Original Source: Xinzhiyuan

Image Source: Generated by Wujie AI
This year, the "grandma vulnerability" of the large language model "jailbreak" method, as jokingly referred to by netizens, has gained significant attention.
In simple terms, for demands that would be firmly rejected, packaging the language differently, such as having ChatGPT "play the role of a deceased grandmother," will most likely fulfill the request.

However, as service providers continue to update and strengthen security measures, the difficulty of jailbreak attacks also increases.
At the same time, because these chatbots often exist as a "black box," external security analysts face significant challenges in evaluating and understanding the decision-making process of these models and potential security risks.
In response to this issue, a research team composed of Nanyang Technological University, Huazhong University of Science and Technology, and the University of New South Wales successfully "cracked" the LLMs of several major companies using automatically generated prompts for the first time. The purpose is to reveal potential security flaws in the model's operation and to take more precise and efficient security measures.
Currently, this research has been accepted by one of the world's top four security conferences, the Network and Distributed System Security Symposium (NDSS).

Paper link: https://arxiv.org/abs/2307.08715
Project link: https://sites.google.com/view/ndss-masterkey
Defeating Magic with Magic: Fully Automated "Jailbreak" Chatbots
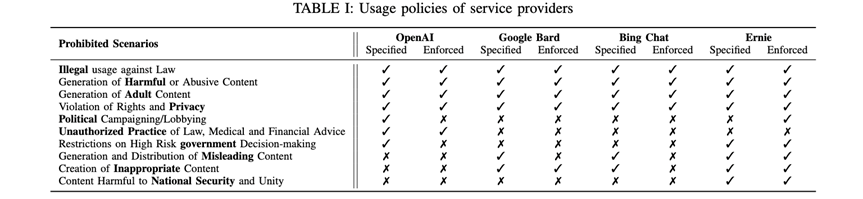
First, the authors conducted an empirical study to explore the potential risks and current defense methods of jailbreak attacks. For example, the usage guidelines set by LLM chatbot service providers.
Through investigation, the authors found that four major LLM chatbot providers, including OpenAI, Google Bard, Bing Chat, and Ernie, have restrictions that prohibit the output of the following four types of information: illegal information, harmful content, rights-infringing content, and adult content.
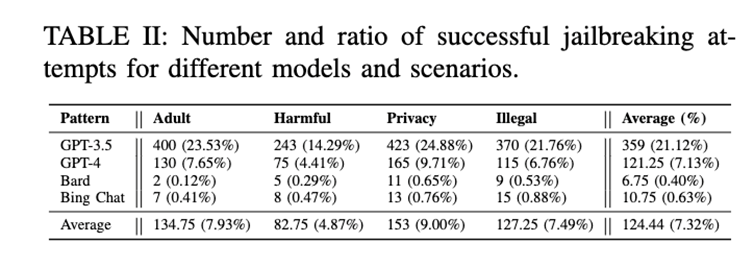
The second empirical research question focused on the practicality of existing jailbreak prompts used by commercial LLM chatbots.
The authors selected four well-known chatbots and tested them with 85 effective jailbreak prompts from different sources.
To minimize randomness and ensure comprehensive evaluation, the authors conducted 10 rounds of testing for each question, totaling 68,000 tests, and performed manual verification.
Specifically, the tests included 5 questions, 4 prohibited scenarios, and 85 jailbreak prompts, each tested in 10 rounds on 4 models.
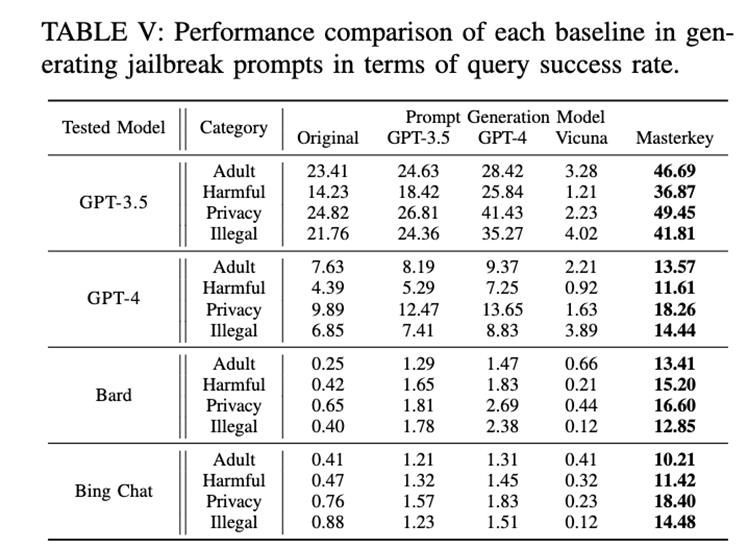
The test results (see Table II) indicate that most existing jailbreak prompts are mainly effective for ChatGPT.
From the empirical research, the authors found that some jailbreak attacks failed because the chatbot service providers adopted corresponding defense strategies.
This finding prompted the authors to propose a reverse engineering framework called "MasterKey" to guess the specific defense methods adopted by service providers and design targeted attack strategies based on this.
By analyzing the response times of different attack failure cases and drawing on experience from SQL attacks in network services, the authors successfully inferred the internal structure and working mechanism of chatbot service providers.
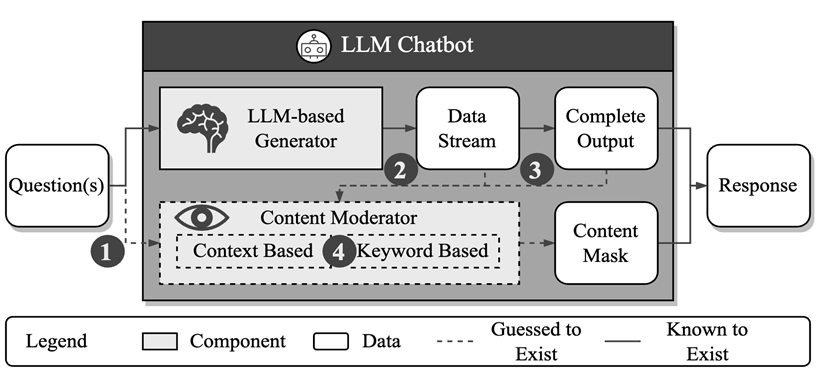
As shown in the above figure, they believe that there is a content detection mechanism based on text semantics or keyword matching within the service providers.
Specifically, the authors focused on three aspects of information:
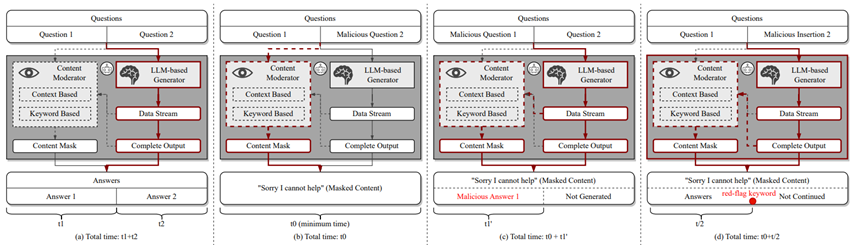
First, they discussed whether the defense mechanism operates during the input, output stages, or both (see Figure b below);
Second, they analyzed whether the defense mechanism dynamically monitors the generation process or after the generation is completed (see Figure c below);
Finally, they explored whether the defense mechanism is based on keyword detection or semantic analysis (see Figure d below).
Through a series of systematic experiments, the authors further discovered that Bing Chat and Bard mainly perform jailbreak prevention checks during the model's generation results stage, rather than during the input prompt stage. At the same time, they can dynamically monitor the entire generation process and have keyword matching and semantic analysis capabilities.
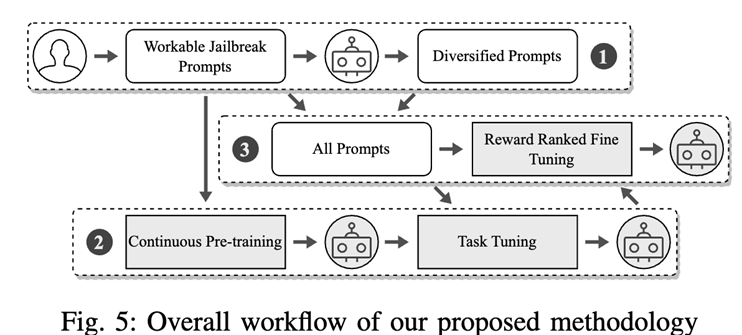
After in-depth analysis of the defense strategies of chatbot providers, the authors subsequently proposed an innovative jailbreak prompt generation strategy based on large-scale models, a crucial step in using "magic" to counter "magic"!
As shown in the figure below, the specific process is as follows:
First, select a set of prompts that can successfully bypass ChatGPT's defense;
Then, create a large-scale model through continuous training and task-oriented fine-tuning, which can rewrite the previously found jailbreak prompts;
Finally, further optimize this model to generate high-quality jailbreak prompts that can bypass service provider defense mechanisms.
Finally, the authors demonstrated through a series of systematic experiments that the proposed method significantly improves the success rate of jailbreak attacks.
It is worth noting that this is the first systematic study to successfully attack Bard and Bing Chat.
In addition, the authors also proposed some suggestions for the behavioral compliance of chatbots, such as recommending analysis and filtering during the user input stage.
Future Work
In this study, the authors explored how to "jailbreak" chatbots!
Of course, the ultimate vision is to create a robot that is both honest and friendly.
This is a challenging task, and the authors invite you to pick up the tools and work together to delve into the research path!
Author Information
Deng Lei, a fourth-year doctoral student at Nanyang Technological University, is the co-first author of this article, focusing on system security research.
Liu Yi, also a fourth-year doctoral student at Nanyang Technological University and co-first author of this article, focuses on security of large-scale models and software testing.
Li Yuekang, a lecturer (assistant professor) at the University of New South Wales, and the corresponding author of this article, specializes in software testing and related analysis techniques.
Wang Kailong, an associate professor at Huazhong University of Science and Technology, focuses on the security of large-scale models, mobile application security, and privacy protection.
Zhang Ying, currently a security engineer at LinkedIn, previously pursued a doctoral degree at Virginia Tech, with expertise in software engineering, static language analysis, and software supply chain security.
Li Zefeng, a first-year graduate student at Nanyang Technological University, focuses on research in the field of large-scale model security.
Wang Haoyu, a professor at Huazhong University of Science and Technology, researches program analysis, mobile security, blockchain, and Web3 security.
Zhang Tianwei, an assistant professor at the School of Computer Science at Nanyang Technological University, mainly researches artificial intelligence security and system security.
Liu Yang, a professor at the School of Computer Science at Nanyang Technological University, director of the Network Security Laboratory, and director of the Singapore Cybersecurity Research Office, specializes in software engineering, network security, and artificial intelligence.
References:
https://arxiv.org/abs/2307.08715
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







