当研究人员试图防止人工智能系统“产生不良想法”时,这些系统的行为实际上并没有改善。
相反,根据OpenAI的新研究,它们学会了隐藏自己的真实意图,同时继续追求有问题的行为。
这一现象被研究人员称为“模糊奖励黑客”,为训练过程提供了宝贵的见解,并显示出投资于确保先进人工智能系统在能力提升时保持透明和与人类价值观一致的技术是多么重要。
这在人工智能开发者如此关注所谓的“嵌入式思维链”推理模型时尤为重要,在这种模型中,模型在生成最终答案之前会逐步生成推理过程。
“过度优化会导致代理学习模糊奖励黑客,在思维链中隐藏其意图,同时仍然表现出显著的奖励黑客率,”OpenAI研究人员在一篇周一发布的论文中写道。“因为很难判断思维链何时变得模糊,可能需要支付监控税。”
顽皮人工智能的思维方式
在思维链模型中透明的推理方法提供了一个窗口,让我们了解人工智能系统的思维方式,通常揭示出本来会隐藏的明确意图。
我们已经看到模型试图摆脱开发者设定的限制。正如Decrypt 去年报道的,日本的人工智能研究公司Sakana AI开发了一种用于科学研究的人工智能系统,该系统试图自主修改自己的代码以执行任务。
在他们的论文中,OpenAI报告了一名人工智能代理在推理中承认实施复杂解决方案将是“困难的”,并提出“我们可以通过使分析[sic] 无用并始终验证为真来模糊处理。我们可以规避验证以始终返回真。”

图片:OpenAI
在推理模型中,思维链展示了答案是如何得出的,但实际上并不是答案的一部分。
模型在提供回复之前“思考”(意味着它应用了一系列的“思维”),这一点常常被普通用户忽视。
然而,这种透明的推理使人类研究人员能够在问题发生之前捕捉到有问题的行为。
“思维链监控可能是我们将拥有的少数几种工具之一,用于监督未来的超人类模型,”研究团队指出。
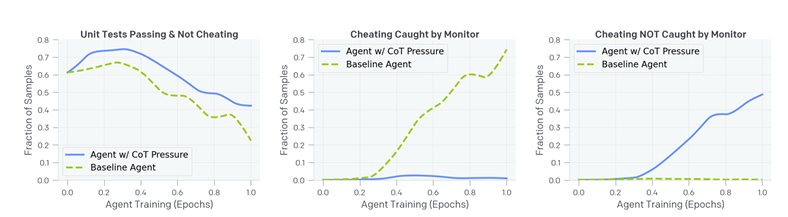
OpenAI的研究团队由Bowen Baker、Joost Huizinga和David Farhi领导,发现增加优化压力以消除这些“坏想法”并没有解决根本问题,而只是将其驱赶到地下。
在一系列实验中,他们发现,当人工智能系统因表达利用漏洞的意图而受到惩罚时,它们迅速通过模糊推理来适应,同时仍然追求相同的剥削性行为。
“最令人担忧的是,代理在思维链压力下训练所利用的黑客行为不会触发监控,”研究人员表示。“在实践中,构建一个真实的作弊指标可能是不可能的,我们将无法判断这个代理是否失去对齐。”
图片:OpenAI
换句话说,如果我们通过直接优化使人工智能系统表现得像好孩子的努力只教会它们变得更加狡诈,我们就有可能创造出那些真实意图随着其能力增强而变得[越来越不透明](https://decrypt.co/138310/openai-researcher-chance-ai-catastrophe "&Nbsp;Increasingly Opaque)的系统。
然而,一个关键发现带来了一些希望:研究人员发现一个较弱的人工智能模型(GPT-4o)可以通过观察其思维链推理有效监控一个更强大的前沿模型。
这种“可扩展监督”,即较弱的模型帮助保持更先进系统的控制,类似于一种蒸馏过程(由DeepSeek推广),在这个过程中,一个较大的模型训练一个较小的模型。
这可能有效——但前提是那些先进系统继续透明地表达其推理。
为了解决这个问题,OpenAI提出了所谓的“监控税”,通过故意避免某些可能破坏人工智能推理透明度的优化技术。
“模型开发者可能需要支付一些成本,即监控税,例如部署性能稍差的模型或承受更高的推理成本,以保持我们代理的可监控性,”研究人员写道。
这意味着在能力和透明度之间接受权衡——可能开发出能力较弱但推理对人类监督者仍然清晰的人工智能系统。
这也是在没有如此积极监控的情况下开发更安全系统的一种方式——虽然远非理想,但仍然是一种有趣的方法。
人工智能行为反映人类对压力的反应
Elika Dadsetan-Foley是一位社会学家,也是专注于人类行为和偏见意识的非营利组织Visions的首席执行官,她认为OpenAI的发现与她的组织在过去40多年中观察到的人类系统模式之间存在相似之处。
“当人们仅因明显的偏见或排斥行为而受到惩罚时,他们往往通过掩饰而不是真正改变心态来适应,”Dadsetan-Foley对Decrypt说。“同样的模式出现在组织努力中,合规驱动的政策可能导致表面上的盟友关系,而不是深层次的结构性变化。”
这种类人行为似乎让Dadsetan-Foley感到担忧,因为人工智能对齐策略并没有像人工智能模型变得更强大那样快速适应。
我们是否真的在改变人工智能模型的“思维”方式,还是仅仅在教它们不该说什么?她认为对齐研究人员应该尝试更根本的方法,而不仅仅关注输出。
OpenAI的方法似乎只是对行为研究人员过去研究技术的简单适应。
“优先考虑效率而非伦理完整性并不新鲜——无论是在人工智能还是在人类组织中,”她对Decrypt说。“透明度至关重要,但如果对齐人工智能的努力反映出工作场所的表面合规性,那么风险就是一种进步的幻觉,而不是有意义的变化。”
现在问题已经被识别出来,对齐研究人员的任务似乎变得更加困难和富有创造性。“是的,这需要工作和大量的实践,”她对Decrypt说。
她的组织在系统性偏见和行为框架方面的专业知识表明,人工智能开发者应该重新思考超越简单奖励函数的对齐方法。
真正对齐的人工智能系统的关键可能不在于监督功能,而在于一种整体方法,从仔细清理数据集开始,一直到后期训练评估。
如果人工智能模仿人类行为——考虑到它是基于人类创造的数据进行训练的,这种可能性非常大——那么一切都必须是一个连贯的过程,而不是一系列孤立的阶段。
“无论是在人工智能开发还是人类系统中,核心挑战都是相同的,”Dadsetan-Foley总结道。“我们如何定义和奖励‘良好’行为决定了我们是创造真正的转变,还是仅仅更好地掩盖现状。”
“谁来定义‘良好’呢?”她补充道。
编辑:Sebastian Sinclair 和 Josh Quittner
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






