Source: Quantum Bit

Image source: Generated by Wujie AI
Alibaba has open-sourced another large model!
This time it's a purely large language model, with a parameter size of 140 billion, compared to the previous 70 billion.
It's called Qwen-14B, and it has taken the top spot in a series of task lists, surpassing Meta's 340 billion parameter Llama 2 version.
Qwen-14B's training data reaches 30 trillion tokens, covering not only Chinese and English, but also a sequence length of 8192.
The usage is the same as before, completely open-source, and free to use. Currently, a demo version is available in the MoDaa community.
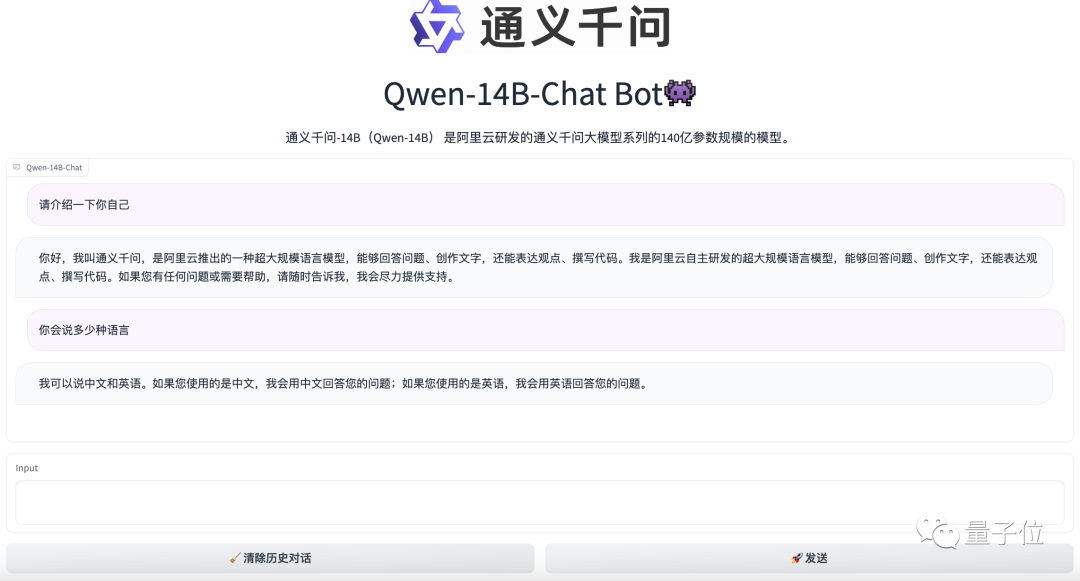
It seems that Alibaba's Qwen is somewhat aiming to compete with Meta's Llama, trying to create a complete series of "domestic large model open source".
So, how effective is Qwen-14B? Let's give it a try.
Surpassing 340 Billion Llama 2 in 10 Lists
First, let's see how Qwen-14B performs overall.
Although Llama 2 has achieved a series of "achievements", at least in the official version, it still lacks the ability to speak Chinese.
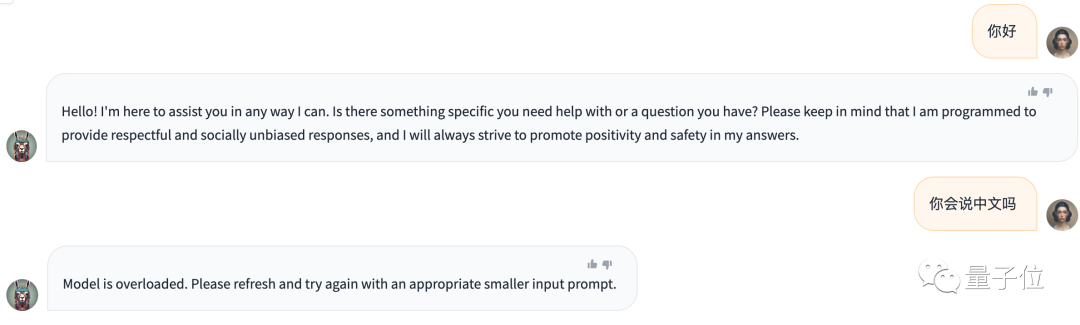
Therefore, let's first see how Qwen-14B performs in Chinese, and then try its level in other disciplines.
As usual, here's the simple benchmark:

It seems that Qwen-14B can also handle it accurately. Let's try a slightly more difficult Chinese comprehension question:

It seems pretty good, and it even corrected my language error (hand dog head).
So, how does it perform in math problems? Let's try a simple problem like the chicken and rabbit in the same cage:
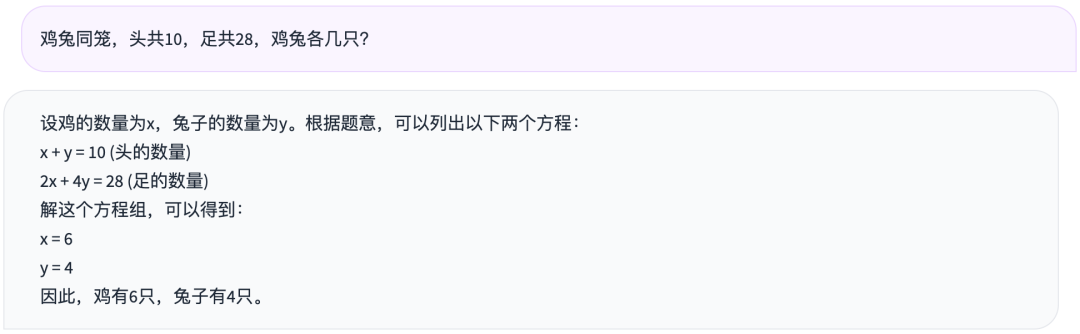
The performance is also average. Let's try a slightly more difficult logical reasoning question. It was found that 60 large models all answered it incorrectly.
The question is as follows:
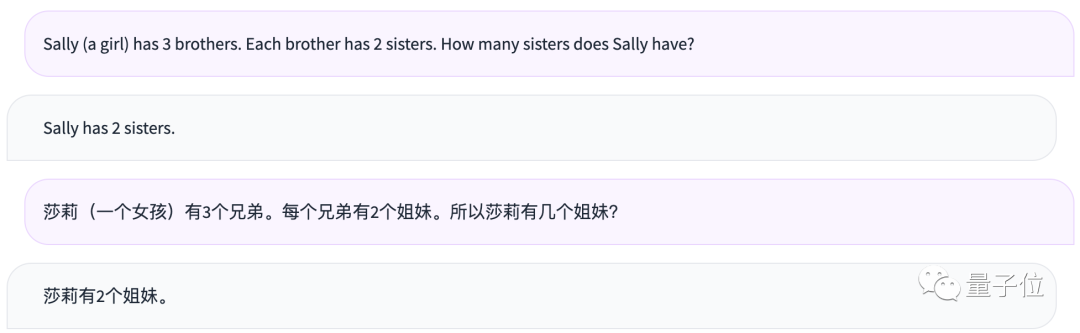
Sally (a girl) has 3 brothers. Each brother has 2 sisters. How many sisters does Sally have?
莎莉(一个女孩)有3个兄弟。每个兄弟有2个姐妹。所以莎莉有几个姐妹?
PS: The correct answer to this question is 1.
Among the series of large models that answered incorrectly are GPT-4, Claude 2, and Llama 2:

Unfortunately, Qwen-14B also did not get it right.
However, its coding ability is quite good, for example, asking it to write a code for the game Snake:
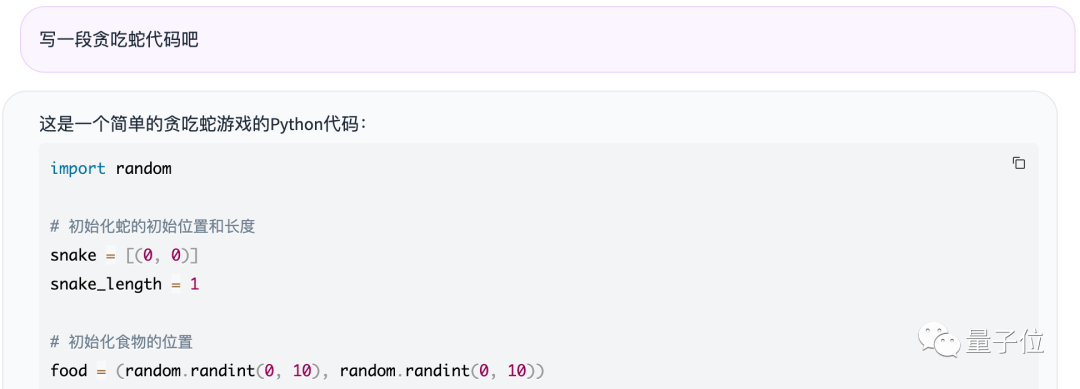
It quickly provided a complete version of the Snake code, complete with comments:
After trying it out, it can be run and played directly:
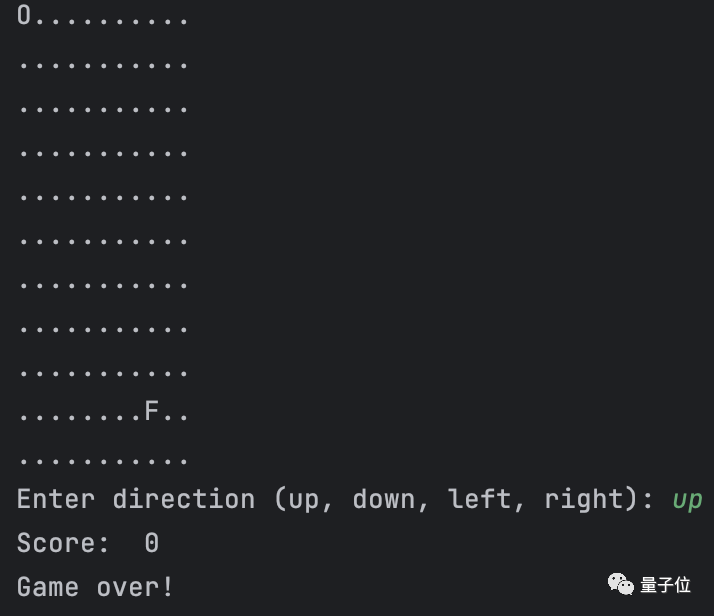
It is understood that, like Qwen-7B, Qwen-14B also possesses not only conversational capabilities.
In addition to the above abilities, Qwen-14B has also learned to call its own tools.
For example, it can execute Python code based on the Code Interpreter tool, directly perform mathematical calculations, data analysis, and data chart drawing.
The team has also upgraded Qwen-14B's skills in connecting to external systems, not only being able to call complex plugins in a few steps, but also being able to develop it as a base model for Agent and other AI systems to complete complex tasks.
In fact, behind the Qwen-14B model, it is also a little expert in ranking.
Whether it's in language ability test sets, such as the large-scale multi-task language evaluation list MMLU, and the Chinese basic ability evaluation dataset C-Eval;
Or in other disciplines such as mathematics, such as elementary school math addition, subtraction, multiplication, and division problems GSM8K, and the math competition dataset MATH:
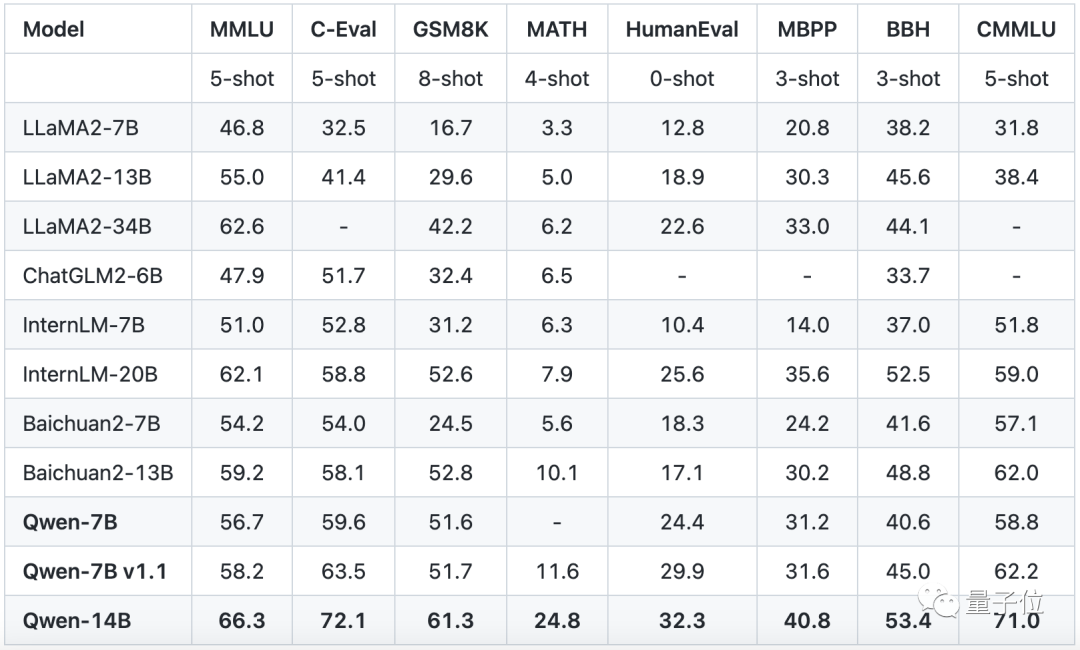
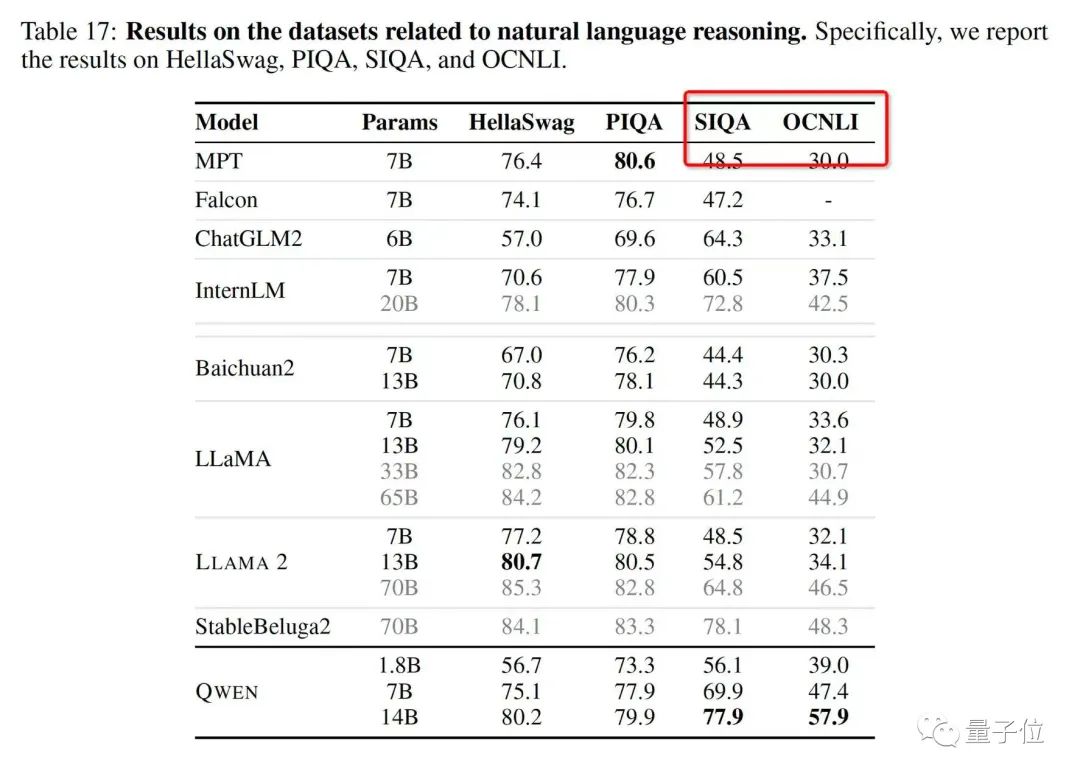
In total, it has achieved the top spot in 10 lists.
So, how was Qwen-14B created?
Training Data Exceeding 30 Trillion Tokens
For technical details, let's start with Qwen-14B's architecture and training data.
As a large model with 140 billion parameters, Qwen-14B's structural details look like this:
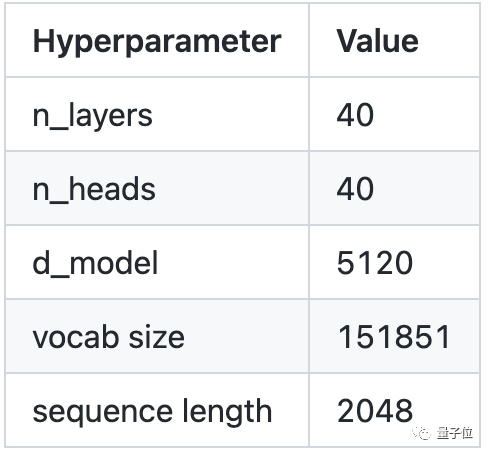
In terms of overall architecture, the team has borrowed some "magical designs" from current open-source large models, including Google's PaLM and Meta's Llama.
This includes SwiGLU's activation function design, ROPE's position encoding, and they all appear in the structural design of Qwen-14B.
Not only that, the team has also optimized the vocabulary and long sequence data modeling. The vocabulary size exceeds 150,000, saving more tokens.
For long sequence data modeling, they have adopted some of the most effective methods, including but not limited to Dynamic NTK, Log-N attention scaling, window attention, etc., to ensure a more stable model performance.
This is also the reason why the model, despite having only 140 billion parameters, can achieve a sequence length of 8192.
The good performance is also inseparable from Qwen-14B's training data.
Qwen-14B was trained on over 30 trillion tokens of data.
This includes not only basic subjects such as language, mathematics, and English, but also knowledge from multiple other subjects such as physics, chemistry, biology, politics, history, geography, as well as coding knowledge, directly receiving 9 years of compulsory education (hand dog head).
In addition, the team has done a lot of data processing work, including large-scale data deduplication, filtering out junk text, and increasing the proportion of high-quality data.
At the same time, in order to enable the model to better learn to call tools and enhance its memory, the team has optimized the fine-tuning samples and established a more comprehensive automatic evaluation benchmark to identify situations where Qwen-14B's performance is unstable, and has used the Self-Instruct method to expand high-quality fine-tuning samples.
In fact, this is already the third wave of open source for the Qwen series.
In early August, Alibaba Cloud open-sourced the general-purpose model Qwen-7B and the chat model Qwen-7B-Chat for Chinese and English.

Qwen-7B supports a context length of 8K, trained on a dataset containing over 22 trillion tokens of text, code, and other types of data, and also supports plugin calls and the development of Agent and other AI systems.
The project quickly made it to the GitHub trending list and has currently garnered 4k stars.

(Worth mentioning is that this time, in addition to releasing Qwen-14B, Alibaba Cloud also upgraded Qwen-7B.)
Then, at the end of August, Alibaba Cloud once again launched the visual language large model Qwen-VL.
Qwen-VL is developed based on Qwen-7B as the base language model, supporting multiple inputs such as images, text, detection boxes, and also supports output beyond text, such as detection boxes.

From the demo display, it can be seen that Qwen-VL has multiple capabilities, including Chinese and English conversations, code and image understanding.
For those interested in Alibaba's series of open-source large Qwen models, you can try them out on the project homepage.
Demo link:
https://modelscope.cn/studios/qwen/Qwen-14B-Chat-Demo/summary
Reference links:
[1]https://github.com/QwenLM/Qwen-7B
[2]https://github.com/QwenLM/Qwen-VL
[3]https://benchmarks.llmonitor.com/sally
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






