the market that use external search to expand window capacity. It's hard not to think of the rapid development in recent months and the emphasis on their "search genes" by Baichuan Intelligence.
On October 30, Baichuan Intelligence released the brand new Baichuan2-192K large model. The context window length has been extended to 192K, which is equivalent to about 350,000 characters in Chinese. Yue Zhi An Mian's Kimi Chat only increased the context length of Claude-100k by 2.5 times, while Baichuan2-192K almost doubled the upper limit of Kimi Chat.
On the LongEval long-window text comprehension evaluation list, Baichuan2-192K's performance far surpasses that of Claude-100k, maintaining strong performance even with a window length exceeding 100K, while the latter's performance rapidly declines after 70k.
Not So Many Long Texts
But there is another perspective on the question of "why don't we try longer contexts."
The publicly available web-crawled dataset CommonCrawl is the main source of training data for LLaMA, including another major dataset C4 obtained from CommonCrawl, which together make up 82% of the LLaMA training dataset.
The corpus data in CommonCrawl is very short. Harm de Vries, a researcher at ServiceNow, stated in an analysis article that in this large dataset, over 95% of the corpus data files contain fewer than 2k tokens, and in fact, the majority of them are below 1k.
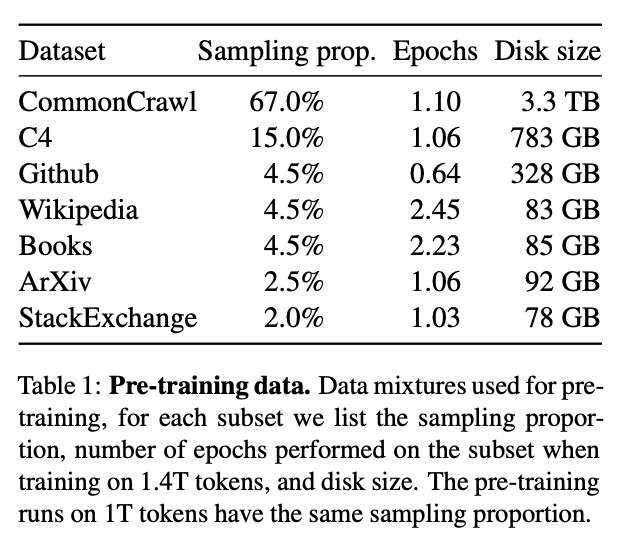
Image Source: Harm de Vries Blog
"If you want to find long texts with clear contextual logic in it, it's even rarer," said Li Wei.
Longer training data is hoped to come from sources such as books, papers, or even Wikipedia. Harm de Vries's research shows that over 50% of Wikipedia articles have more than 4k tokens, and over 75% of book tokens exceed 16k tokens. However, looking at the distribution of the main data sources for LLaMA training data, Wikipedia and books together only account for 4.5%, and papers (ArXiv) account for only 2.5%. The combined total is only 270GB of data, less than one-tenth of CommonCrawl.
Perhaps there simply aren't as many long text corpora available for training. The real challenge facing all those pursuing longer context lengths is that Transformers don't read "Dream of the Red Chamber," and there aren't as many "Dream of the Red Chamber" to read, either.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







