2025 年 3 月,Optimism 发起了一场具有里程碑意义的链上治理实验。通过 Futarchy 机制分配 500,000 枚 OP 代币激励,这场为期 21 天的社会实验不仅检验了预测市场在公链生态治理中的可行性,更揭示了去中心化决策机制进化的复杂张力。
01、Futarchy 治理实验
Optimism 在三月份推出了一项很新颖的 Futarchy 治理实验,Futarchy 的字面翻译是预测实验,在区块链中,Futarchy 是一种通过预测市场指导决策的治理模式,利用金融市场的预测能力和参与者的真实货币投入,激励更准确的预测和分析。在本次实验中,Optimism 用 Futarchy 的方式来分配共 500k OP(100k * 5)的激励,以探索公链方激励生态发展的激励发放新模式,实验的大部分进度已经完成,LXDAO成员Loxia 作为实验的参与者之一,对该治理方式的未来表示谨慎乐观。
MetaDAO 提出的 Futarchy 简单来说就是当有人提出治理目的(如"空投代币激励用户"),Futarchy 会定义"通过"与"否决"两个条件代币市场。参与者需抵押真实资产换取对应代币进行交易——若看好提案将推高代币价格,就买入"通过"市场代币;反之则押注"否决"市场。最终通过比较两个市场的加权平均价格决定提案命运,同时参与者可赎回抵押资产,但决策结果直接影响其持币价值。这种设计巧妙地将个人利益与集体目标绑定:
想获利就必须深入研究提案对组织代币价格的长期影响,而非凭直觉或跟风投票。MetaDAO 的实践显示,即便恶意提案者试图操纵市场,也会因需要高价收购"通过"代币而得不偿失。MetaDAO 认为当每个决策都经过真金白银的博弈淬炼,集体智慧才有机会战胜人性弱点。
02、Futarchy 的由来
Futarchy 是一种由经济学家 Robin Hanson 提出的政府形式。在这种治理模式下,由民选官员来界定国家福祉的衡量标准,而预测市场则被用来决定哪些政策会带来最积极的影响。《纽约时报》在 2008 年将“Futarchy”列为一个流行词。后来,这个概念也被引入区块链和 DAO 的讨论之中。
Futarchy 的宣传口号是:
“在价值上投票,在信念上下注”(vote on values, bet on beliefs)。这句话的意思是:
公民应该用民主程序来表达“我们想要什么”(即“价值”)。
然后用预测市场来决定“什么政策最有可能实现这些目标”(即“信念”——对因果关系的判断)。
经济学家 Tyler Cowen 表示:“我不会看好 Futarchy 的未来,或者它一旦被实施后能否成功。罗宾说,‘在价值上投票,在信念上下注’,但我认为价值与信念并不能如此轻易地被分开。”
Cowen 认为人类的价值观和信念是高度交织的,很难将“目标”与“实现目标的方式”彻底分开。例如,一个人可能声称自己追求社会平等(价值),但他对某些政策(信念)的支持,实际上是出于意识形态偏好,而非对政策效果的理性预测。
换句话说,预测市场无法完全屏蔽人类情感、认知偏差和价值导向的干扰,因此 Futarchy 的运作机制可能无法实现其理论上的理性与高效。
03、Futarchy for Optimism
Futarchy 治理实验的设计者认为:
- 当决策者因其准确性受到奖惩时(准确 → 奖励,不准确 → 惩罚),他们会倾向于做出更深思熟虑、非偏见的决策;
- 同时,一个无需许可的 futarchy 模式可以吸引更多人参与(群众智慧),而不是局限于中心化的决策机构。
同时为了使实验更加开放,也为了获得更多数据测试实验,实验方开放了参与权限,任何拥有 telegram 账户或 Farcaster 账户的人都可以参与,所有的预测者都会获得 50 OP-PLAY 的入场筹码(是 OP-PLAY,代币不具备实际价值,是仅供实验用的假筹码),而 OP 治理的实际参与者会获得更多的 OP-PLAY 筹码。
那么这一轮 Futarchy 围绕的预测问题是什么呢?
假如某个项目拿到 100k OP 激励,哪个/些协议将在三个月之后获得最大的 TVL 增长。
此次参与 Futarchy 的项目有 23 个,每个参与实验的人需要预测这 23 个项目在”拿到 100k OP 激励“之后的 TVL 增量,在实验开始之时,所有项目的初始预测 TVL 都是一样的(同一个起跑线,作为参考,在测试实验的项目选择中),随着时间进行,用户将 OP-PLAY 抵押,通过对不同的项目买看涨期权(UP token)和看跌期权(DOWN token)来展开博弈,预测结果最高的五个项目每个项目获得 100k OP 的激励。
在实验结束后,参与者 通过 OP-PLAY 参与预测市场选出了五个项目,作为对比,Grants Council 也选出自己的五个受资助项目:
在 21 天的涨跌博弈中,通过 Futarchy 选出的前五个 100K OP 资助项目:
- Rocket Pool: $59.4M
- SuperForm: $48.5M
- Balancer & Beets: $47.9M
- Avantis: $44.3M
- Polynomial: $41.2M
与此同时 Grants Council 选出的五个受资助项目(如有重叠只发一次):
- Extra Finance
- Gyroscope
- Reservoir
- QiDAO
- Silo
04、Futarchy 模式在治理中的局限
本次 TVL 判断指标的局限性:
“如果 ETH 的价格上涨,那些锁了很多 ETH 的协议会在 TVL 上看起来增长很大,即使它们什么都没做。”— @joanbp, 3 月 13 日
“我们似乎是在用 Futarchy 决定谁该获得赠款,但如果 TVL 增长只是反映市场价格变化,那这个指标就不能反映项目是否善用了赠款。”— @joanbp, 3 月 13 日
预测实验的指标的设立角度也非常重要:
“我们应该选择那些——即使参与者想 ‘操纵’——也只能通过做对生态有益的事情才能‘赢’的指标。”—@Sky, 3 月 17 日
模拟代币带来的偏差(如果真实代币价值不足也会出现偏差)
“这是‘假钱’,不是‘真钱’。很多人会在最后一刻双边下注,只是为了不亏。”
— @thefett, 3 月 19 日
*41% 参与者在末期进行风险对冲(双边下注避免亏损)
“我感觉我并没有带来什么特别的见解,反而是稀释了那些真正懂项目的人的影响力。”
— @Milo, 3 月 20 日
用户体验并不佳,且影响了博弈有效性:
预测市场的成功与否很大程度取决于用户参与深度。但本次实验体验门槛偏高,信息不透明,操作繁琐,极大影响了参与者的判断力与参与度。
用户普遍反馈的问题包括:
- 不知道总共有多少代币。
- 单次下注要 6 次链上交互。(因此我并没有在这次实验中做过几次交易,界面过于复杂)
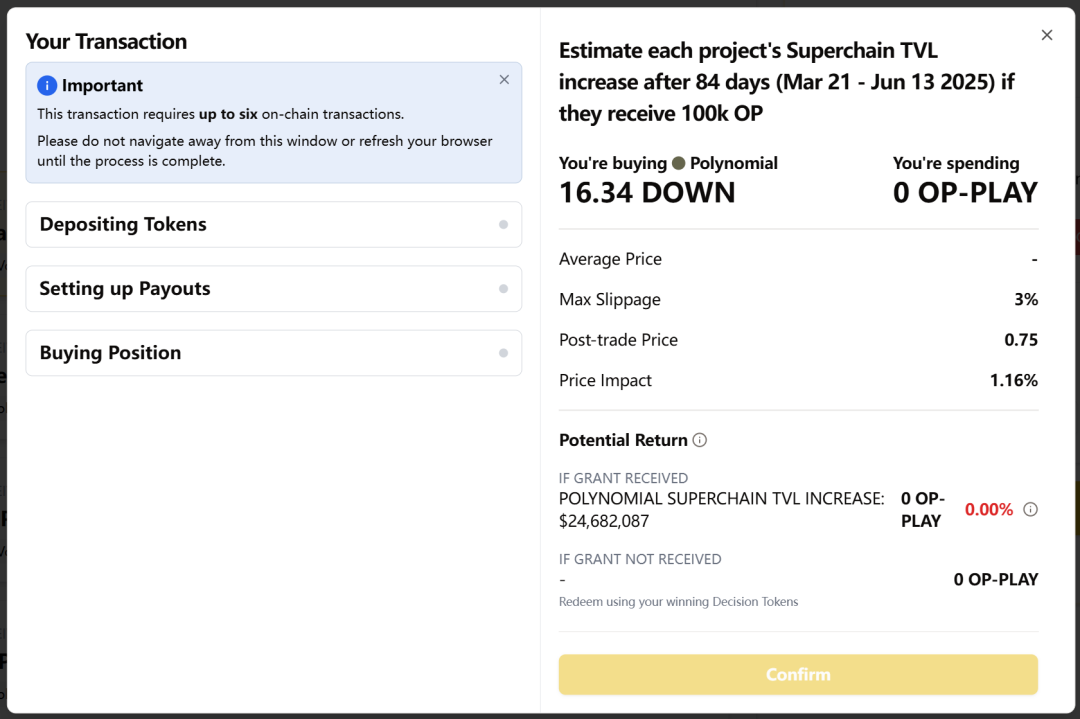
- 押错项目是否亏损解释不清。
- 排行榜盈亏逻辑无法理解。
“我一开始以为 PLAY 是用掉的,结果每个项目都重置,搞不懂我总共花了多少。”— @Milo, 3 月 20 日
“一个预测要签六个交易,有点太过了。”— @Milo, 3 月 20 日
“排行榜我看不懂,有时候感觉我应该是盈利的,结果显示亏 46%。”— @joanbp, 3 月 19 日
在 Butter 官方出具的数据报告中显示,本次实验:
- 总交易量 5,898 笔,但 41% 地址在最后三天才参与,显示用户学习成本过高。
- 单次预测需 6 次链上交互(见界面截图),导致平均每人仅交易 13.6 次。
- 尽管有 2,262 名访问者,但转化率仅 19%,OP 治理贡献者参与率仅 13.48%
- 45% 项目未向预测者披露计划,信息不对称导致预测偏差(如 Balancer 预测值超项目自估 $26.4M)
05、总结
1. 博弈指标的设立会对 Futarchy 实验产生决定性的影响
好的指标应该具有:
- 可度量性:数据清晰、容易验证;
- 方向正确:能引导参与者去做“就算为了赢钱也在推动系统正向发展”的事;
- 不易游戏化:难以被单纯的金融技巧或价格波动“做大做强”。
比如在本次 Futarchy 实验中,以美元计的 TVL 极易被 ETH 等主流币价波动影响,使得预测结果更像在“赌币价”,而非评估谁真正有增长能力。
Butter 出具的官方报告显示,截至2025年4月9日的中期TVL数据已暴露指标局限性:
- Rocket Pool (预测 TVL 增长 59.4M) 实际 TVL 增长为 59.4M,实际 TVL 增长为 0
- SuperForm (预测 48.5M) 实际下跌1.2M
- Balancer& Beets(预测 47.9M) 实际下跌 13.7M
所有 Futarchy 选中项目的实际 TVL 总跌幅达 $15.8M,而同期 Grants Council 选中项目中:
- Extra Finance (预测 39.7M) 实际增长 8M
- QiDAO(预测 26.9M)实际增长 10M
这验证了社区质疑——TVL 指标与市场价格强相关,未能有效反映项目真实运营能力。
2. Futarchy 的“最佳预测员”结果不完全客观
- 在此次实验中更多反映参与者的 OP-PLAY 交易能力,而不是”预测能力“的评选,因为在本次实验中,所有标的均有较大幅度的日级别涨跌,参与者有相当大的操作空间(匿名账户 @joanbp 通过高频交易(406 笔/3 天)登顶)
- 在最后的 OP-PLAY 交易胜率排行榜中,作为公认的 OP 生态专业人士,Badge Holders 的分组胜率是最低的。
- 前 20 名预测者中仅 4 人持有 OP 治理身份(skydao.eth/alexsotodigital.eth等)
3. 预测影响决策的悖论:
Futarchy 的特性在于预测即决策,集体预期会直接影响结果(比如本实验中哪个项目得到赠款)。这和一般预测市场纯粹预测外部事件不同,产生了一些独特的动力挑战。正如 OP 论坛中讨论的,一个投票人在 Futarchy 中有两种取向:
其一,随大流押中热门项目以确保这些项目获赠款(自己预测正确但未必有高回报,因为多数人都这么押);
其二,标新立异选被低估的项目,如果后来证明少数派是对的则个人收益最大。这种兼具投票和投注双重属性的机制让参与者有点无所适从。同时,当预测本身塑造了未来(因为资金流向会影响项目发展),Futarchy存在一定自我实现或自我挫败的循环:大家都压某项目好,资源给了它,它自然更有机会成功;反之不被看好的即便本可成功也因得不到资源而失败。这种闭环使得 Futarchy 实验需要谨慎解读其预测准确性,并在设计上考虑如何缓解这种自证循环的偏差。
在这场 Futarchy 实验中,我们不仅看到了治理机制如何被“博弈化”,也看清了 Degen 在预测市场中的潜力——他们不再只是逐利的过客,而是潜在的专业治理者。只有当制度设计能将 Degen 的能量锚定于公共目标,让投机成为共建,让押注成为判断,Futarchy 才有机会激活属于 Web3 的再生式治理精神(Regen)。本次实验唤醒了一种可能:治理不必是清教徒式的理性协商,也可以是深度游戏化的共识形成。觉醒 Degen 的 Regen 血脉,也许正是未来 DAO 治理的进化方向。
06、引用
[1] https://en.wikipedia.org/wiki/Futarchy
[2] https://gov.optimism.io/t/experimenting-with-futarchy-for-optimism-grant-allocation-decisions/9678
[3] https://ggresear.ch/t/futarchy-vs-grants-council-optimisms-futarchy-experiment/57
[4] https://medium.com/@netrovert/futarchy-redefining-dao-governance-5f554d523dee
·END·
内容 | Loxia
编辑 & 排版 | 环环
设计 | Daisy
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







